
基于改进捕食者猎物模型和DMPC的多机器人全覆盖路径规划方法.pdf

努力****甲寅


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于改进捕食者猎物模型和DMPC的多机器人全覆盖路径规划方法.pdf
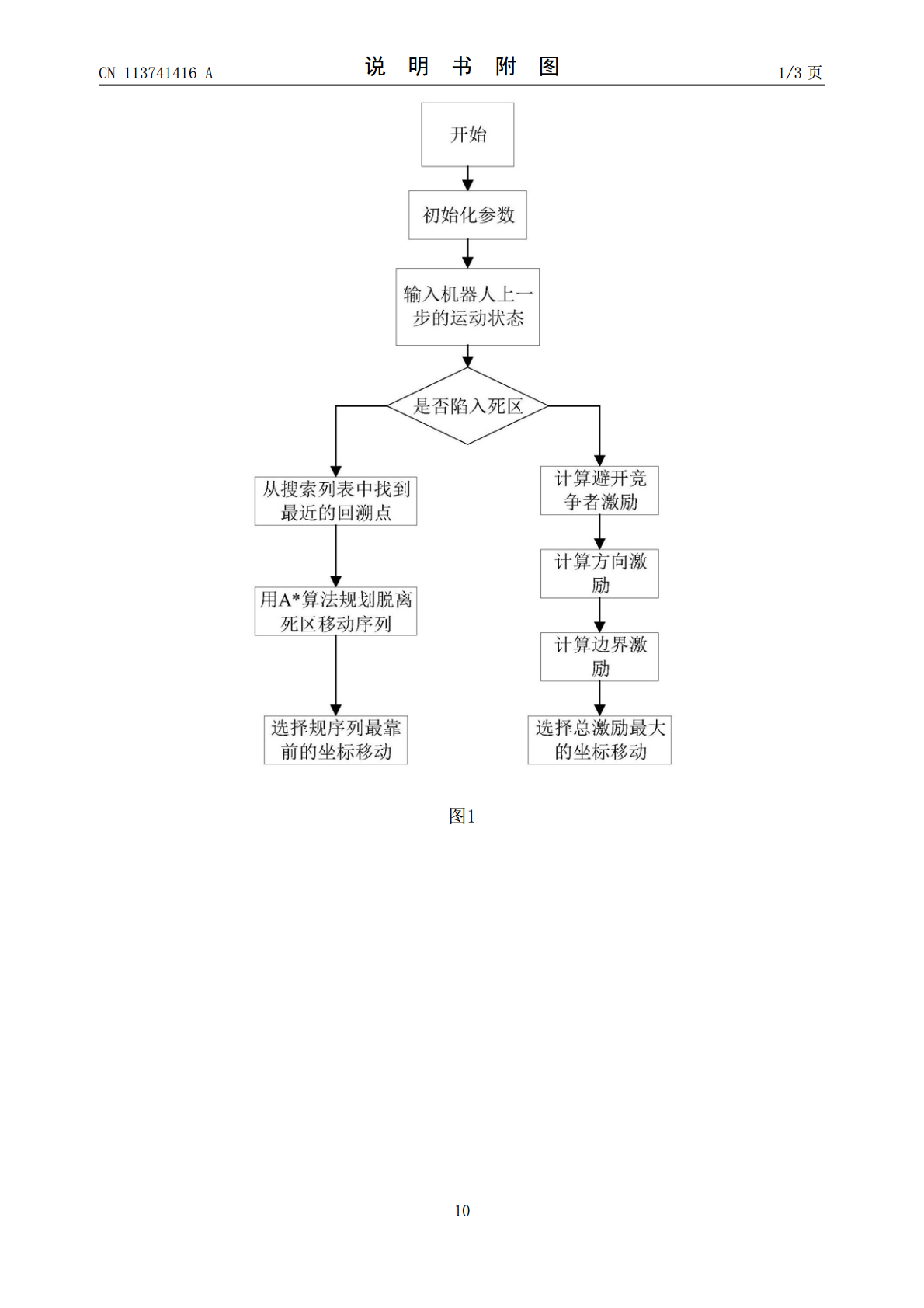
一种基于改进捕食者猎物模型和DMPC的多机器人全覆盖路径规划方法,输入地图空间,机器人位置和运动优先级等信息;对地图空间栅格化,并赋予栅格状态属性;随机生成初始参数种群和种群数量;根据周围栅格状态,确定机器人运动模型;进入死区时,利用A*回溯脱离;未进入死区,根据激励函数找到周围激励最大的栅格并移动;引入DMPC方法,根据运动模型,预测机器人的移动序列;利用WOA对参数优化求解寻找最佳的移动序列;通过不断的滚动决策,实现地图的全覆盖。本发明能够得到路径重复率低,总路径长度短的全覆盖路径。

