
基于频谱压缩和神经网络的多阶段全频带语音增强方法.pdf

努力****采萍


1/10

2/10

3/10

4/10

5/10

6/10

7/10

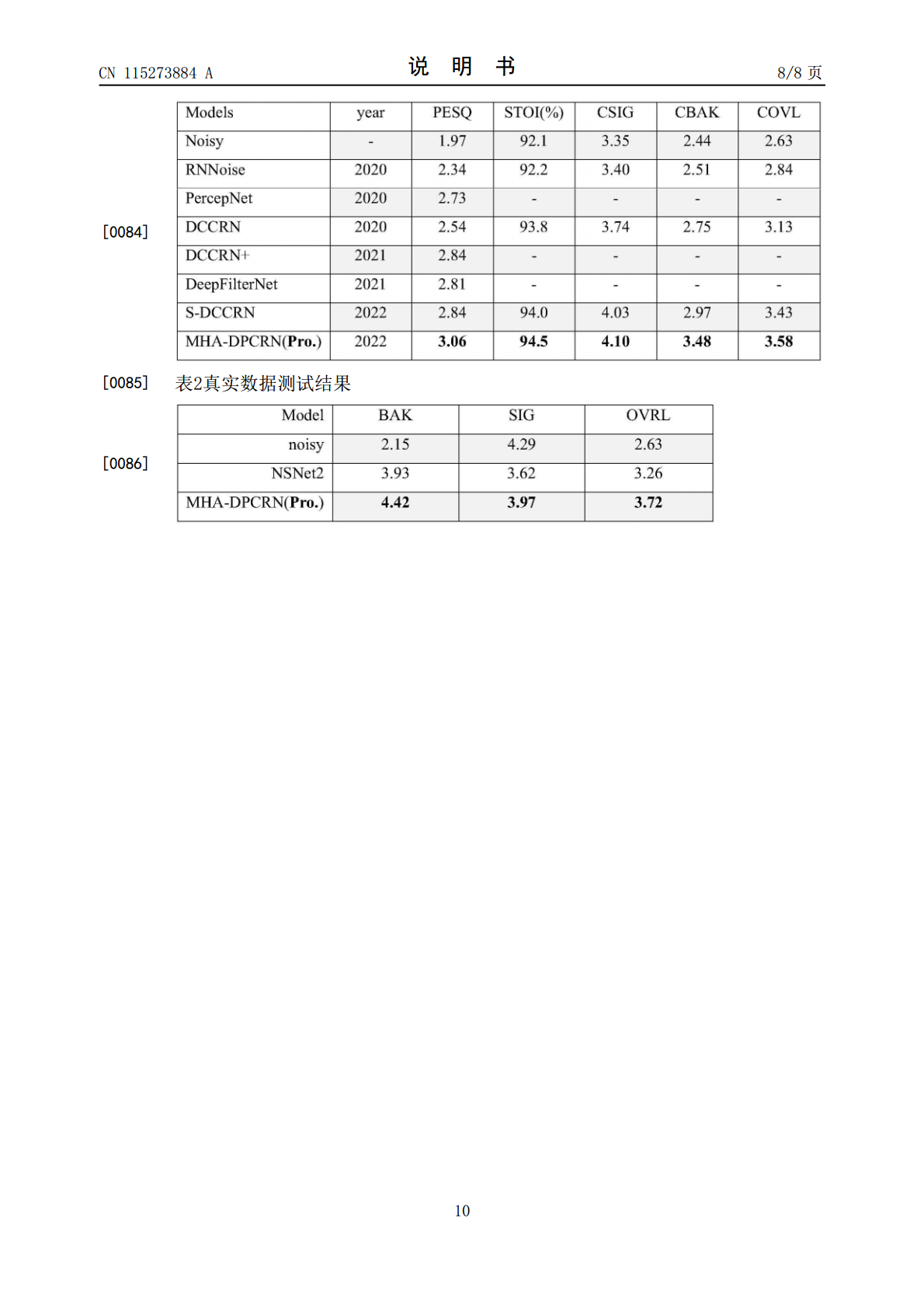
8/10

9/10
10/10
亲,该文档总共13页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于频谱压缩和神经网络的多阶段全频带语音增强方法.pdf
本发明公开了一种基于频谱压缩和神经网络的多阶段全频带语音增强方法。其步骤为:设计全频带语音频谱压缩曲线,使用设计的参数初始化MHA‑DPCRN的频谱压缩模块;合成模拟含噪混响语音;对模拟含噪混响语音和对应的带混响纯净语音分别做短时傅里叶变换得到两者的短时傅里叶谱;使用短时傅里叶谱训练MHA‑DPCRN模型权重;(5)对待增强的含噪混响语音做短时傅里叶变换得到短时傅里叶谱;将含噪混响语音的短时傅里叶谱输入完成训练的模型,得到增强语音的短时傅里叶谱,并进行逆短时傅里叶变换得到增强语音的时域信号。本发明的方法能

基于神经网络的语音频带扩展方法研究的任务书.docx
基于神经网络的语音频带扩展方法研究的任务书任务书一、研究任务随着语音合成技术的不断发展,人们对于语音质量的要求也越来越高。其中语音频带扩展技术(NarrowBandtoWideBandConversion)是提高语音质量的重要手段之一。基于神经网络的语音频带扩展方法在近年来得到了广泛的研究和应用,并且在一定程度上提高了语音质量。本研究任务旨在探究基于神经网络的语音频带扩展方法,以提高语音合成的质量。具体来说,研究任务包括以下几个方面:1.深入学习神经网络的理论和方法,特别是与语音处理相关的神经网络算法。2

基于加权语音损失的语音增强神经网络训练方法及装置.pdf
