
基于加权语音损失的语音增强神经网络训练方法及装置.pdf

是你****深呀


1/10

2/10

3/10

4/10

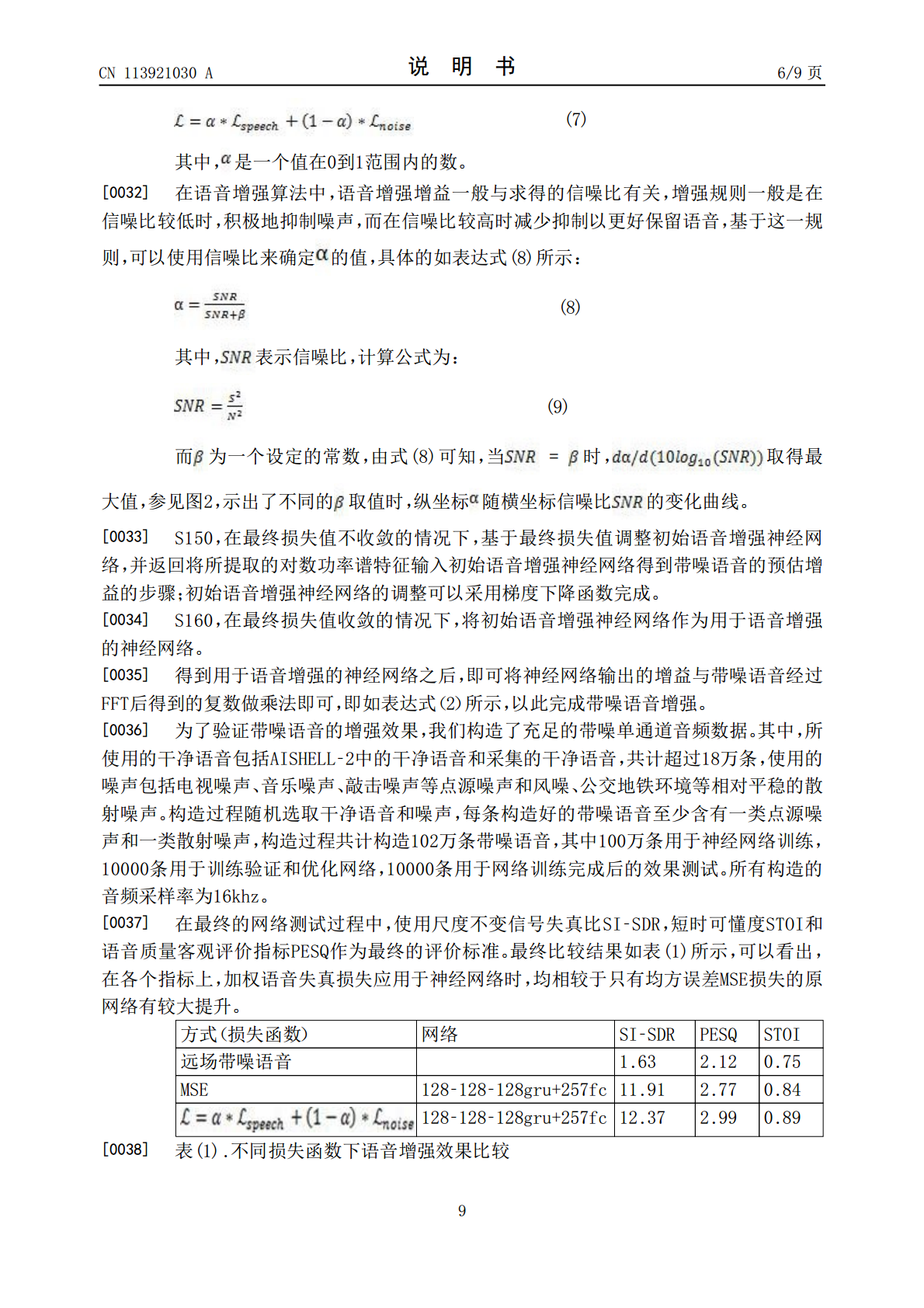
5/10

6/10

7/10

8/10
9/10

10/10
亲,该文档总共16页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于加权语音损失的语音增强神经网络训练方法及装置.pdf
本发明公开了基于加权语音损失的语音增强神经网络训练方法及装置其中,方法包括:提取训练样本中带噪语音的对数功率谱特征;将对数功率谱特征输入初始语音增强神经网络得到预估增益;基于预估增益和噪声,计算第一损失值;基于预估增益和目标语音帧,计算第二损失值;获取第一损失值和第二损失值的权值,并进行加权计算得到最终损失值;在最终损失值收敛的情况下,将初始语音增强神经网络作为用于语音增强的神经网络。本发明实施例提供的方案,使用GRU网络来预测语音增强增益,结合语音活动检测来获取加权语音失真损失,在实现去除噪声的同时减小

语音增强模型的训练方法和装置及语音增强方法和装置.pdf
本申请涉及语音处理技术领域,提供了一种语音增强模型的训练方法和装置及语音增强方法和装置。所述语音增强模型的训练方法包括:获取语音训练集;其中,语音训练集中包括含噪语音样本和纯净语音样本;获取含噪语音样本对应的幅度谱输入生成网络,获取增强语音幅度谱;获取纯净语音样本对应的幅度谱和增强语音幅度谱输入判别网络,获取判别结果;根据增强语音幅度谱、纯净语音样本对应的幅度谱、判别结果与优化目标调整生成网络和判别网络的网络参数,生成语音增强模型。采用本方法能够提高语音增强模型的性能,进而提升语音增强的效果。

基于AD神经网络的语音增强的综述报告.docx
