
基于端对端transformer模型的语音识别方法.pdf

琰琬****买买


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共13页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于端对端transformer模型的语音识别方法.pdf
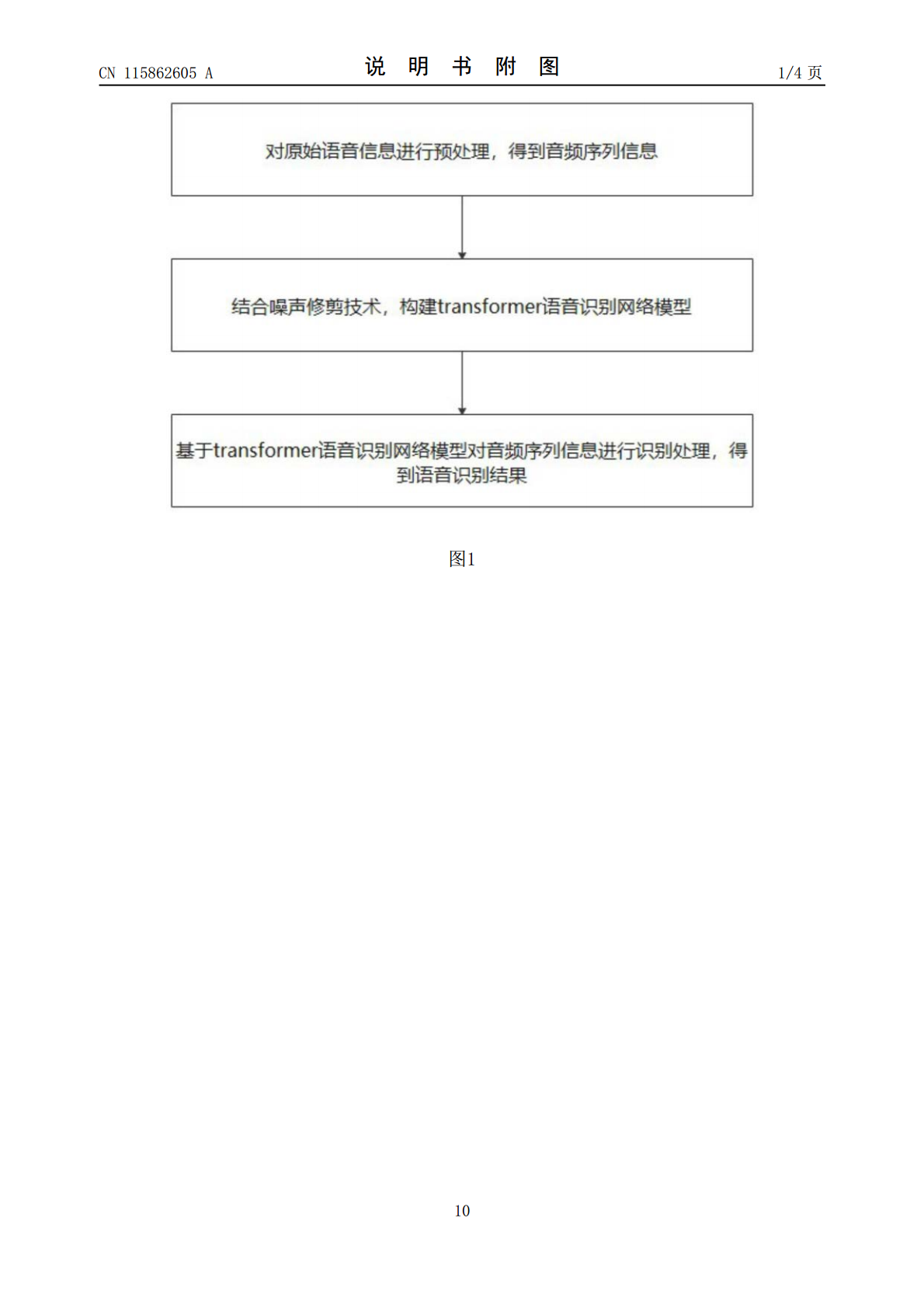
本发明公开了基于端对端transformer模型的语音识别方法,该方法包括:对原始语音信息进行预处理,得到音频序列信息;结合噪声修剪技术,构建transformer语音识别网络模型;基于transformer语音识别网络模型对音频序列信息进行识别处理,得到语音识别结果。通过使用本发明,能够通过获取语音数据的全局~局部信息和高层~低层特征信息进而提高模型的语音识别准确度。本发明作为基于端对端transformer模型的语音识别方法,可广泛应用于深度学习语音识别技术领域。

端到端语音识别模型处理方法、语音识别方法及相关装置.pdf
本发明提供的端到端语音识别模型处理方法、语音识别方法及相关装置,方法包括:获取预设词表和文本语料集;其中,所述预设词表用于维护任意一种直播领域中的热词、所述热词对应的发音路径和建模单元;根据所述文本语料集,训练初始的语言模型的模型参数,得到所述直播领域对应的目标语言模型;根据所述热词的发音路径和建模单元,更新所述目标语言模型,并确定更新后的目标语言模型中所述热词的权重;根据更新后的所述目标语言模型,生成端到端语音识别模型。由于在生成的目标语音识别模型中包含了直播领域中的热词的权重,因而使得模型能够实在语音

基于改进Transformer模型的语音识别方法及装置.pdf
本发明涉及基于改进Transformer模型的语音识别方法,通过改进的Transformer模型进行语音识别,改进的方式为特征融合的方式为利用拼接函数和卷积神经网络融合解码器的高低层特征,并提取局部特征信息,将卷积神经网络提取的局部细节特征与Transformer的全局特征相融合,使得模型提取的特征更具有健壮性。同时为解码器的每一层构建一条短距离的反向传播路径,缓解模型底层的梯度消失问题;以及位置编码增强,将Transformer模型的语音特征嵌入向量和位置编码进行拆解,可以解决因为两者间的弱关联而引起噪

基于端到端模型的混合语音识别系统及方法.pdf
本发明涉及一种基于端到端模型的混合语音识别系统及方法,包括特征提取模块、语言模型、基于端到端模型的声学模型、解码器、词图重估模块以及输出模块。本发明采用声学语言端到端建模技术,对海量语音数据进行建模,并将端到端模型的编码网络作为声学模型,嵌入到混合语音识别系统中,不仅进一步提高了语音识别准确率,而且解决了纯端到端语音识别系统在项目中难以做定制化的问题。另外,本发明在端到端模型的编码网络的基础上,继续做鉴别性声学模型训练(SMBR、MPE等),可以进一步提高识别准确率。

一种基于对比学习的端到端音障语音识别方法.pdf
本发明公开了一种基于对比学习的端到端音障语音识别方法,该方法具备语音识别能力前需要使用大量正常发音数据预训练得到一个基本模型,再迁移到音障语音识别的任务中。在训练完成后,本方法就有了音障语音识别的能力。本发明首先对音障语音数据进行频谱图上的数据增强,再通过Transformer模型中的编码器提取隐层信息,然后该隐层信息经过投影模块被提取出低维的隐表示。最后本方法在隐表示所在的低维隐空间上进行对比损失的计算。在解码过程中,解码器直接使用隐层信息进行解码。本发明的创新点在于将对比学习与Transformer模