基于改进神经网络的多AUV全覆盖路径规划.docx
基于改进神经网络的多AUV全覆盖路径规划基于改进神经网络的多AUV全覆盖路径规划摘要:多自主水下机器人(AUV)任务规划是一个复杂而具有挑战性的问题,尤其是在需要全覆盖特定区域的情况下。本论文提出了一种基于改进神经网络的多AUV全覆盖路径规划方法,该方法能够高效地解决多AUV的路径规划问题,实现全覆盖任务。首先,我们介绍了多AUV路径规划的背景和挑战,然后详细描述了我们提出的改进神经网络模型。接下来,我们提出了一种有效的路径规划算法,并通过实验验证了该算法的有效性和性能。最后,我们总结了本论文的主要贡献和

基于多安全度模型的改进RRT路径规划方法.pptx
基于多安全度模型的改进RRT路径规划方法目录添加章节标题多安全度模型介绍安全度定义安全度模型分类多安全度模型特点多安全度模型应用场景RRT路径规划方法概述RRT路径规划方法基本原理RRT路径规划方法分类RRT路径规划方法优缺点RRT路径规划方法应用领域基于多安全度模型的改进RRT路径规划方法改进RRT路径规划方法思路多安全度模型在RRT路径规划中的应用改进RRT路径规划方法实现过程改进RRT路径规划方法优势与不足实验验证与结果分析实验环境与数据集介绍实验过程与结果展示结果分析方法与指标实验结论与讨论应用前

灌溉机器人全覆盖路径规划方法.docx
灌溉机器人全覆盖路径规划方法1.内容概要介绍了灌溉机器人在现代农业中的应用背景和重要意义,以及目前国内外研究现状和存在的问题。针对现有技术在灌溉机器人路径规划方面的不足,提出了本研究的目的和意义。简要介绍了常用的路径规划算法(如Dijkstra算法、A算法等),并与本研究所使用的全覆盖路径规划方法进行了对比分析。对覆盖区域的概念、计算方法以及基于覆盖区域的路径规划方法进行了阐述。详细介绍了本研究所提出的全覆盖路径规划方法,包括以下几个关键步骤:利用已有的路径规划算法或提出新的算法,为机器人生成全覆盖的路径

基于双层模糊推理和改进DWA的多机器人路径规划.docx
基于双层模糊推理和改进DWA的多机器人路径规划摘要:多机器人路径规划是机器人协作和协同工作中的重要问题,它涉及到如何有效地规划和分配机器人的路径,以达到目标点并避免碰撞。本文提出了一种基于双层模糊推理和改进DWA的多机器人路径规划方法。该方法首先利用双层模糊推理算法进行路径规划决策,通过考虑机器人位置、速度和目标等因素,在全局层面上找到合适的路径。然后,在局部层面上,将路径规划与动态窗口方法相结合,通过改进DWA算法,在考虑机器人动态约束的基础上,进一步优化路径规划结果。实验结果表明,该方法能够有效地规划