
一种抓取网页的方法和装置.pdf

王秋****哥哥


1/10

2/10

3/10

4/10

5/10

6/10
7/10

8/10
9/10

10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种抓取网页的方法和装置.pdf
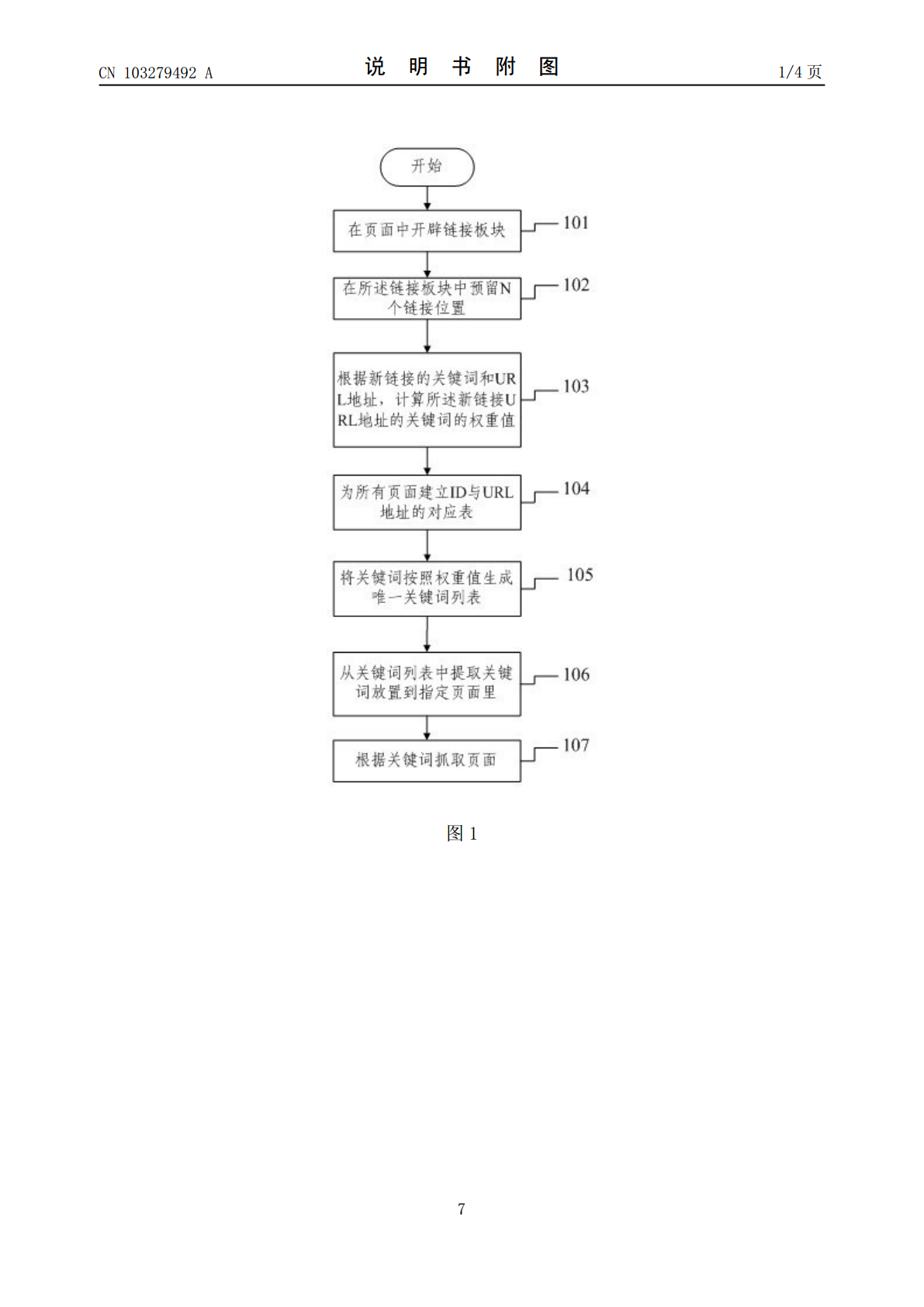
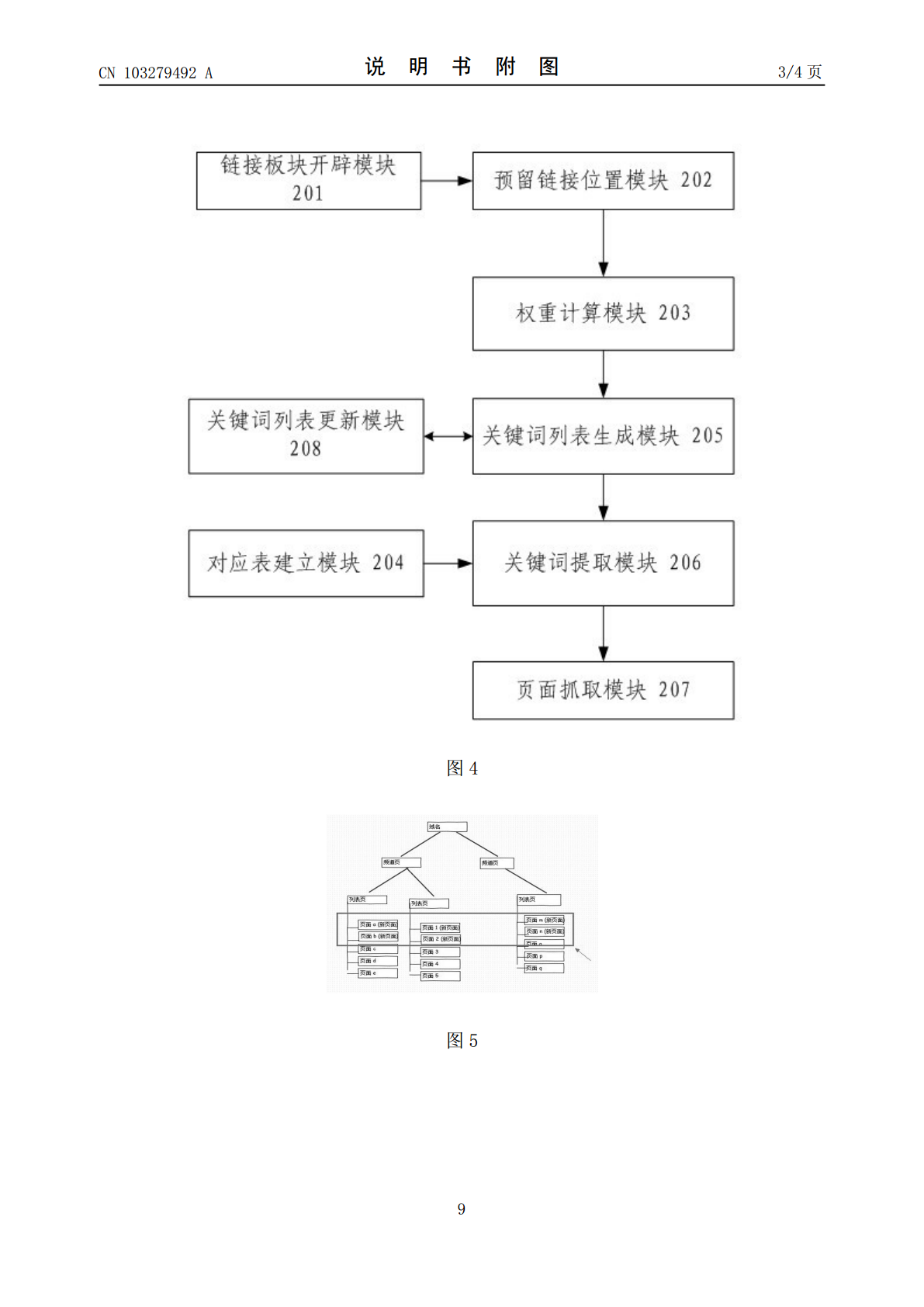
一种抓取网页的方法和装置,包括如下步骤:(1)根据新链接的关键词和URL地址,计算所述新链接URL地址的关键词的权重值;(2)将关键词按照权重值生成关键词列表;(3)从关键词列表中提取关键词放置到指定页面里;(4)根据关键词抓取页面。本发明所提出的方案通过内链接的平衡性,提高了搜索引擎的网页抓取率。

