
基于深度强化学习的巡天望远镜实时路径规划方法.pdf

小代****回来


1/9

2/9

3/9

4/9

5/9

6/9

7/9

8/9
9/9
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于深度强化学习的巡天望远镜实时路径规划方法.pdf
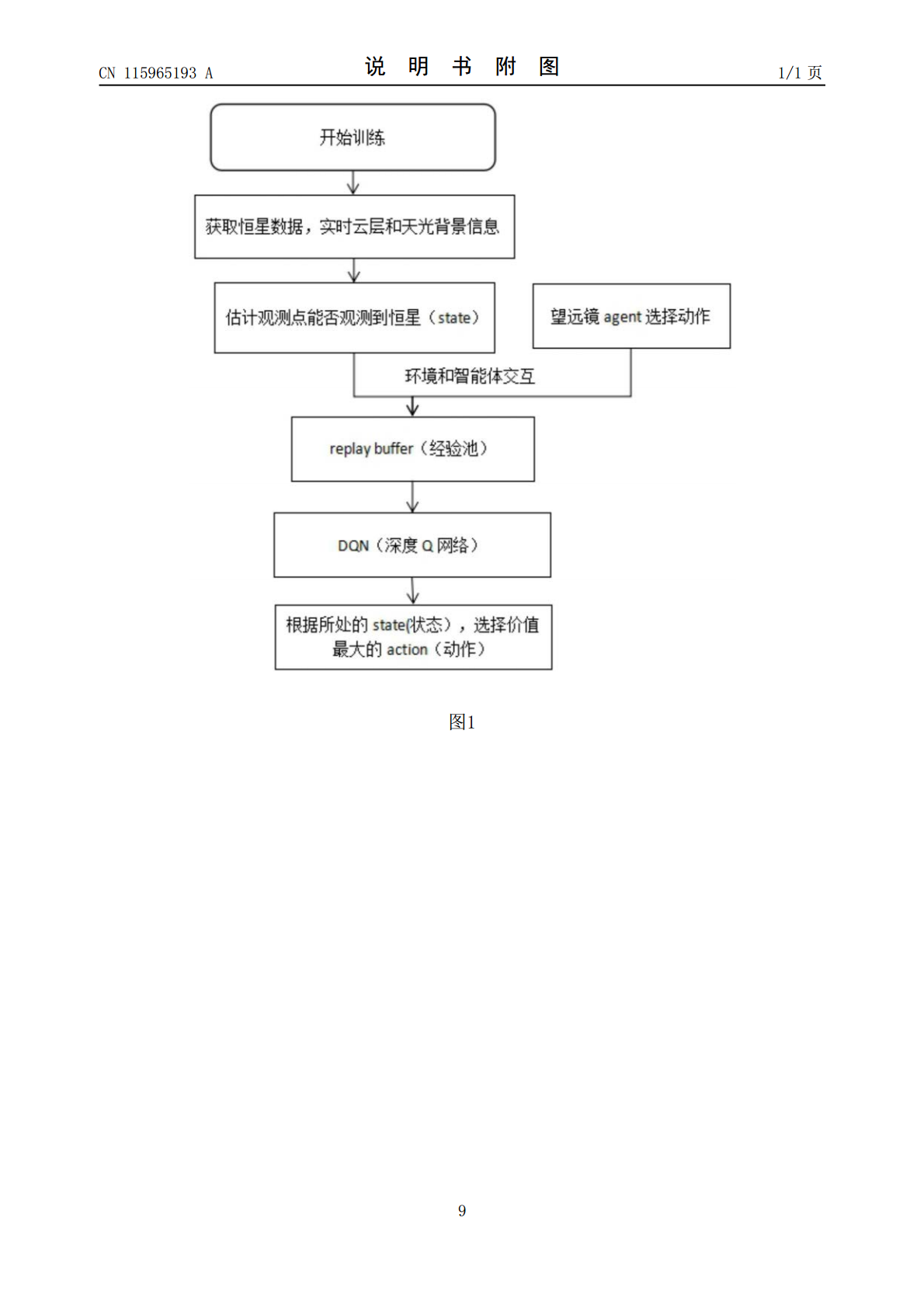
本发明涉及巡天望远镜智能控制,使用望远镜进行天文观测,潜在观测的质量随着时间而变化,时域调查需要复杂的观测序列,使未来的观测取决于过去的观测发生的时间,而云层和天光背景的实时变化则变得更加复杂,本发明提供一种基于深度强化学习的巡天望远镜实时路径规划方法,在构建的恒星观测的环境模型中,控制望远镜的智能体,根据云层、天光背景测控信息、需要规避的目标和观测计划确定望远镜的观测动作,本发明利用全天相机捕捉望远镜所在位置的全天实时图片,降低天空中的云层和天光背景对观测效果的影响,本发明能够实时地根据观测恒星的顺序、

基于深度强化学习的双目标路径规划方法.pdf
本发明涉及路径规划技术领域,具体涉及基于深度强化学习的双目标路径规划方法,包括以下步骤:S1、对道路网络进行状态表示,并构建奖励函数r,得到待训练的双目标深度强化学习路径规划模型;所述状态包括坐标状态、距离状态和cu状态;S2、对待训练的双目标路径规划模型进行训练,使其学习到能够获得最大累积奖励的最优策略π

基于深度强化学习的路径规划方法研究的开题报告.docx
基于深度强化学习的路径规划方法研究的开题报告一、选题背景及意义路径规划在计算机视觉和自主机器人等领域中已经成为一项关键技术。在真实环境中,自主机器人需要实时地进行路径规划来避免障碍物和到达目标位置。然而,仅仅考虑静态环境的路径规划算法无法适应动态环境,如行人和车辆的运动。因此,深度强化学习已经被应用于路径规划中,因其能够在动态环境下自适应地学习最优路径规划策略。本研究旨在通过深度强化学习技术,改进路径规划算法,实现在动态环境下自适应学习路径规划策略,提高自主机器人的导航能力。二、研究内容(一)研究目标基于

一种基于深度学习的减材制造实时刀具路径规划方法.pdf
本发明提供了一种基于深度学习的减材制造实时刀具路径规划方法,用于刀具路径规划,包括:预获取B样条曲面与刀具路径关系;构建B样条重参数化网络;以所述B样条曲面与刀具路径关系作为训练样本,对所述B样条重参数化网络进行训练,并将具有不同权重的损失项,组合为最终损失;基于所述最终损失训练所述B样条重参数化网络,得到刀具路径生成网络;将B样条曲面输入所述刀具路径生成网络,输出重新参数化推断;基于所述重新参数化推断重建刀具路径。本发明采用神经网络根据残高约束对工件表面进行重新参数化;得到的等参数线可以直接作为满足残高

基于深度强化学习的无人车充电路径规划方法.pdf
本发明设计了一种利用深度强化学习模型GraphAttentionbasedPointerNetwork(GAPN)为无线传感器网络中的无人车向传感器节点进行充电的路径规划方法。流程包括如下步骤:(1)收集无线传感网络中每个节点<base:Imagehe=@17@wi=@15@file=@DEST_PATH_IMAGE002.JPG@imgContent=@drawing@imgFormat=@JPEG@orientation=@portrait@inline=@yes@/>的位置坐标信息<base:Ima