本发明公开了基于加权语音损失的语音增强神经网络训练方法及装置其中,方法包括:提取训练样本中带噪语音的对数功率谱特征;将对数功率谱特征输入初始语音增强神经网络得到预估增益;基于预估增益和噪声,计算第一损失值;基于预估增益和目标语音帧,计算第二损失值;获取第一损失值和第二损失值的权值,并进行加权计算得到最终损失值;在最终损失值收敛的情况下,将初始语音增强神经网络作为用于语音增强的神经网络。本发明实施例提供的方案,使用GRU网络来预测语音增强增益,结合语音活动检测来获取加权语音失真损失,在实现去除噪声的同时减小

基于多频带分析的语音增强研究的任务书.docx
基于多频带分析的语音增强研究的任务书题目:基于多频带分析的语音增强研究任务描述:语音增强是一种可以提高语音信号质量的技术,其应用广泛,如语音通信、语音识别等。近年来,基于多频带分析的语音增强技术备受关注,其可以更好地保留语音信号的谐波结构,减少噪声的影响。本研究旨在探究基于多频带分析的语音增强方法,并且实现一个基于该方法的语音增强算法。具体任务如下:1.调研基于多频带分析的语音增强算法的相关研究进展,总结各种算法的优缺点,并结合需要的应用场景进行选取。2.数据集的准备与处理。选择合适的数据集,并进行处理以

基于深层神经网络的语音增强方法研究的任务书.docx
基于深层神经网络的语音增强方法研究的任务书任务书:基于深层神经网络的语音增强方法研究一、研究目的语音增强技术是语音处理领域的一个热门研究方向,其目的是在降噪的基础上进一步提升音质,使人类耳朵能够更加清晰地听到语音的信息,为语音识别、智能语音交互等领域的应用提供更好的基础条件。深层神经网络技术近年来在语音处理领域中得到了广泛应用,因此我们将该技术运用于语音增强领域的研究中,设计出更加高效、更加精确的语音增强方法,从而为语音识别等应用提供更高的性能保障。二、研究内容1.综述深层神经网络在语音处理中的应用,了解