一种网页抓取方法及装置.pdf
本发明涉及网络信息处理技术领域,提供了一种网页抓取方法及装置,其中,该方法包括:获取网页的抓取周期,计算得出再次抓取该网页的时间;确定再次抓取该网页的时间早于当前时间的网页,将该网页重新加入待抓取的网页队列;从待抓取的网页队列中再次进行网页抓取。通过本发明解决了现有技术中开源网络爬虫只能对网页进行单次抓取的情况下,需要定时重新抓取网页进行网页更新导致的无法自动适应网页更新频率的问题,从而可以不断调整各个网页的抓取周期,实现了网页的及时更新,降低了重抓大量未更新网页而带来的成本,提高了搜索引擎的及时性。

网页抓取方法及装置.pdf
本发明公开了一种网页抓取方法及装置,属于计算机网络领域。所述方法包括:抓取游戏网站上的目标网页页面;根据目标网页页面的网页源代码,识别H5游戏对应的网页页面;对H5游戏对应的网页页面进行动态渲染,得到渲染后的网页页面;渲染后的网页页面中提取H5游戏对应的游戏详情信息。本发明通过网页源代码识别出H5游戏对应的网页页面,使得服务器能够从渲染后的该网页页面中提取出H5游戏对应的游戏详情信息,避免了抓取结果需要大量人工来筛选和信息提取的问题,达到了根据网页的源代码准确识别H5游戏对应的网页页面,进行从网页页面中提

一种用于网络爬虫系统的网页内容抓取方法及装置.pdf
本申请的实施例公开了一种用于网络爬虫系统的网页内容抓取方法及装置,所述方法首先构建一IP地址数据库,记录有预设网站的域名及与该域名对应的多个IP地址;然后通过查询所述IP地址数据库,将所述网络爬虫系统欲执行抓取的目标网页地址URL中的域名替换为一个与该域名对应的IP地址后执行抓取。本申请的实施例充分利用了大网站的布局特点,通过域名系统DNS查询工具,获取到各个大网站分布在全国各地的CDN结点的IP地址,或者其提供轮询服务的多个IP地址,然后把这些IP地址对应的服务器作为独立的服务器进行抓取,从而提高了对大

一种基于双目视觉的快递包裹抓取装置和抓取方法.pdf
本发明公开了一种基于双目视觉的快递包裹抓取方法和装置,方法包括建立坐标系、图像预处理、角点检测、轮廓提取、确定机器人抓取位姿;快递包裹抓取装置,装置支架的顶端安装有双目摄像机,在双目摄像机的下方设置有笼车,笼车的一侧设置有六轴机械臂,六轴机械臂上安装有机械抓手。本发明的有益技术效果是:操作对象为快递包裹,形状基本近似于长方体,装置的主要功能包括图像中的关键点识别、包裹轮廓识别、抓取机器人末端抓取位姿计算、抓取轨迹控制等,实现了功能一体化,节省工作空间,保证操作精度,提升工作的智能化水平,后续可与更大范围的