
贝叶斯信念网络.pptx

胜利****实阿


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
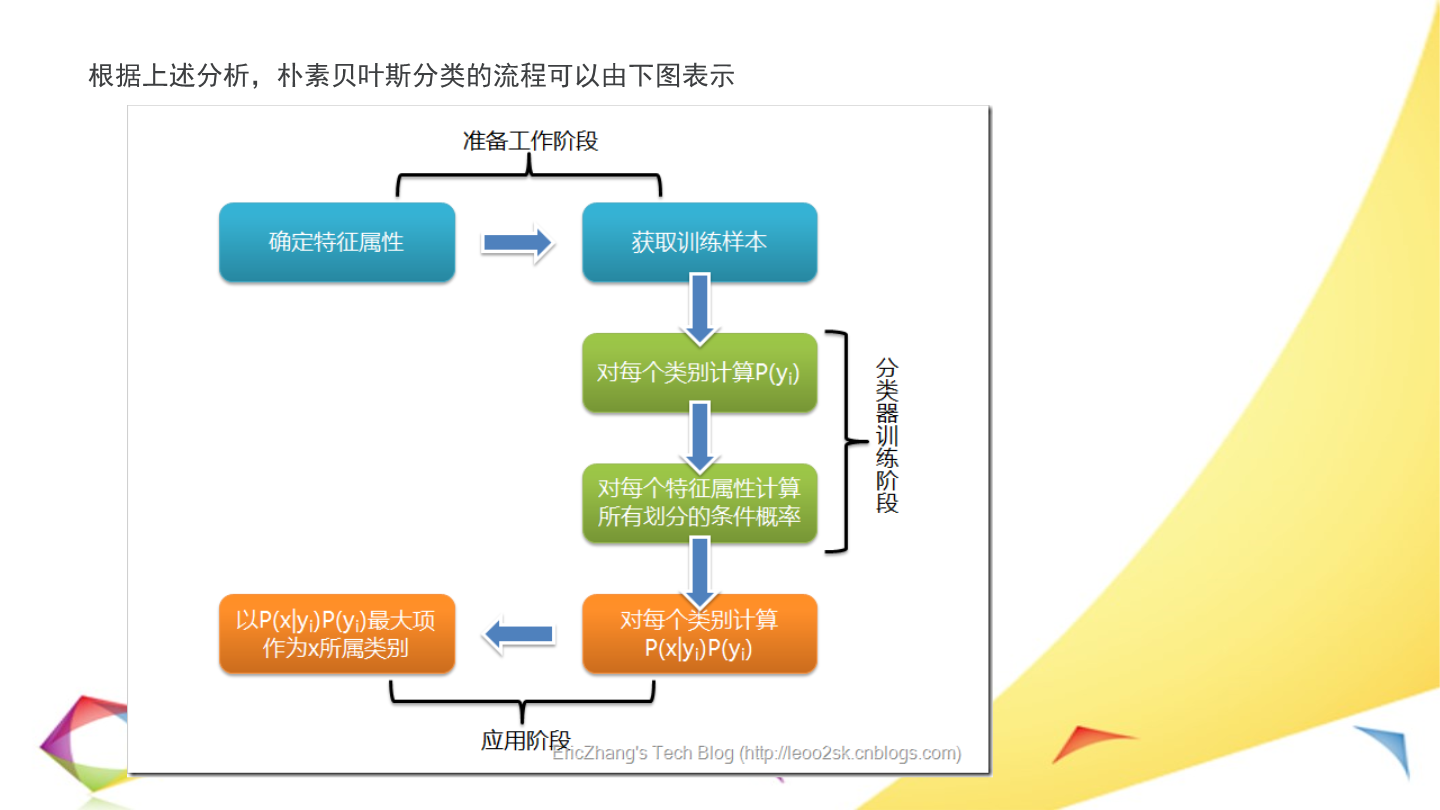
9/10

10/10
亲,该文档总共22页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

贝叶斯信念网络.pptx
贝叶斯信念网络朴素贝叶斯分类(NaiveBayesianClassification)贝叶斯信念网络(BayesianBliefNetworks)一.摘要贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。这里首先介绍分类问题,对分类问题进行一个正式的定义。然后,介绍贝叶斯分类算法的基础——贝叶斯定理。最后,通过实例讨论贝叶斯分类中最简单的一种:朴素贝叶斯分类。二.分类问题综述对于分类问题,其实谁都不会陌生,说我们每个人每天都在执行分类操作一点都不夸张,只是我们没有意识到罢了

贝叶斯信念网络.ppt
贝叶斯信念网络朴素贝叶斯分类(NaiveBayesianClassification)贝叶斯信念网络(BayesianBliefNetworks)一.摘要贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。这里首先介绍分类问题,对分类问题进行一个正式的定义。然后,介绍贝叶斯分类算法的基础——贝叶斯定理。最后,通过实例讨论贝叶斯分类中最简单的一种:朴素贝叶斯分类。二.分类问题综述对于分类问题,其实谁都不会陌生,说我们每个人每天都在执行分类操作一点都不夸张,只是我们没有意识到罢了

贝叶斯信念网络资料.ppt
六、贝叶斯信念网络2024/6/272024/6/27例如,得肺癌受其家族肺癌史的影响,也受是否吸烟的影响。贝叶斯网络模型概率表的建立一个简单的例子2024/6/27现在,假设我们想把喷水器(S)作为草地变湿的另一个原因,如下图所示。2024/6/27给定草地是湿的,我们能够计算喷水器开着的概率。这是一个诊断推理。知道草是湿的增加了喷水器开着的可能。现在让我们假设下过雨,我们有:注意,这个值比小。这叫作解释远离explainingaway;给定已知下过雨,则喷水器导致湿草地的可能性降低了。已知草地是湿的,

贝叶斯网络.doc
贝叶斯网络贝叶斯网络贝叶斯网络摘要常用的数据挖掘方法有很多,贝叶斯网络方法在数据挖掘中的应用是当前研究的热点问题,具有广阔的应用前景.数据挖掘的主要任务就是对数据进行分析处理,从而获得其中隐含的、实现未知的而又有用的知识.他的最终目的就是发现隐藏在数据内部的规律和数据之间的特征,从而服务于管理和决策.贝叶斯网络作为在上个世纪末提出的一种崭新的数据处理工具,在进行不确定性推理和知识表示等方面已经表现出来它的独到之处,特别是当它与统计方法结合使用时,显示出许多关于数据处理优势.本文致力于贝叶斯网络在数据挖掘中

贝叶斯网络.doc
贝叶斯网络贝叶斯网络贝叶斯网络摘要常用的数据挖掘方法有很多,贝叶斯网络方法在数据挖掘中的应用是当前研究的热点问题,具有广阔的应用前景.数据挖掘的主要任务就是对数据进行分析处理,从而获得其中隐含的、实现未知的而又有用的知识.他的最终目的就是发现隐藏在数据内部的规律和数据之间的特征,从而服务于管理和决策.贝叶斯网络作为在上个世纪末提出的一种崭新的数据处理工具,在进行不确定性推理和知识表示等方面已经表现出来它的独到之处,特别是当它与统计方法结合使用时,显示出许多关于数据处理优势.本文致力于贝叶斯网络在数据挖掘中