
一种基于Transformer的视频片段分割方法.pdf

努力****爱静


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10
10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于Transformer的视频片段分割方法.pdf
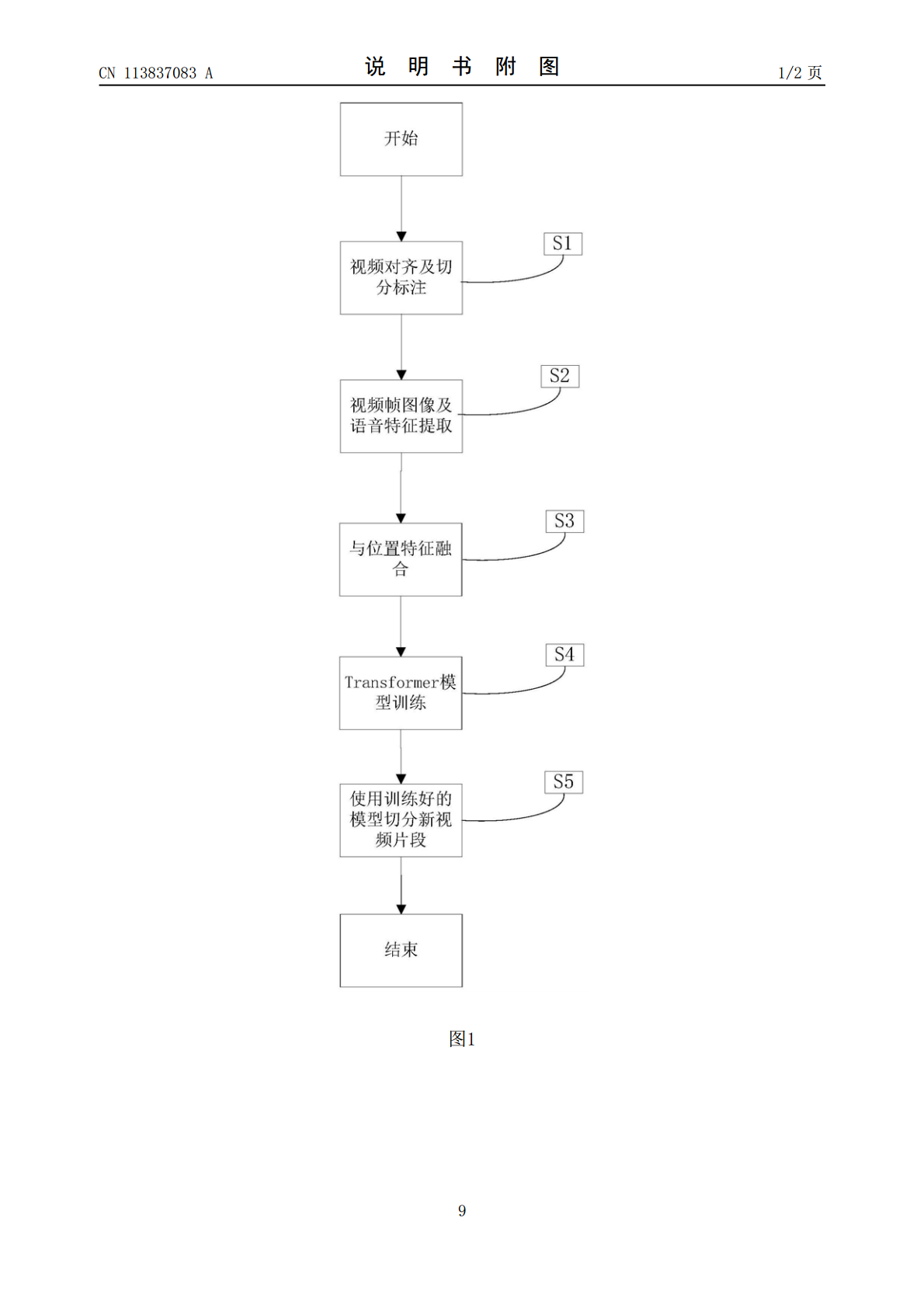
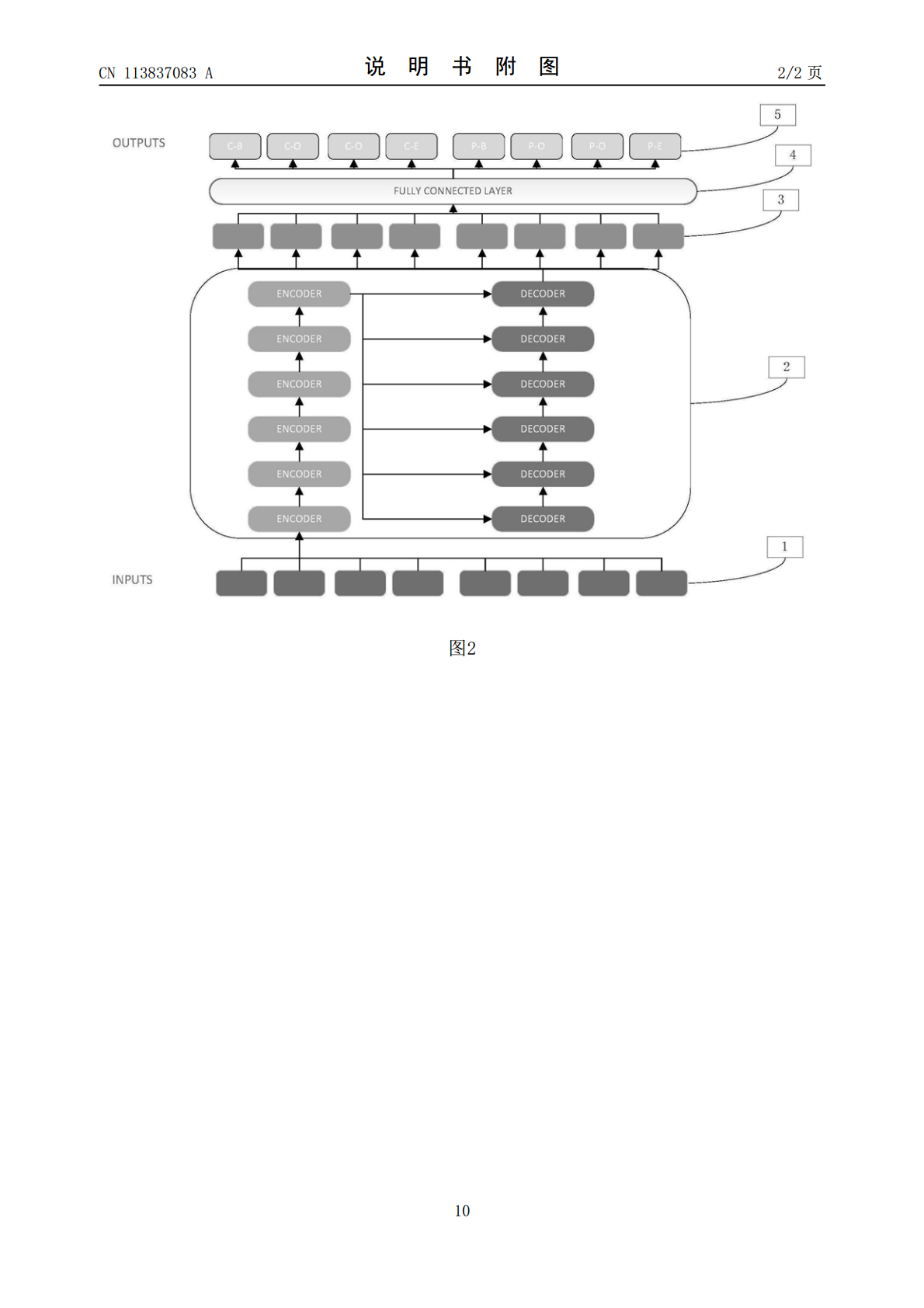
本发明公开了一种基于Transformer的视频片段分割方法,其特征在于,对视频的画面和语音采样获得采样图片和采样语音,将采样图片与采样语音对应并标注分割标签;输入卷积神经网络,提取采样图片的卷积特征和采样语音的MFCC特征,对两者进行拼接并融合位置特征,获得相应的序列,输入transformer模型进行训练;使用模型,得到目标视频的切割预测标签,根据切割预测标签对目标视频进行切分。本发明充分利用transformer模型结构对长序列建模的优势,将视频片段分割转化为序列标注问题,进一步将视频通过序列标注结

