
一种端到端光学字符检测识别方法与系统.pdf

安双****文章


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10

10/10
亲,该文档总共11页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种端到端光学字符检测识别方法与系统.pdf
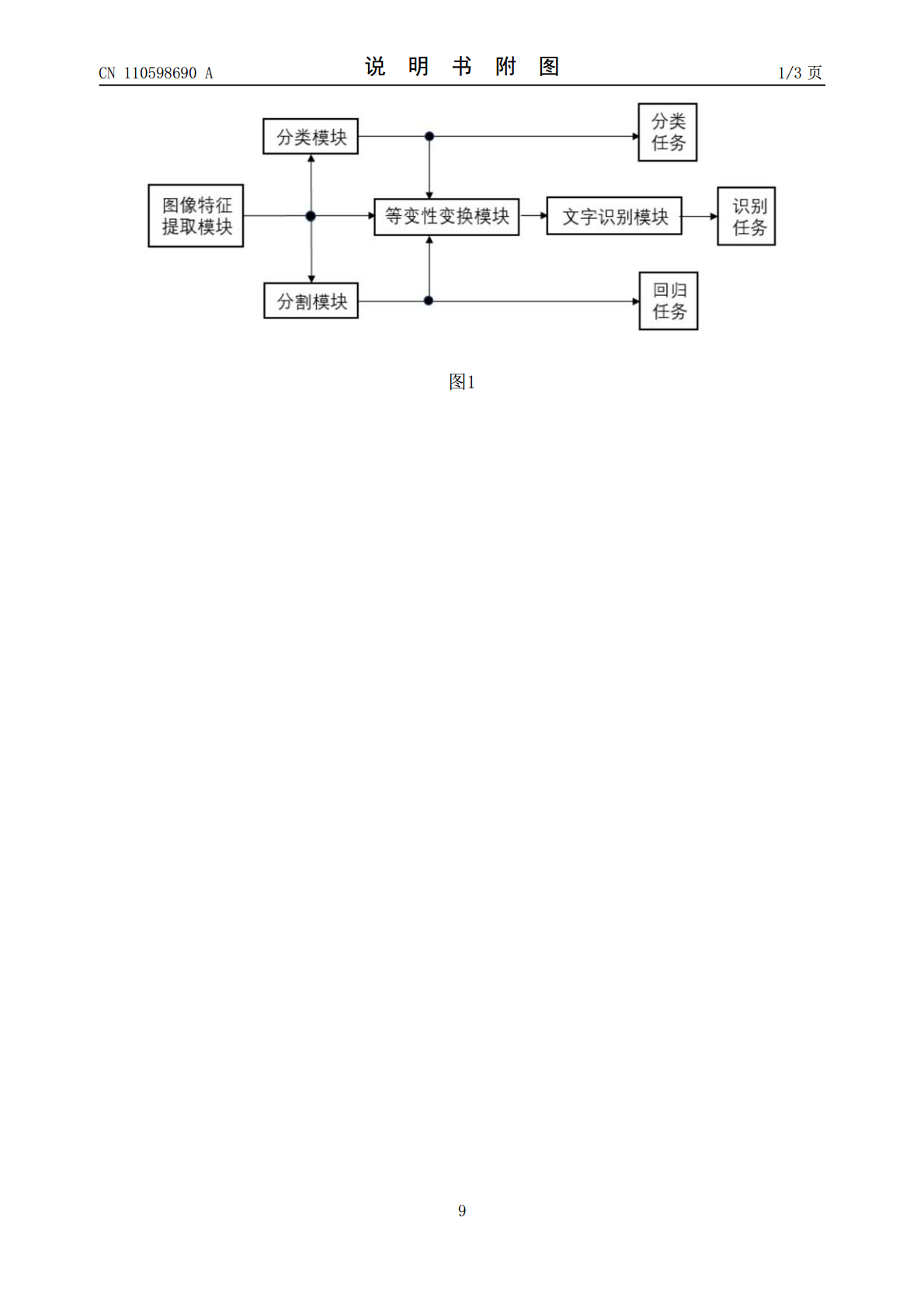
本发明公开了一种端到端光学字符检测识别方法与系统,所述识别方法包括:提取图像特征,获得感兴趣区域;分类感兴趣区域,获得感兴趣区域的边框的角度信息;分割感兴趣区域,获得区域中的文本图像轮廓信息;基于角度信息、文本图像轮廓信息将文本图像全部划分入多个基于极坐标的圆,调整圆及其圈定内容的坐标从而修整文本图像;识别修整后的文本图像。本发明融合了一种变换网络实现等变性变换的方法,实现了弯曲文本区域的精确变换。

一种端到端的道路裂缝检测系统.pdf
本发明公开了一种端到端的道路裂缝检测系统,涉及计算机视觉中的语义分割领域。检测系统的检测过程包括以下步骤:视频传输;用户通过本地上传视频数据或者公网视频流输入视频数据,视频数据解码为单帧的RGB图像输入到模型中,进行下一步操作;加载双边注意力机制模型;读取图像数据帧;提取空间注意力信息;提取通道注意力信息,通过平均池化和最大池化保留了更加关注的通道特征;融合输出并可视化。系统通过设计一个大感受野的双边全局注意力网络,裂缝检测分割准确率得到提高,并且兼顾了识别速度。

一种基于PCA的端到端路面裂缝检测识别方法.pdf
本发明公开了一种基于PCA的端到端路面裂缝检测识别方法,涉及计算机视觉领域,包括以下步骤:S1:获取关于路面图像I<base:Sub>x</base:Sub>的数据集,并对数据集进行预处理;S2:将预处理后的数据集进行类别标记,计算不含裂缝的背景图像I<base:Sub>b</base:Sub>,并获取路面图像I<base:Sub>x</base:Sub>与背景图像I<base:Sub>b</base:Sub>之差图像I,并按比例构建训练集和测试集;S3:利用训练集图像I训练深度神经网络模型;S4:将测试

基于ViBe的端到端铝带表面缺陷检测识别方法.docx
基于ViBe的端到端铝带表面缺陷检测识别方法摘要铝带表面缺陷检测是铝带生产过程中非常重要的一项任务,对于保障产品质量和提高生产效率具有重要意义。传统的铝带表面缺陷检测方法常常依赖人工对样本进行视觉检查,效率低下且易出错。因此,本文提出了一种基于ViBe(VisualBackgroundExtractor)的端到端铝带表面缺陷检测识别方法。该方法将ViBe算法与深度学习相结合,从而实现自动化的铝带表面缺陷检测。首先,本文介绍了ViBe算法的原理和相关研究。ViBe算法是一种基于背景差分的前景提取方法,通过建

一种端到端的空心验证码识别方法.pdf
本发明发明了一种端到端的空心验证码识别方法,步骤为:A、对扭曲粘连的空心验证码进行预处理,去干扰,获得只含有字符的实心验证码;B、设计卷积神经网络模型,训练预处理后已知标签的整张黑白验证码的模型;C、利用步骤B的卷积神经网络模型,对未知标签的验证码进行识别。本发明提供的技术方案简单实用,能及时的对背景有图像干扰的空心验证码进行预处理,去除背景干扰,保留验证码的有效字符。本技术方案不涉及字符分割,对扭曲粘连的验证码有较高的识别率,增加了验证码识别的统一性。