
最大似然估计和贝叶斯参数估计.ppt

kp****93


1/10

2/10

3/10

4/10

5/10

6/10

7/10
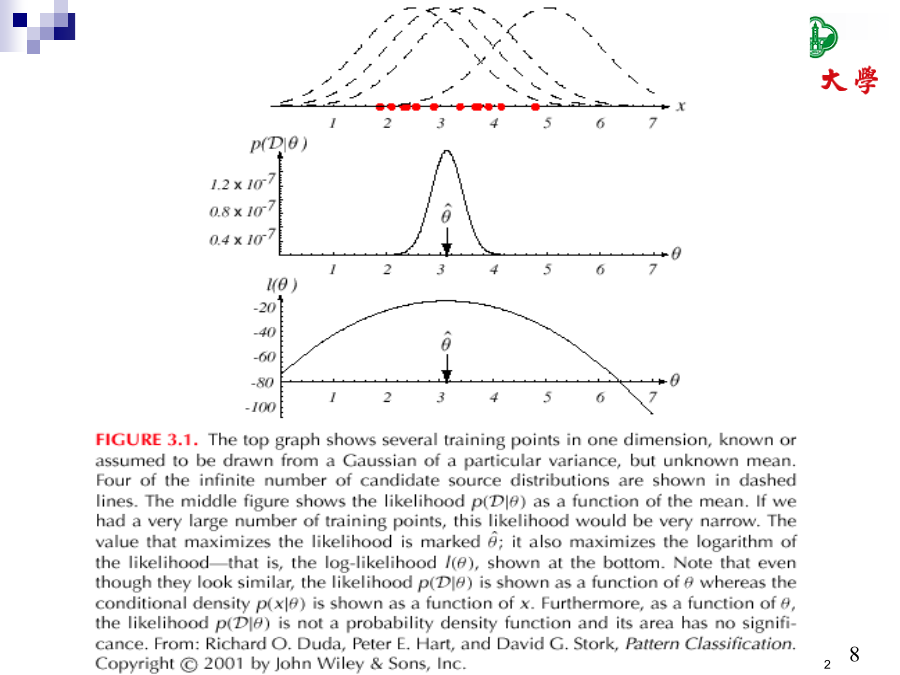
8/10
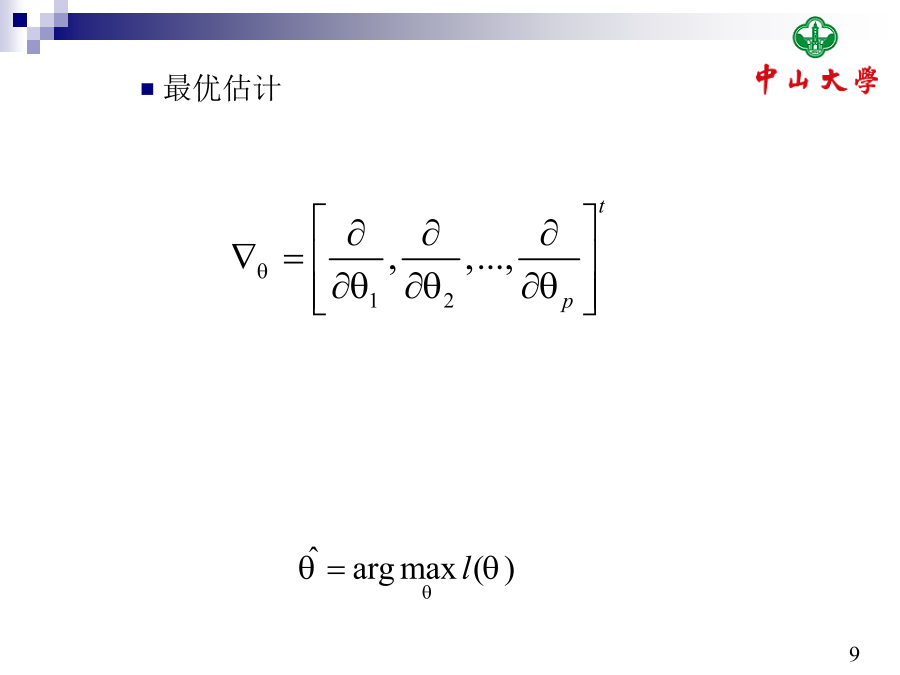
9/10

10/10
亲,该文档总共103页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

最大似然估计和贝叶斯参数估计.ppt
Chapter3:最大似然估计和贝叶斯参数估计要点:贝叶斯框架下的数据收集在以下条件下我们可以设计一个可选择的分类器:P(i)(先验)P(x|i)(类条件密度)不幸的是,我们极少能够完整的得到这些信息!从一个传统的样本中设计一个分类器先验估计不成问题对类条件密度的估计存在两个问题:1)样本对于类条件估计太少了;2)特征空间维数太大了,计算复杂度太高。如果可以将类条件密度参数化,则可以显著降低难度。例如:P(x|i)的正态性P(x|i)~N(i,i)用两个参数表示将概率密度估计问题转化为参数估计

最大似然估计和贝叶斯参数估计.ppt
Chapter3:最大似然估计和贝叶斯参数估计要点:贝叶斯框架下的数据收集在以下条件下我们可以设计一个可选择的分类器:P(i)(先验)P(x|i)(类条件密度)不幸的是,我们极少能够完整的得到这些信息!从一个传统的样本中设计一个分类器先验估计不成问题对类条件密度的估计存在两个问题:1)样本对于类条件估计太少了;2)特征空间维数太大了,计算复杂度太高。如果可以将类条件密度参数化,则可以显著降低难度。例如:P(x|i)的正态性P(x|i)~N(i,i)用两个参数表示将概率密度估计问题转化为参数估计

VaR,MS和ES的贝叶斯经验似然估计的任务书.docx
VaR,MS和ES的贝叶斯经验似然估计的任务书简介VaR、MS和ES是金融风险管理中经常用到的量化风险指标。VaR表示的是在一定置信水平下的最大风险额;MS表示的是亏损的期望值;ES表示的是在超出VaR风险水平后的平均亏损值。这三种风险指标都是基于数理统计学的理论基础,通常用于衡量金融投资组合、资产或负责任的运作风险水平。在金融风险管理中,我们希望对VaR、MS和ES进行正确的估计。然而,传统的频率统计学方法可能不适用于具有非对称风险分布,长尾分布的金融数据。贝叶斯统计学作为一种统计推断和预测的工具,具有

贝叶斯决策论和参数估计.ppt
贝叶斯决策论和参数估计提纲贝叶斯决策论最小误差率分类分类器,判别函数和判定面正态密度和判别函数贝叶斯置信网小结最大似然估计贝叶斯估计谢谢!

参数的最大似然估计.pptx
§5.2最大似然估计例其中θ是待估参数,求最大似然估计量设总体2.泊松分布3.指数分布例似然函数为设样本观测值为似然函数为是取到红球的概率.其中θ是待估参数.由于是几种常见分布的似然估计值,为似然函数.为似然函数.似然函数为:4.正态分布似然函数为为μ的最大似然估计值.