一种基于Transformer的半监督视频目标分割方法.pdf
本发明公开了一种基于Transformer的半监督视频目标分割方法,其实现方案为:1)获取数据集与分割标签;2)数据扩充与处理;3)构建分割模型;4)构建损失函数;5)训练分割模型;6)视频目标分割。本发明通过设计时空整合模块压缩时空信息,引入多尺度层生成跨尺度输入特征,构建双分支交叉注意力模块以兼顾目标信息的多个特征。本发明的方法能够在减少计算成本的同时,有效提高对小尺度目标和相似目标的分割精度。

一种基于改进Transformer的家畜图像实例分割方法.pdf
本发明涉及一种基于改进Transformer的家畜图像实例分割方法,包括以下步骤:步骤S1:获取高质量的家畜图像,进行标注和图像数据扩增,构建训练集;步骤S2:基于多尺度可变形注意力模块和统一查询表示模块对目标检测网络DETR进行改进,从而构建基于改进Transformer的家畜图像实例分割模型;步骤S3:根据训练集对基于Transformer的家畜图像实例分割模型进行训练,得到训练好的分割模型;步骤S4:根据训练好的分割模型对待检测家畜图像数据进行处理,获得实例分割效果。本发明可以有效地解决原始Tran

一种基于Transformer的端到端实例分割方法.pdf
一种基于Transformer的端到端实例分割方法,涉及计算机视觉中的图像检测和分割领域。1)利用卷积网络和具有特征金字塔网络将图像生成特征金字塔;2)利用RoIAlign裁剪并对齐来自金字塔的特征图,提取RoI感兴趣特征区域;3)通过具有动态注意力的Transformers编码器将图像特征和RoI特征图融合到预测头中;4)由预测头输出实例的边界框,低维掩码特征,目标类别;5)反复迭代查询框,并更新预测头输出。在端到端实例分割中使用Transformers,可预测低维掩码特征而不是高维掩码,这不仅简化训练

基于Transformer的视觉分割技术进展.docx
基于Transformer的视觉分割技术进展1.Transformer在计算机视觉中的应用自2017年ViLBERT模型提出以来,Transformer在自然语言处理(NLP)领域取得了显著的成果。随着深度学习技术的不断发展,Transformer逐渐被应用于计算机视觉领域,如图像分类、目标检测和语义分割等任务。在这些任务中,Transformer的核心思想是通过自注意力机制捕捉输入序列中的全局依赖关系,从而实现对复杂场景的理解和表示。基于Transformer的视觉分割技术取得了重要进展。SEGForm