
语音识别系统教学.ppt

kp****93


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
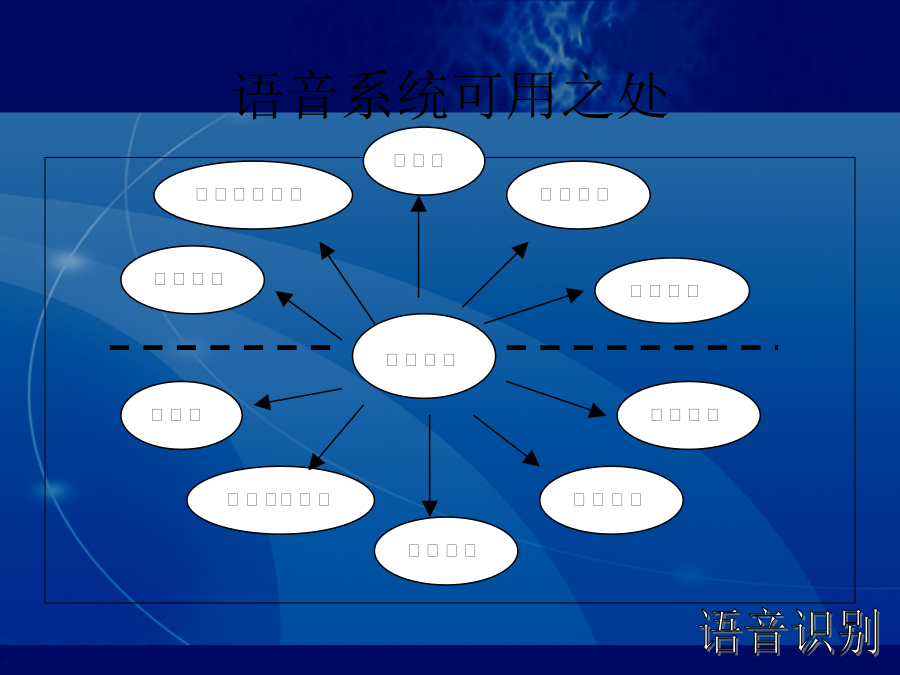
10/10
亲,该文档总共33页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

语音识别系统教学.ppt
语音识别前言◆语音识别的重要性◆语音识别的定义和分类◆语音识别技术简介◆特征提取语音识别的重要性人与人之间、人与机器之间的语音信息处理过程语音识别的定义语音识别的分类语音识别最基本的定义是“电脑能听懂人类说话的语句或命令,而做出相应的工作”。也就是说,如果电脑配置有“语音识别”的程序组,那么当你的声音通过一个转换装置输入电脑内部、并以数位方式存储后,语音识别程序便开始以你的声音样本与事先存储好的声音样本进行对比工作.声音对比工作完成后,电脑就会输出一个它认为最“象”的声音样本序号,由此可以知道你刚才念的声

语音识别装置、语音识别系统.pdf
语音识别装置具备:语音检测部,检测从用户输入的语音;信息提供部,使用基于第一语音识别部对所述语音的识别结果的第一语音识别信息、或基于与所述第一语音识别部不同的第二语音识别部对所述语音的识别结果的第二语音识别信息中的某一方的语音识别信息,进行向所述用户的信息提供;以及选择部,基于从所述语音被输入起的经过时间,选择所述第一语音识别信息或所述第二语音识别信息中的某一方作为所述信息提供部所使用的语音识别信息,并且使由所述信息提供部进行的所述信息提供的方法变化。

语音识别系统.pdf
一种语音识别系统包括接收包括语音信号的声信号的多个麦克风;从声信号生成多通道输入的输入接口;存储多通道语音识别网络的一个或多个储存器,其中,多通道语音识别网络包括从多通道输入生成时间‑频率掩模的掩模估计网络;被训练为使用时间‑频率掩模从多通道输入中选择基准通道输入并且基于基准通道输入生成增强语音数据集的波束形成器网络;以及被训练为将增强语音数据集变换为文本的编码器‑解码器网络。系统还包括与一个或多个储存器关联地使用多通道语音识别网络以从多通道输入生成文本的一个或多个处理器;和渲染文本的输出接口。

语音识别系统设计.pdf
语音识别系统设计一、引言语音识别技术是指将人类语音信号转化为可处理的数字信号,并且从中提取出语音信息的一种技术。随着人工智能的快速发展,语音识别系统在日常生活和工作中扮演着越来越重要的角色。本文将介绍一个基于深度学习的语音识别系统的设计。二、系统设计1.数据采集与预处理语音识别系统的第一步是收集数据集并进行预处理。合适的数据集对于训练一个准确、鲁棒的语音识别系统至关重要。通常,一个数据集应该包括各种不同说话人、不同音频质量、不同环境条件下的语音样本。预处理包括对音频信号进行降噪和特征提取。2.模型选择与训

车载语音识别系统的语音增强方法研究.docx
车载语音识别系统的语音增强方法研究摘要随着车载语音交互系统的普及,语音交互成为了车内操作的重要方式。然而,车内环境噪声、驾驶员口齿不清等问题成为了车载语音识别系统的瓶颈,影响了交互的效率和准确性。为解决这些问题,本文研究了车载语音识别系统的语音增强方法,包括基于信号处理的语音增强方法和基于机器学习的语音增强方法。经过实验验证,基于机器学习的语音增强方法在车载语音识别系统中具有良好的效果和实用性。关键词:车载语音交互;语音增强;信号处理;机器学习AbstractWiththepopularityofin-c