
基于编解码网络的图像-文本多模态融合方法.pdf

一吃****书竹


1/8

2/8

3/8

4/8

5/8

6/8
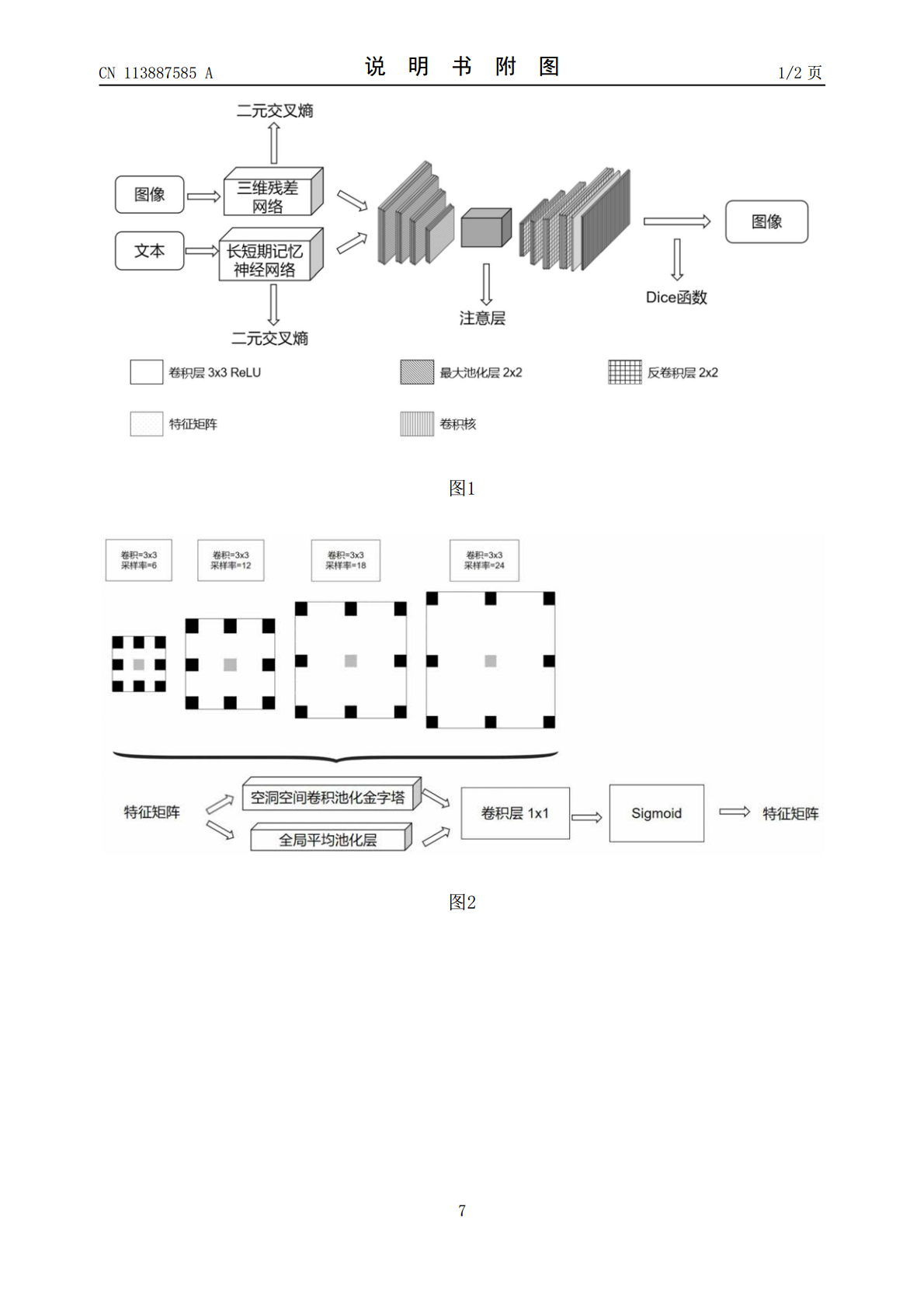
7/8

8/8
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于编解码网络的图像-文本多模态融合方法.pdf
本发明涉及一种基于编解码网络的图像‑文本多模态融合方法,属于计算机视觉、自然语言处理、模式识别技术领域。该方法包括如下步骤:S1:在现有目标检测数据集的基础上对其进行手动标记生成文本信息,构建新的图像‑文本数据集,并将数据集划分为训练集、验证集和测试集;S2:选择适合的优化学习方法,设置相关超参数,将训练集和验证集通过编解码网络模型进行训练;S3:训练结束后,在测试集中任选一张图片,输入编解码网络模型,加载训练好的模型权重,最终检测出所对应的目标结果。本发明采用图像‑文本融合处理的方法,利用同一个事物的两

基于深度编解码融合网络的SAR遥感图像水域分割方法.pdf
本发明涉及一种基于深度编解码融合网络的SAR遥感图像水域分割方法,属于图像分割技术领域。该方法包括如下步骤:(1)构建数据集;(2)训练数据标注;(3)数据增强;(4)构建深度编码网络;(5)构建深度解码网络;(6)构建编解码网络损失函数;(7)模型训练与验证;(8)分割处理;(9)根据需求,对分割结果进行保存或输出。本发明所搭建模型泛化性强、鲁棒性高、性能优异,解决目前水域提取技术上存在的弊端,可实现SAR遥感图像中水域的快速、准确分割,易于推广应用。

基于生成对抗网络的多模态图像融合.pptx
,CONTENTS01.02.生成对抗网络的基本原理生成对抗网络的应用场景生成对抗网络的优势与挑战03.多模态图像融合的基本概念多模态图像融合的方法与技术多模态图像融合的应用领域04.基于生成对抗网络的多模态图像融合方法基于生成对抗网络的多模态图像融合的优势基于生成对抗网络的多模态图像融合的挑战与解决方案05.实验数据集与实验环境实验方法与实验过程实验结果与分析结果比较与讨论06.基于生成对抗网络的多模态图像融合的结论基于生成对抗网络的多模态图像融合的展望感谢您的观看!

基于多模态信息融合的图像情感标注方法.docx
基于多模态信息融合的图像情感标注方法基于多模态信息融合的图像情感标注方法摘要:随着图像和多媒体数据的兴起,图像情感分析的重要性逐渐凸显。然而,由于图像是一种非结构化的数据,图像情感分析存在一定的挑战。为了解决这个问题,本文提出了一种基于多模态信息融合的图像情感标注方法。首先,我们通过文本挖掘技术从社交媒体中提取情感词汇。接着,我们利用深度学习方法提取图像的视觉特征。最后,我们使用一种融合算法将文本和图像特征进行结合,得到最终的情感标注结果。实验结果表明,我们的方法在图像情感标注任务中具有良好的性能。关键词

基于卷积稀疏表示的多模态图像融合方法.pdf
本发明涉及一种基于卷积稀疏表示的多模态图像融合方法,首先,利用稀疏优化函数将源图像进行两尺度分解得到高频分量和低频分量;然后,将两尺度分解得到的高频和低频分量,根据多模态图像特点采用不同的融合策略,高频分量利用卷积稀疏表示对稀疏系数取最小值的融合策略,低频分量利用取平均的融合策略得到融合后图像的低频分量;最后将得到的融合后图像的高频分量和低频分量相加得到融合图像。相对其他三种融合方法,不论在主观视觉和客观评价指标上还是在计算效率上,本发明方法可以更好保留源图像的细节等纹理信息。