
一种基于PaddleDetection的混淆矩阵生成方法.pdf

Th****84


1/7

2/7

3/7

4/7

5/7
6/7
7/7
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于PaddleDetection的混淆矩阵生成方法.pdf
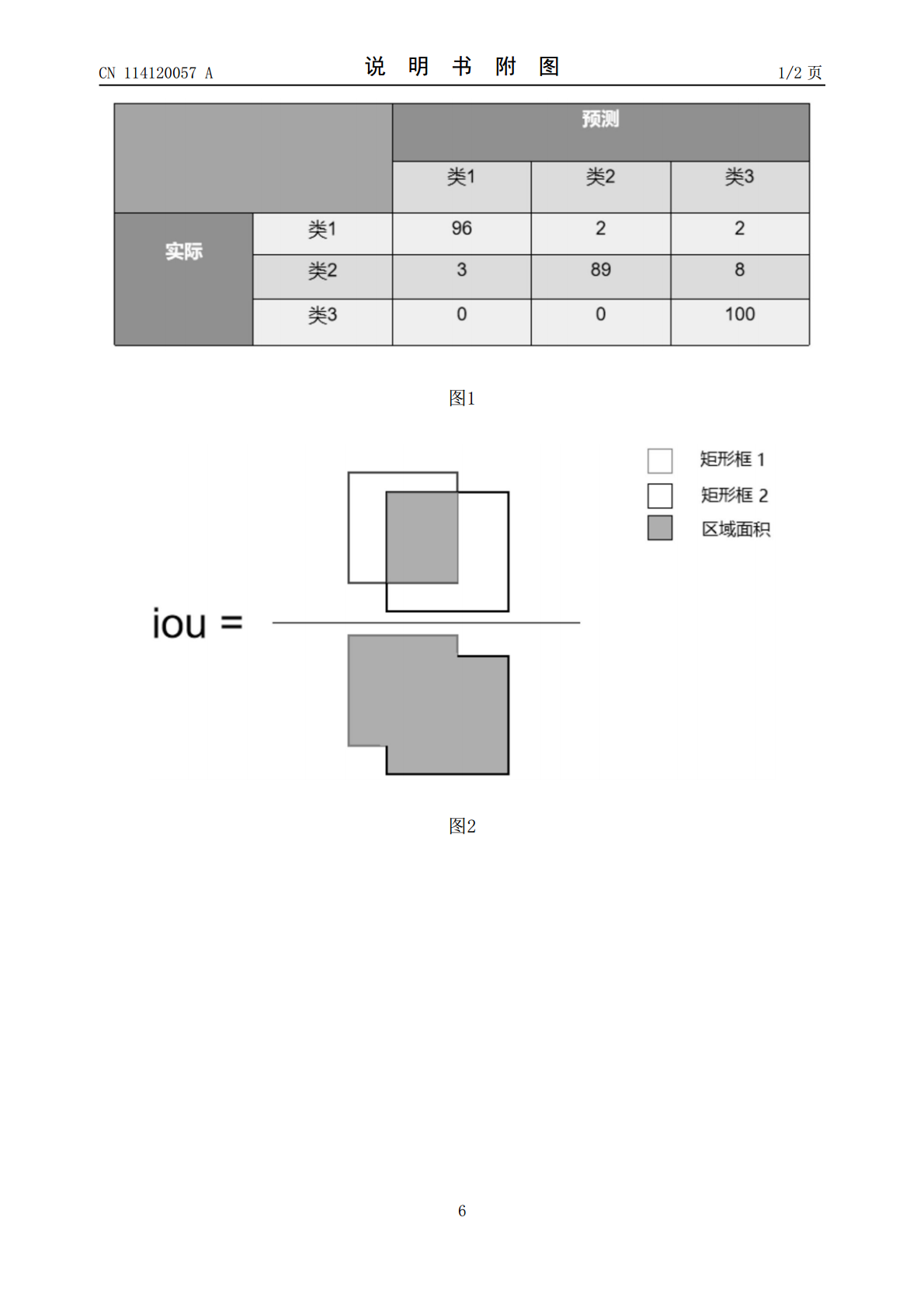
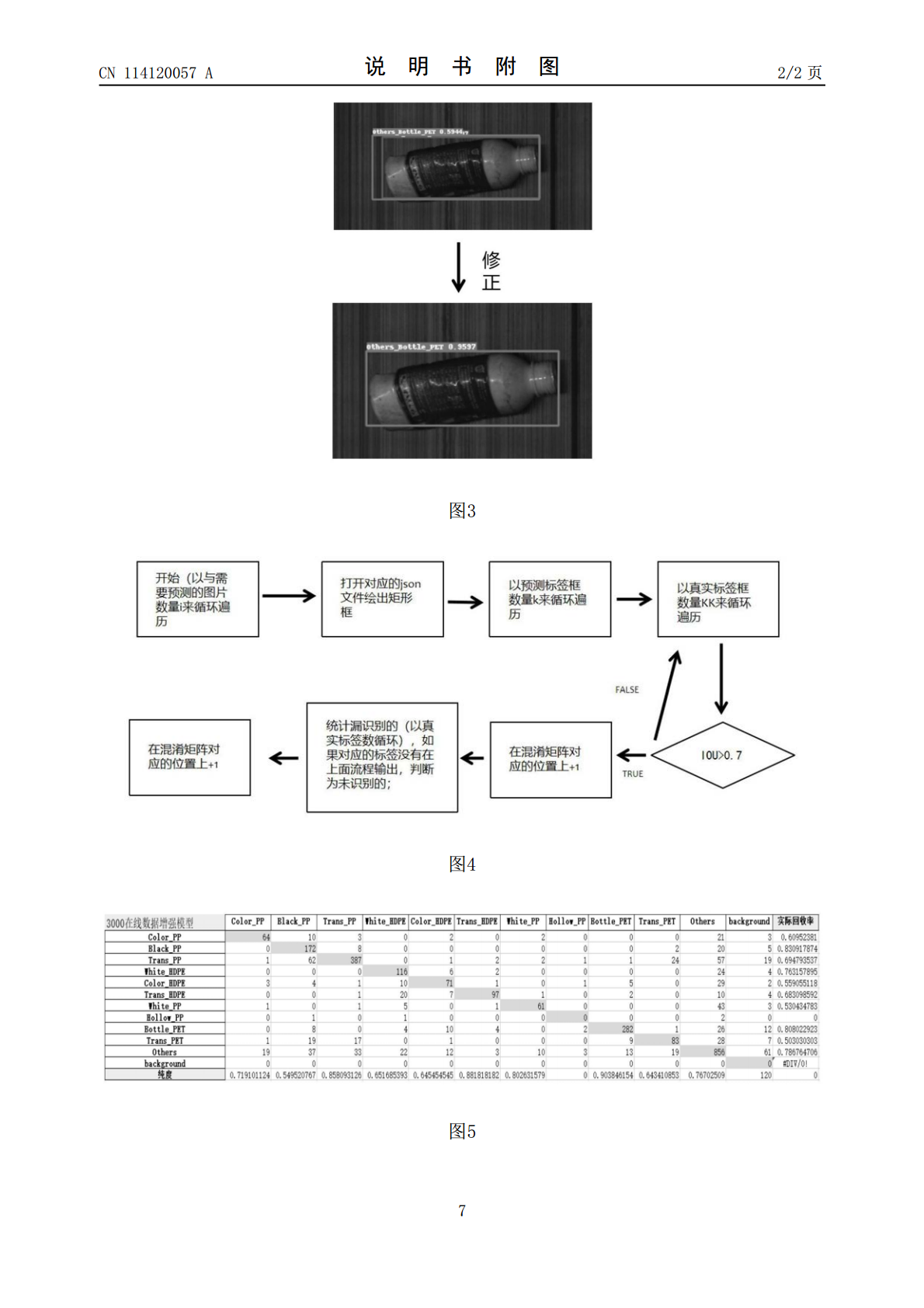
本发明提供了一种基于PaddleDetection的混淆矩阵生成方法,包括:在PaddlePaddle平台下运用PaddleDetection目标检测开发套件训练目标检测网络;获取有标注的测试数据集,分为两个文件夹,一个文件夹放json文件,另一个放对应的图片文件,并得到真实的目标物体外接矩形框;运用infer.py图片文件进行预测,得到预测标签;得出预测修正得到的矩形检测框;将真实矩形框与预测修正得到的矩形检测框进行循环匹配,将统计得到的值记录在矩阵上;创建excle表格,将记录的矩阵填充到excle表

