
固定效应变截距模型PPT课件.ppt

ca****ng


1/10

2/10

3/10

4/10

5/10
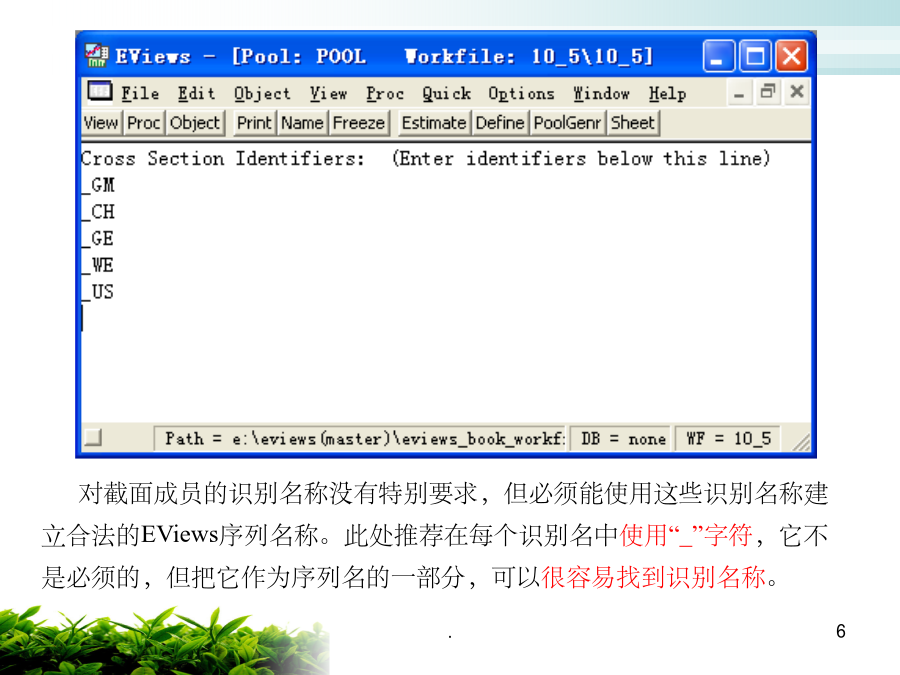
6/10

7/10

8/10

9/10

10/10
亲,该文档总共68页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

固定效应变截距模型PPT课件.ppt
第八章面板数据模型EViews对面板数据模型的估计是通过含有Pool对象的工作文件和具有面板结构的工作文件来实现的。处理时间序列/截面数据的EViews对象称为Pool。通过Pool对象可以实现对各种变截距、变系数时间序列模型的估计,但Pool对象侧重分析“窄而长”的数据,即截面成员较少,而时期较长的侧重时间序列分析的数据。对于截面成员较多,时期较少的“宽而短”的侧重截面分析的数据,一般通过具有面板结构的工作文件(Panelworkfile)进行分析。利用面板结构的工作文件可以实现变截距时间序列/截面数据

应变分析PPT课件.ppt
由以上实例可以得到以下概念:§3.1、位移和应变(二)应变及其分量对数应变的优点:对数应变的优点:体积不变条件:§3.3点的应变状态和应变张量一点的应变状态可以用过该点三个互相正交方向上的九个应变分量来表示。与应力状态相似,如果当坐标轴旋转后在新的坐标系中的九个应变分量与原坐标系中的九个应变分量之间的关系也符合学数上张量之定义,即一、主应变及应变张量不变量应变张量不变量(多用J表示)二、主切应变和最大切应变用主应变的个数和符号来表示应变状态的简图称主应变状态图。八面体线应变五、应变偏张量和应变球张量取八面

应急应变ppt课件.ppt
应变应急模块授课应急应变目录题型简介真题回顾题型区分:下列试题分别属于哪一种题型?题型分类应急应变目录测评要素考察核心答题思路例题详解应急应变目录高分策略答题提升之一:角色定位组织角色角色能力例型详解例型详解例型详解答题提升之二:对策提升主体分析法层层假设法例型详解【假设1】领导带了发言稿,只是一时找不到。解决办法:立刻在随身行李中寻找;或联系机场,看是否遗落在飞机或飞机大巴上。【假设2】领导确实没有将发言稿带到现场,但是单位里有备份。解决办法:立刻和单位(领导的秘书或办公室相关人员)联系,将发言稿备份通

应急应变ppt课件.ppt
公务员面试专项辅导我们总是希望生活在一个有序的世界里,但在真实生活中,突发事件和突发状况时有发生。目录1.如果你是秘书,和领导参加一个重要的会议,在飞机上发现重要的文件不见了,该怎么办?2.你是超市工作人员,你所在超市有个政策,一些人可以免费得到一些超市的东西。有人举报你超市存在假冒产品,而且该领物品的人没领到,这时你的领导也在场,你怎么办?3.某地发生地震事件,由你负责处理,你会如何做?情景设置:为考生设置一个事件情景突发状况:要求考生处理其中突然发生的各种问题和矛盾设问方式:你怎么办?你如何处理?1.

-效标关联效度ppt课件.ppt
主要内容学习目标:掌握效标关联效度定义、种类和应用;掌握效标与效标测量;了解效标关联效度的估计方法;一、定义、种类、应用2.分类(收集效标的时间)3.应用二、效标与效标测量2.观念效标和效标测量(conceptualcriterionandcriterionmeasurement)3.选择效标测量必须满足以下要求:4.常用的效标5.效标的特征三、效标关联效度的估计方法2.常用的估计效标关联效度的方法:小结:发生于效标测量是评定等级时效标污染(criterioncontamination)是指评定者知道被