
基于音频增强的语音识别方法及装置.pdf

森林****来了


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于音频增强的语音识别方法及装置.pdf
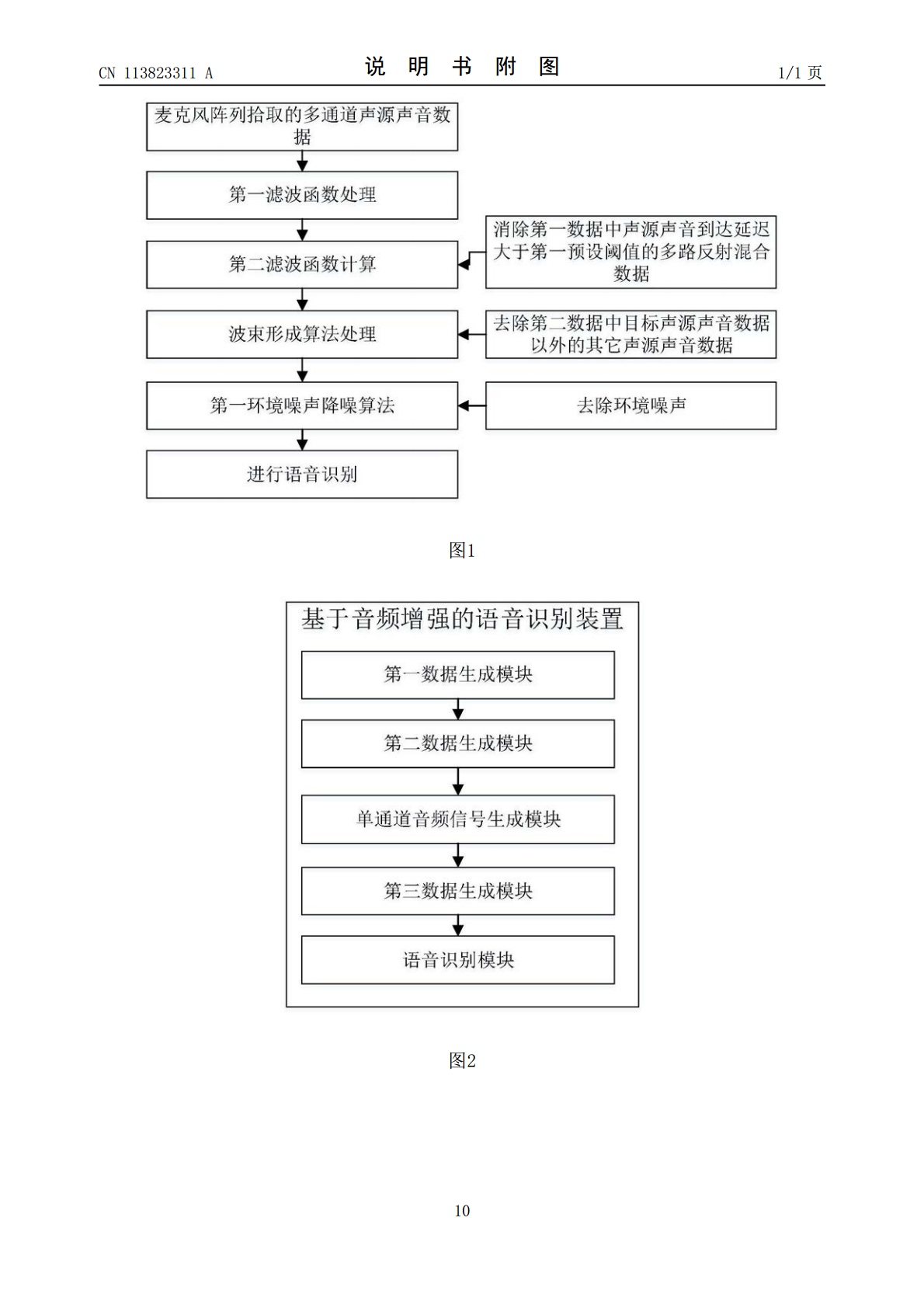
本发明公开了一种基于音频增强的语音识别方法及装置,包括将麦克风阵列拾取的多通道声源声音数据经过第一滤波函数计算获得第一数据,将第一数据经过第二滤波函数计算获得第二数据,将第二数据通过波束形成算法处理得到单通道音频信号;将单通道音频信号经过基于第一环境噪声降噪算法进行处理获得第三数据;将第三数据通过语音识别模型进行识别。本发明将麦克风阵列拾取的多通道语音数据先消除由于声源声音遇到不同障碍物反射和吸收造成的不同延时的多路反射混合语音数据,然后去除第二数据中的非目标声源声音数据,最后去除环境噪声,实现对声源声音

一种语音增强方法、语音识别方法、聚类方法及装置.pdf
本发明公开一种语音增强方法、语音识别方法、聚类方法及装置。方法包括:选取与测试语音的第一帧语音部分的特征向量最匹配的特征向量聚类中心;针对测试语音包含的其他各帧语音部分的特征向量执行:从与该语音部分的前一帧语音部分的特征向量最匹配的特征向量聚类中心,以及与前一帧语音部分的特征向量最匹配的特征向量聚类中心相邻的特征向量聚类中心中,选取与该语音部分的特征向量最匹配的特征向量聚类中心;根据测试语音包含的各帧语音部分的特征向量、选取的特征向量聚类中心重建测试语音的特征向量。本发明由于在进行语音增强利用了能够表示语

基于改进Transformer模型的语音识别方法及装置.pdf
本发明涉及基于改进Transformer模型的语音识别方法,通过改进的Transformer模型进行语音识别,改进的方式为特征融合的方式为利用拼接函数和卷积神经网络融合解码器的高低层特征,并提取局部特征信息,将卷积神经网络提取的局部细节特征与Transformer的全局特征相融合,使得模型提取的特征更具有健壮性。同时为解码器的每一层构建一条短距离的反向传播路径,缓解模型底层的梯度消失问题;以及位置编码增强,将Transformer模型的语音特征嵌入向量和位置编码进行拆解,可以解决因为两者间的弱关联而引起噪

基于短视频语音的情感识别方法和装置.pdf
本申请公开了一种基于短视频语音的情感识别方法和装置,属于语音情感识别技术领域。该方法包括:创建短视频的语音数据集,对语音数据集进行预处理,对预处理后的语音数据进行计算得到梅尔倒谱系数,作为输入送入CNN模型进行训练,得到声学情感类别C1;将预处理后的语音数据转换为文本数据,进行分词、去除停用词和文本特征抽取操作,再使用预训练的LSTM模型进行训练得到语义情感类别C2;按照预设的比重结合C1和C2,得到最终语音情感类别C。该装置包括:创建模块、预处理模块、声学识别模块、语义识别模块和结合模块。本申请扩展了语

一种基于语音的动物识别方法及装置.pdf
一种基于语音的动物识别方法及装置,所述方法包括:采集若干动物物种的语音样本,提取各语音样本的声波特征参数建立声纹模型,构成一声纹数据库;获取待分析的动物语音信号,利用单声道语音分离技术从所述动物语音信号中分离出至少一个源信号;提取各源信号的声纹,并与声纹数据库中各动物物种的声纹模型进行匹配;记录匹配成功的源信号所对应的动物物种。利用手机等移动终端监听用户周围动物的叫声,通过语音频谱分析的方法,提取出动物叫声的声波特征参数与数据库模型匹配,从而识别周围的动物物种及其数量分布,尤其在野外可以达到趋利避害的目的