
用spss软件进行一元线性回归分析.ppt

as****16


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共16页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

用spss软件进行一元线性回归分析.pptx
会计学Case1:降水(jiàngshuǐ)&纬度打开spss的数据编辑器,编辑变量视图注意:因为我们的数据中“台站名”最多是5个汉字(Hànzì),所以字符串宽度最小为10才能全部显示。编辑数据(shùjù)视图,将excel数据(shùjù)复制粘贴到spss中从菜单上依次(yīcì)点选:图形—旧对话框—散点/点状定义简单分布,设置Y为年降水量,X为纬度由散点图发现,降水量与纬度之间线性相关step2:做散点图从菜单上依次点选:分析—回归—线性设置:因变量为“年降水量”,自变量为“纬度”“方法”:选

用spss软件进行一元线性回归分析.ppt
利用spss进行一元线性回归Case1:降水&纬度打开spss的数据编辑器,编辑变量视图注意:因为我们的数据中“台站名”最多是5个汉字,所以字符串宽度最小为10才能全部显示。编辑数据视图,将excel数据复制粘贴到spss中从菜单上依次点选:图形—旧对话框—散点/点状定义简单分布,设置Y为年降水量,X为纬度由散点图发现,降水量与纬度之间线性相关step2:做散点图从菜单上依次点选:分析—回归—线性设置:因变量为“年降水量”,自变量为“纬度”“方法”:选择默认的“进入”,即自变量一次全部进入的方法。“统计量

利用spss软件进行线性回归分析.doc
大连民族学院数学实验报告课程:应用统计实验题目:利用spss软件进行线性回归分析系别:理学院专业:信息与计算科学姓名:历红影班级:信息102班指导教师:周庆健完成学期:2012年12月19日实验目的:了解SPSS软件的功能学会用SPSS软件进行线性回归分析学习线性回归相关理论知识,并能够应用其解决实际问题实验内容:(问题、数学模型、要求、关键词)如下表为20名消费者的年收入、家庭成员人数和年信用卡支付数额的数据:信用卡支付金额/元年收入/万元家庭成员人数/人40165.4324593.1238003.24

实验六-用SPSS进行非线性回归分析.doc
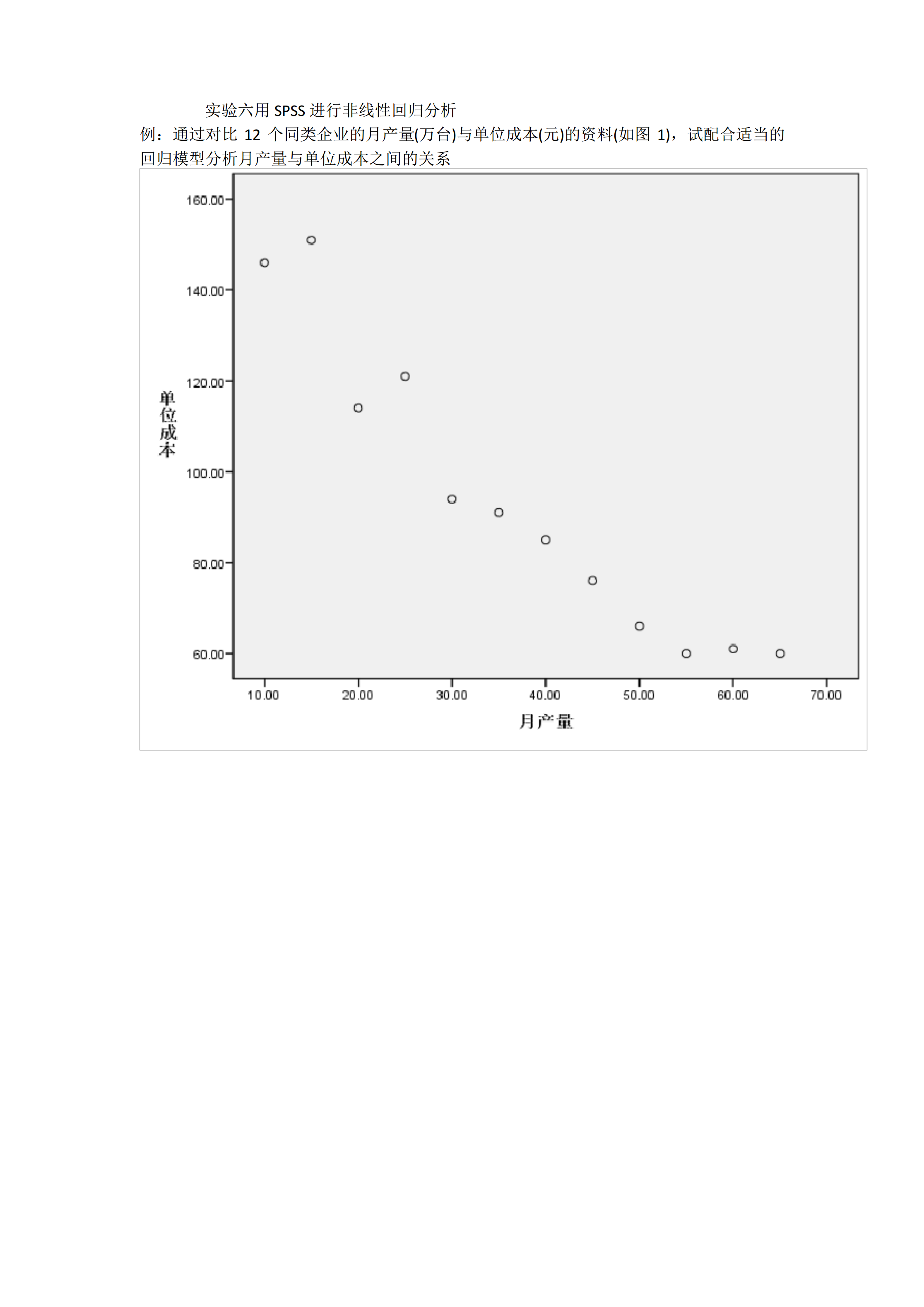
实验六用SPSS进行非线性回归分析例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的回归模型分析月产量与单位成本之间的关系图1原始数据和散点图分析一、散点图分析和初始模型选择在SPSS数据窗口中输入数据,然后插入散点图(选择Graphs→Scatter命令),由散点图可以看出,该数据配合线性模型、指数模型、对数模型和幂函数模型都比较合适。进一步进行曲线估计:从Statistic下选Regression菜单中的CurveEstimation命令;选因变量单位成本到Dep
实验六 用SPSS进行非线性回归分析.pdf
实验六用SPSS进行非线性回归分析例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的回归模型分析月产量与单位成本之间的关系图1原始数据和散点图分析一、散点图分析和初始模型选择在SPSS数据窗口中输入数据,然后拔出散点图(选择Graphs→Scatter命令),由散点图可以看出,该数据配合线性模型、指数模型、对数模型和幂函数模型都比较合适。进一步进行曲线估计:从Statistic下选Regression菜单中的CurveEstimation命令;选因变量单位成本到Dep