
语音识别方法、装置及计算机可读存储介质.pdf

绮兰****文章


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

语音识别方法、装置及计算机可读存储介质.pdf
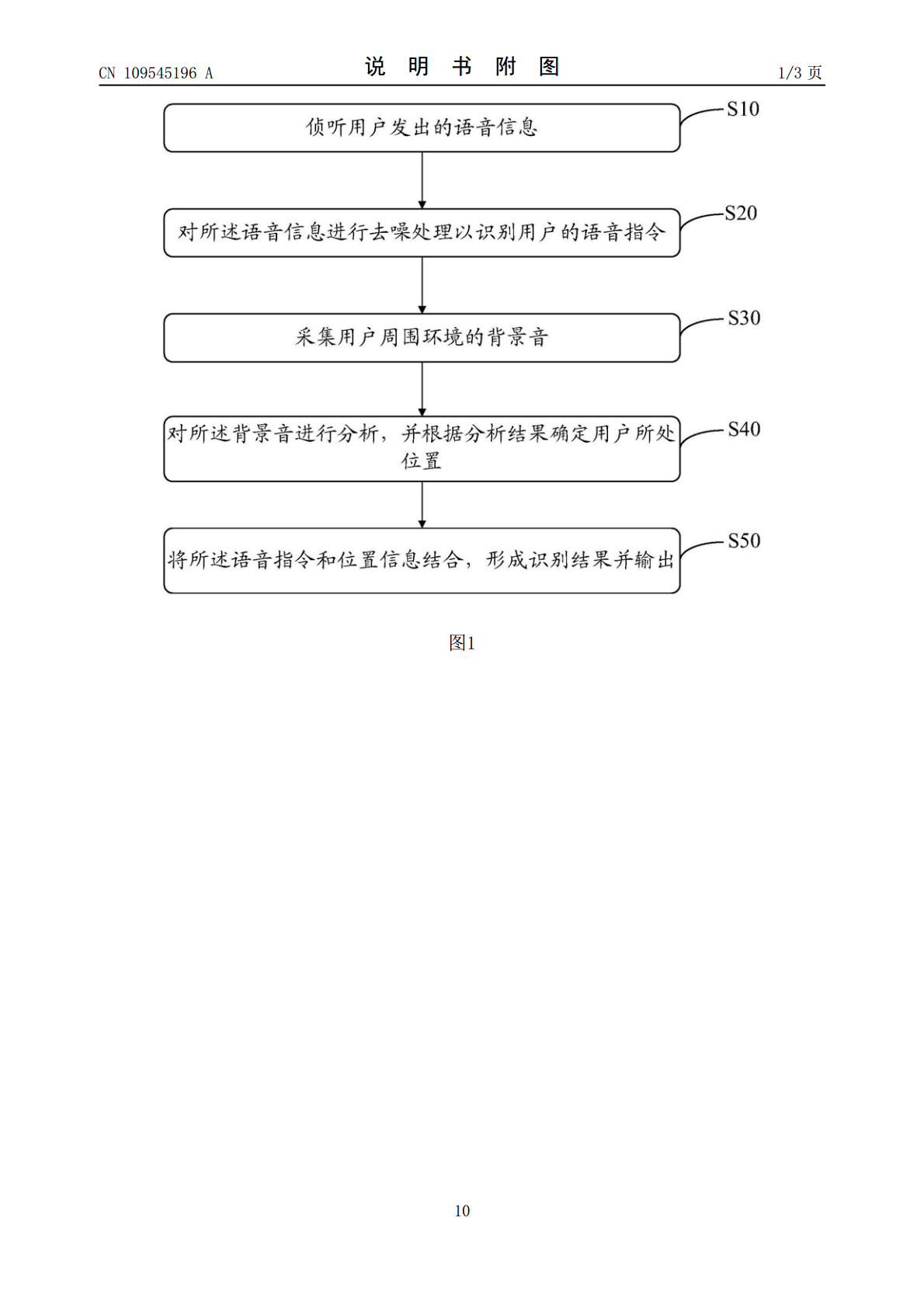
本发明公开了一种语音识别方法,所述方法包括:侦听用户发出的语音信息;对所述语音信息进行去噪处理并根据预存的语音模型识别用户的语音指令;采集用户周围环境的背景音;根据预存的背景音模型对所述背景音进行识别,并根据识别结果确定用户所处位置;将所述语音指令和位置信息结合,形成最终识别结果并输出。本发明还同时公开了一种语音识别装置及计算机可读存储介质。本发明可提升智能终端设备的语音识别准确率。

语音识别方法、装置、设备及计算机可读存储介质.pdf
本发明公开了一种语音识别方法、装置、设备及计算机可读存储介质,所述方法包括:将待识别语音数据从时域数据转换为第一时频图;将第一时频图输入目标卷积神经网络进行识别,得到待识别语音数据的第一分类结果;其中,目标卷积神经网络通过预先采用语音训练样本集训练得到。本发明中将待识别语音数据从一维的时域数据转换为二维的时频图,再采用卷积神经网络进行处理,提高了语音识别的准确率。

语音识别方法、装置、设备、可读存储介质及计算机程序.pdf
本申请公开了一种语音识别方法、装置、设备、可读存储介质及计算机程序,属于计算机技术领域。通过本申请实施例提供的技术方案,获取语音数据;调用声纹识别模型,对该语音数据和语音特征集进行处理,以确定与该语音数据匹配的目标用户,语音特征集中存储有多个用户的历史语音特征;在对该语音数据进行解码的过程中,调用与目标用户匹配的目标语言模型对该语音数据进行处理,以得到该语音数据对应的目标文本,其中,目标语言模型基于目标用户的历史文本数据训练得到;输出该语音数据对应的目标文本。该技术方案能够提高语音识别的准确率。

语音识别方法、装置、设备、系统及计算机可读存储介质.pdf
本申请公开了一种语音方法、设备、系统及计算机可读存储介质,其中,该方法包括:首先,获取反射语音信号,其中,反射语音信号为声源发出的原始语音信号经过声音反射装置反射的声音信号。然后,根据反射语音信号,判断声源是否来自于所述目标用户。利用该方法能够提高语音识别的准确性,从而进一步提高声纹解锁的安全性。

复合语音识别方法、装置、设备及计算机可读存储介质.pdf
本发明涉及人工智能领域,使用了深度学习实现了通过胶囊网络模型识别出复合语音信号的语音类型。具体共公开了一种复合语音识别方法、装置、计算机设备及计算机可读存储介质,该方法包括:实时或定时检测预置范围内的复合语音;当检测到所述复合语音时,获取所述复合语音的声音信号;对所述声音信号进行短时傅里叶变换,生成所述复合语音信号的时频图;基于预置胶囊网络模型,提取所述时频图的多个频谱,获取各个所述频谱的梅尔频率倒谱系数;通过所述预置胶囊网络模型,计算出各个所述梅尔频率倒谱系数的向量模,并根据各个所述梅尔频率倒谱系数的向