
一种考虑海浪遭遇角度的水面无人艇智能航迹控制方法.pdf

睿达****的的


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种考虑海浪遭遇角度的水面无人艇智能航迹控制方法.pdf
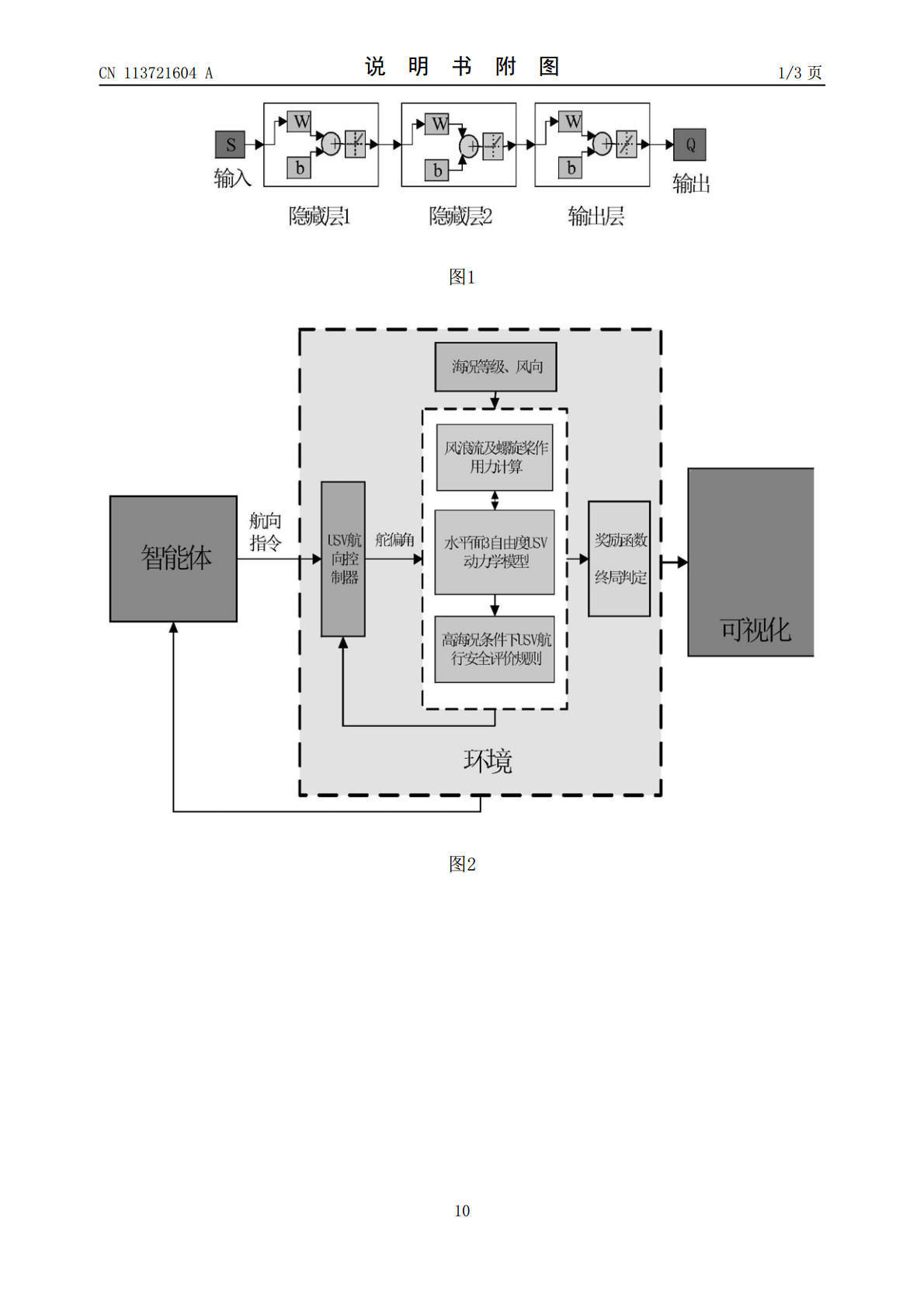
本发明提出一种考虑海浪遭遇角度的水面无人艇智能航迹控制方法,在水面无人艇USV模拟器中加入安全评价规则;设计基于DQN的智能操船策略;设计USV的动作空间、状态空间;设计深度Q网络,设计USV的奖励函数及行为策略;在模拟器中训练USV以学习到操船策略;训练完毕后,在模拟器或者实船上应用训练好的操船策略;本发明用于水面无人艇的自动驾驶领域,可以大浪条件下自动执行z字操船策略,调整船体与海浪的遭遇角度,减小船体摇摆幅度,避免船体摇摆幅度过大引发危险,确保水面无人艇能够安全航行到达目标点。

