
一种基于Transformer的端到端实例分割方法.pdf

小忆****ng


1/10

2/10

3/10

4/10

5/10

6/10

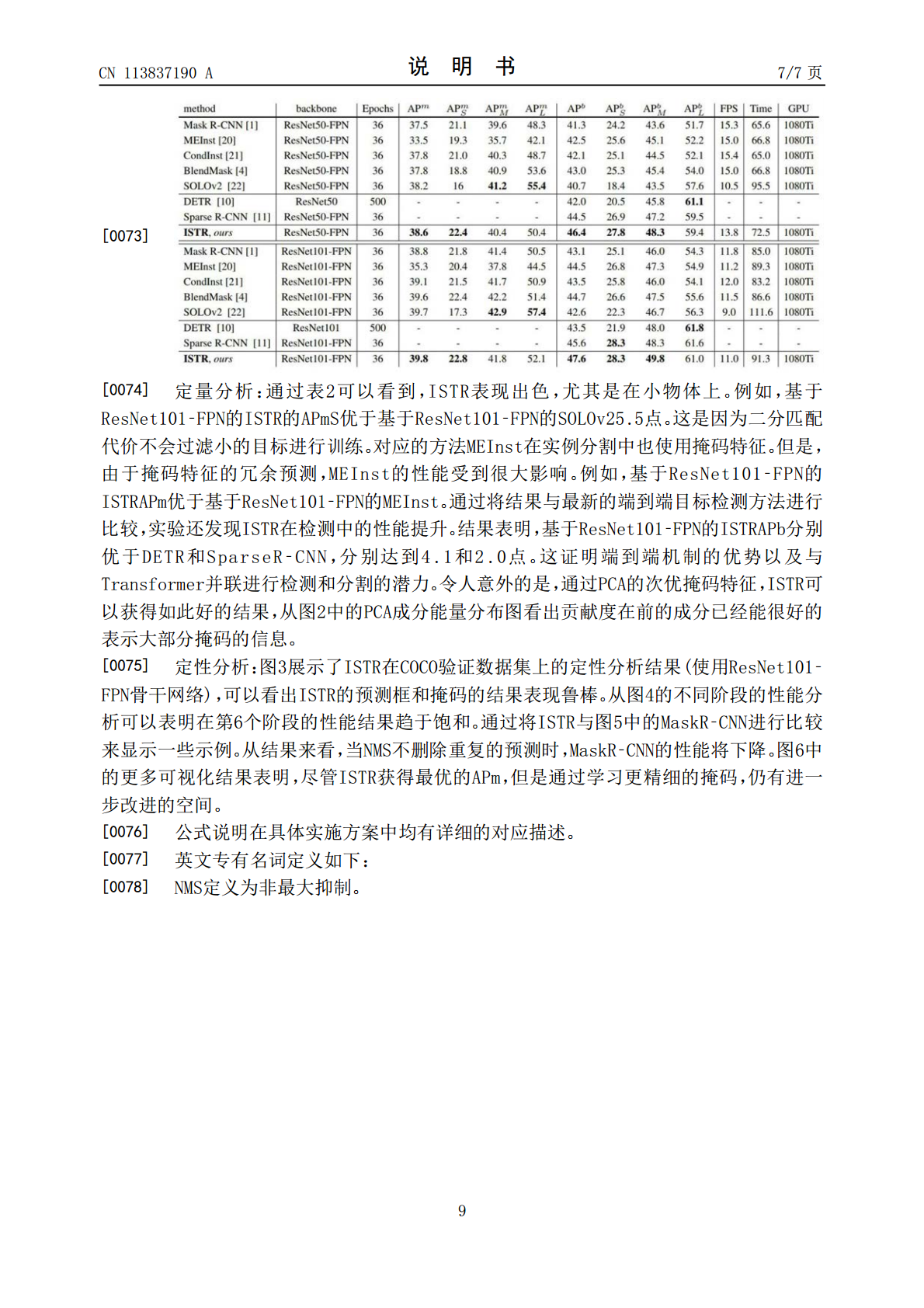
7/10

8/10
9/10

10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于Transformer的端到端实例分割方法.pdf
一种基于Transformer的端到端实例分割方法,涉及计算机视觉中的图像检测和分割领域。1)利用卷积网络和具有特征金字塔网络将图像生成特征金字塔;2)利用RoIAlign裁剪并对齐来自金字塔的特征图,提取RoI感兴趣特征区域;3)通过具有动态注意力的Transformers编码器将图像特征和RoI特征图融合到预测头中;4)由预测头输出实例的边界框,低维掩码特征,目标类别;5)反复迭代查询框,并更新预测头输出。在端到端实例分割中使用Transformers,可预测低维掩码特征而不是高维掩码,这不仅简化训练

一种基于查询向量的端到端的全景图像分割方法.pdf
本发明公布了一种基于查询向量的端到端的全景图像分割方法,使用查询向量表征全景图像分割的过程和输出的结果;查询向量(ObjectQuery)包括前景查询向量(ThingQuery)和背景查询向量(StuffQuery);建立全景图像分割模型,包括分别建立图像前景类分割模型和图像背景类分割模型;将前景查询向量和背景查询向量分别映射到图像前景类分割结果things和图像背景类分割结果stuff;基于前景查询向量和背景查询向量进行检测训练,缩短前景目标的检测训练时间,实现端到端地训练和输出前景分割结果背景的

基于端对端transformer模型的语音识别方法.pdf
本发明公开了基于端对端transformer模型的语音识别方法,该方法包括:对原始语音信息进行预处理,得到音频序列信息;结合噪声修剪技术,构建transformer语音识别网络模型;基于transformer语音识别网络模型对音频序列信息进行识别处理,得到语音识别结果。通过使用本发明,能够通过获取语音数据的全局~局部信息和高层~低层特征信息进而提高模型的语音识别准确度。本发明作为基于端对端transformer模型的语音识别方法,可广泛应用于深度学习语音识别技术领域。

一种基于改进Transformer的家畜图像实例分割方法.pdf
本发明涉及一种基于改进Transformer的家畜图像实例分割方法,包括以下步骤:步骤S1:获取高质量的家畜图像,进行标注和图像数据扩增,构建训练集;步骤S2:基于多尺度可变形注意力模块和统一查询表示模块对目标检测网络DETR进行改进,从而构建基于改进Transformer的家畜图像实例分割模型;步骤S3:根据训练集对基于Transformer的家畜图像实例分割模型进行训练,得到训练好的分割模型;步骤S4:根据训练好的分割模型对待检测家畜图像数据进行处理,获得实例分割效果。本发明可以有效地解决原始Tran

一种病理图像的端到端弱监督语义分割标注方法.pdf
本发明公开一种病理图像的端到端弱监督语义分割标注方法。该方法包括:构建端到端的病理图像弱监督的语义分割标注模型,包括特征提取网络、第一分类分支、第二分类分支和分割分支,特征提取网络从原始输入图像提取特征图,该特征图将作为其他分支的输入信号;第一分类分支用于获得输入图像的类别预测;第二分类分支用于获得施加噪声后的输入图像的类别预测;分割分支用于进行输入图像的像素级语义分割预测,并将上述两个分类分支的类激活映射图的融合结果作为分割预测的伪标签;以优化设定的总体损失函数为目标训练所述语义分割标注模型;本发明提升