
基于跨模态文本检索注意力机制的文本指导图像分割方法.pdf

睿德****找我


1/7

2/7

3/7

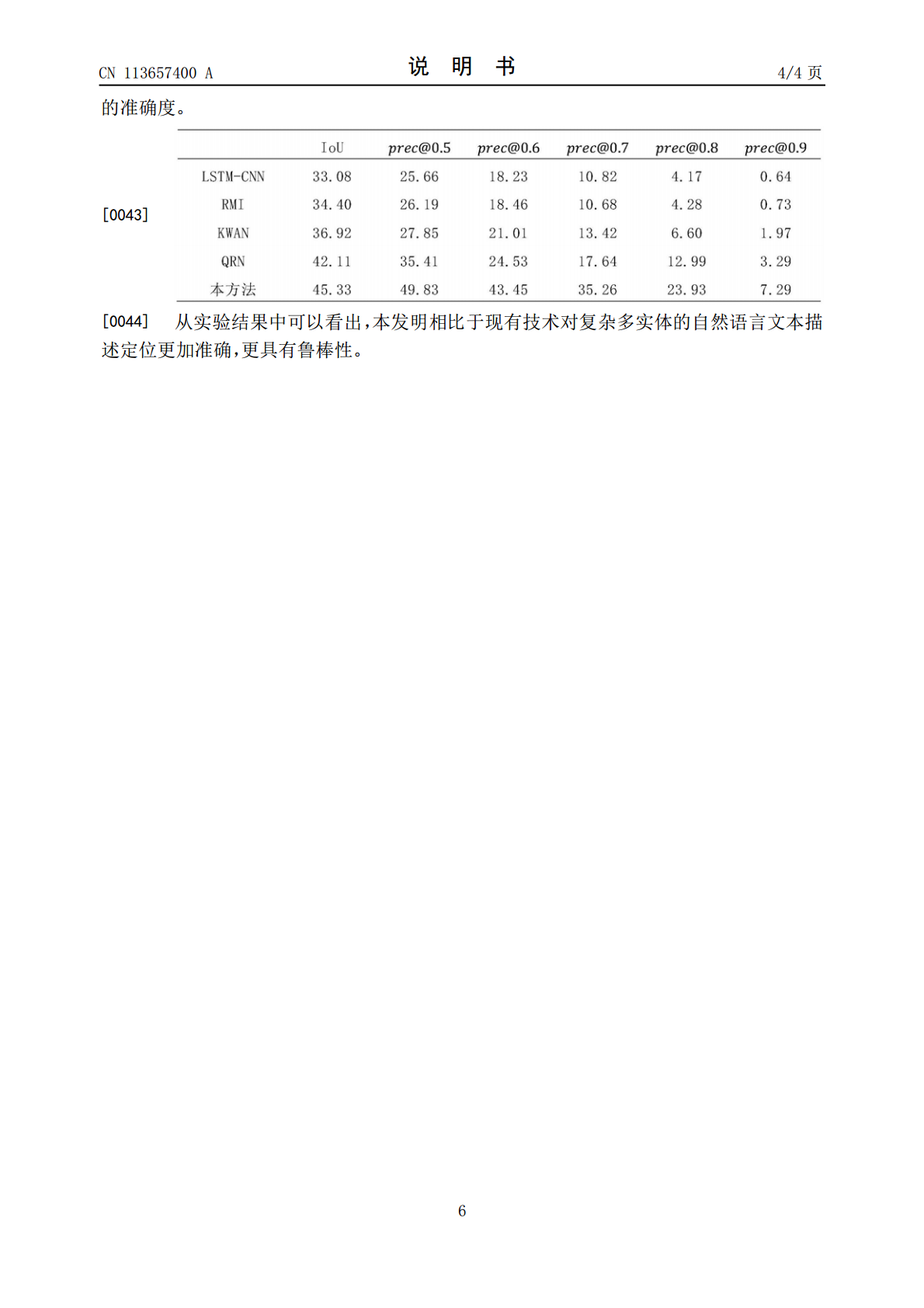
4/7

5/7
6/7

7/7
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于跨模态文本检索注意力机制的文本指导图像分割方法.pdf
一种基于跨模态文本检索注意力机制的文本指导图像分割方法,该方法将文本作为查询向量,多模态特征作为检索空间,自适应关注多模态特征空间中与文本相似区域,定位目标物体。该方法包括:特征提取、图文信息深度融合、深层次关系捕捉和多层级特征混合。采用卷积网络和长短时记忆网络提取视觉、语言特征;使用哈达玛积将视觉、语言特征信息深度融合;采用基于文本查询的注意力机制获取图片场景中与文本描述相似区域,最后将多个层级的特征混合分割目标物体。该方法能够在复杂场景下有效提高定位目标的准确度,实现区域的精确分割。

基于语义关系图的跨模态张量融合网络的图像文本检索.pptx
汇报人:CONTENTSPARTONEPARTTWO跨模态检索的背景和意义跨模态张量融合网络的基本概念跨模态张量融合网络的应用场景PARTTHREE语义关系图的构建方法基于语义关系图的图像特征提取基于语义关系图的文本特征提取图像与文本的匹配与检索PARTFOUR输入数据的预处理张量融合层的构建与优化语义关系图的构建与优化检索结果的排序与输出PARTFIVE实验数据集介绍实验方法与评价指标实验结果展示与分析结果与现有技术的比较PARTSIX基于语义关系图的跨模态张量融合网络的优势与不足对未来研究的建议与展望

基于语义关系图的跨模态张量融合网络的图像文本检索.pptx
,CONTENTS01.02.跨模态检索的背景和意义跨模态张量融合网络的基本原理跨模态张量融合网络的应用场景03.语义关系图的基本概念语义关系图在图像文本检索中的应用基于语义关系图的图像文本检索的优势04.图像和文本数据的预处理构建语义关系图的方法跨模态张量融合的算法流程实验结果和性能评估05.当前研究的局限性和挑战未来研究方向和可能的改进跨模态张量融合网络的应用前景感谢您的观看!

基于注意力机制指导特征融合的图像语义分割方法.pdf
本发明公开一种基于注意力机制指导特征融合的图像语义分割方法,包括如下步骤:(10)编码器基础网络构建:使用改进后的ResNet‑101生成一系列由高分辨率低语义到低分辨率高语义变化的特征;(20)解码器特征融合模块构建:采用基于三层卷积操作的金字塔结构模块,提取强一致性约束的高层语义,再向低层阶段特征逐层加权融合,得到初步分割热图;(30)辅助损失函数构建:向解码阶段的每个融合输出追加辅助监督,再与热图上采样后的主监督损失叠加,强化模型的分层训练,得到语义分割图。本发明的基于注意力机制指导特征融合的图像语

基于跨模态置信度感知的图像文本匹配方法.pdf
本发明涉及跨模态检索领域,公开了一种基于跨模态置信度感知的图像文本匹配方法,以待匹配文本为桥梁,参考图像‑文本的全局语义,来衡量图像区域在待匹配文本中被描述的可信程度。并且,本发明在聚合区域‑单词匹配对的局部对齐信息以得到图文整体相关性时,根据匹配置信度来过滤掉与全局图像‑文本语义不一致的局部区域‑单词匹配对,更准确地度量的图文相关性,提升跨模态检索性能。