水面无人艇航向控制装置及控制方法.pdf
水面无人艇航向控制装置及控制方法。水面无人艇的航向控制通常是利用专门的舵装置或者喷水转向装置来实现的,机动性能不强,舵装置或者喷水转向装置难以有效实现无人艇在较短时间和较小范围内实现大幅度转向,舵向精准性差。本发明组成包括:甲板(4),甲板上部固定有主固定盘(3)和副固定盘(7),主固定盘下部设置有主转盘(5),主固定盘下表面具有一圈360个主红外接收开关(1),主转盘上表面固定有主红外发射开关(6),副固定盘下部设置副转盘(10),副固定盘下表面具有一圈360个副红外接收开关(8),副转盘上表面固定有副

一种水面无人艇航向控制系统及方法.pdf
本发明涉及无人控制方法领域,具体是一种水面无人艇航向控制系统及方法,控制系统包括上位机、传输电台和下位机,控制方法包括设定步骤:在上位机操作台的人机交互界面中输入期望航向,并通过传输电台,传送至下位机;信息采集与传输步骤:将下位机采集的无人艇综合信息经由传输电台传输至上位机中;控制步骤:上位机根据接收到的无人艇综合信息进行计算和处理,输出舵角δ,并传递至下位机,通过航向控制装置自动改变舵向,以调整无人艇航向;本发明具有机动性高、鲁棒性强的特点,同时采用步进电机和圆锥齿轮驱动转向的航向控制装置,控制精度更高

一种考虑海浪干扰的无人艇回收分布式决策仿真系统.pdf
本发明公开了一种考虑海浪干扰的无人艇回收分布式决策仿真系统,完成海洋作业中母船对无人艇的自动回收任务。首先,搭建无人艇回收任务所需的仿真环境;基于DuelingNetwork算法设计决策模块,并针对应用场景优化神经网络结构,使决策模块具有短时记忆功能;实现分布式通信机制,将决策模块置于服务器端,环境模块置于客户端;最后,启动服务器与客户端程序,控制无人艇抽象的智能体完成回收任务。该系统针对实际复杂海况,设计模拟物理交互的仿真环境;采用深度强化学习算法,使得AI控制器应对复杂场景时,具有更强的鲁棒性,且让模

一种无人水面艇收放无人潜航器装置.pdf
本发明公开了一种无人水面艇收放无人潜航器装置,涉及无人艇应用技术领域,包括:龙门架、第一液压推杆、第一驱动装置、第一传动装置、第二液压推杆、第二驱动装置、第二传动装置、基板、激光测距仪、控制器和夹持机构;龙门架的两端与第一固定铰支铰接;第一液压推杆与第二固定铰支铰接,第一液压推杆与第三固定铰支铰接;第一驱动装置与第二液压推杆连接,第二驱动装置与基板连接,激光测距仪固定设置在基板上,夹持机构用于夹持无人潜航器;控制器与第一驱动装置、第一液压推杆、第二驱动装置、第二液压推杆、激光测距仪和夹持机构电连接,克服了