基于AD神经网络的语音增强的综述报告语音增强是指通过去除噪声、提高语音信号质量等手段,使得语音信号更加清晰、易于识别的技术。近年来,人们越来越意识到语音增强在智能语音交互、语音识别、听力辅助等领域的重要性。其中,基于AD神经网络的语音增强技术受到了广泛关注。一、AD神经网络介绍AD神经网络,即AutoencoderDenoiser,是指通过一个自编码器将原始语音信号输入,并输出清晰、无噪声的修复语音信号。它通过深度学习来进行语音增强,能够有效地降低语音噪声以提高语音质量。在AD网络中,自编码器主要由编码器

基于神经网络的语音增强方法、装置及电子设备.pdf
本公开提供一种基于神经网络的语音增强方法、装置、存储介质及电子设备;涉及语音信号处理领域。所述方法包括:将原始语音信号进行时频变换得到原始语音信号的原始幅度谱;利用时间维卷积核对原始幅度谱进行特征提取,得到时域平滑特征图;利用频率维卷积核对原始幅度谱进行特征提取,得到频域平滑特征图;对原始幅度谱、时域平滑特征图和频域平滑特征图进行组合特征提取,得到原始语音信号的增强幅度谱;对增强幅度谱进行时频逆变换得到增强语音信号。本公开通过对原始语音信号提取时频平滑特征,可以在时间轴和频率轴上实现双轴降噪,并结合深度神

语音识别、基于语音的联合处理模型训练方法、装置.pdf
本公开提供的语音识别方法,可以根据语音识别结果为目标对象进行属性识别,后续可以基于目标对象的分类结果进行个性化服务配置,在机器人与用户的语音交流中,准确的通过语音信号来确定用户的身份,对于更人性化的人机交互有着重要的作用。同样,如果能够获取到用户的个性信息也非常重要,机器人相应就可以做出有针对性的回答或者建议。本公开提供的方法适用于任何需要进行人机语音交互的场景,可以为交互中提供更多有用的信息,使得交互更智能。本公开还提供了基于语音的联合处理模型的训练方法、装置、计算机设备、计算机可读存储介质以及计算机程