一种基于混淆矩阵的随机森林模型选择方法.pdf
本发明公开一种基于混淆矩阵的随机森林模型选择方法,包括:a.以训练得到的决策树作为原始随机森林,各决策树在测试样本集上进行分类,得到各决策树分类结果的混淆矩阵,通过对随机森林中决策树的混淆矩阵两两作差,得到随机森林中任意两棵决策树的差值矩阵;将差值矩阵的F范数作为两棵决策树的相似性度量,建立随机森林的差异性度量矩阵;c.遍历差异性度量矩阵中不大于相似性阈值的元素;考察该元素所涉及的决策树的分类准确率大小:若低于分类准确率阈值则删除该决策树,将该决策树所在的矩阵行列上的所有元素置零,否则保留该决策树;完成随

一种基于改造传输矩阵生成对称散斑的装置和方法.pdf
本发明公开了一种基于改造传输矩阵生成对称散斑的装置和方法。所述方法具体为:首先使用空间光调制器调制激光来测量散射系统的传输矩阵;接着生成一个改造因子对传输矩阵实施变换得到改造传输矩阵;初始传输矩阵与改造传输矩阵的共轭转置构成一个新矩阵;对该矩阵实施特征分解得到特征输出模,利用改造传输矩阵数值相位共轭反演可得到输入模,取其相位加载到空间光调制器上,在探测平面可得到对称分布的散斑图样。本发明可以控制散斑分布,生成对称形式的散斑图样;本发明光路采取双光臂,最大化可调控的输入模式数量,测得传输矩阵的效果好。
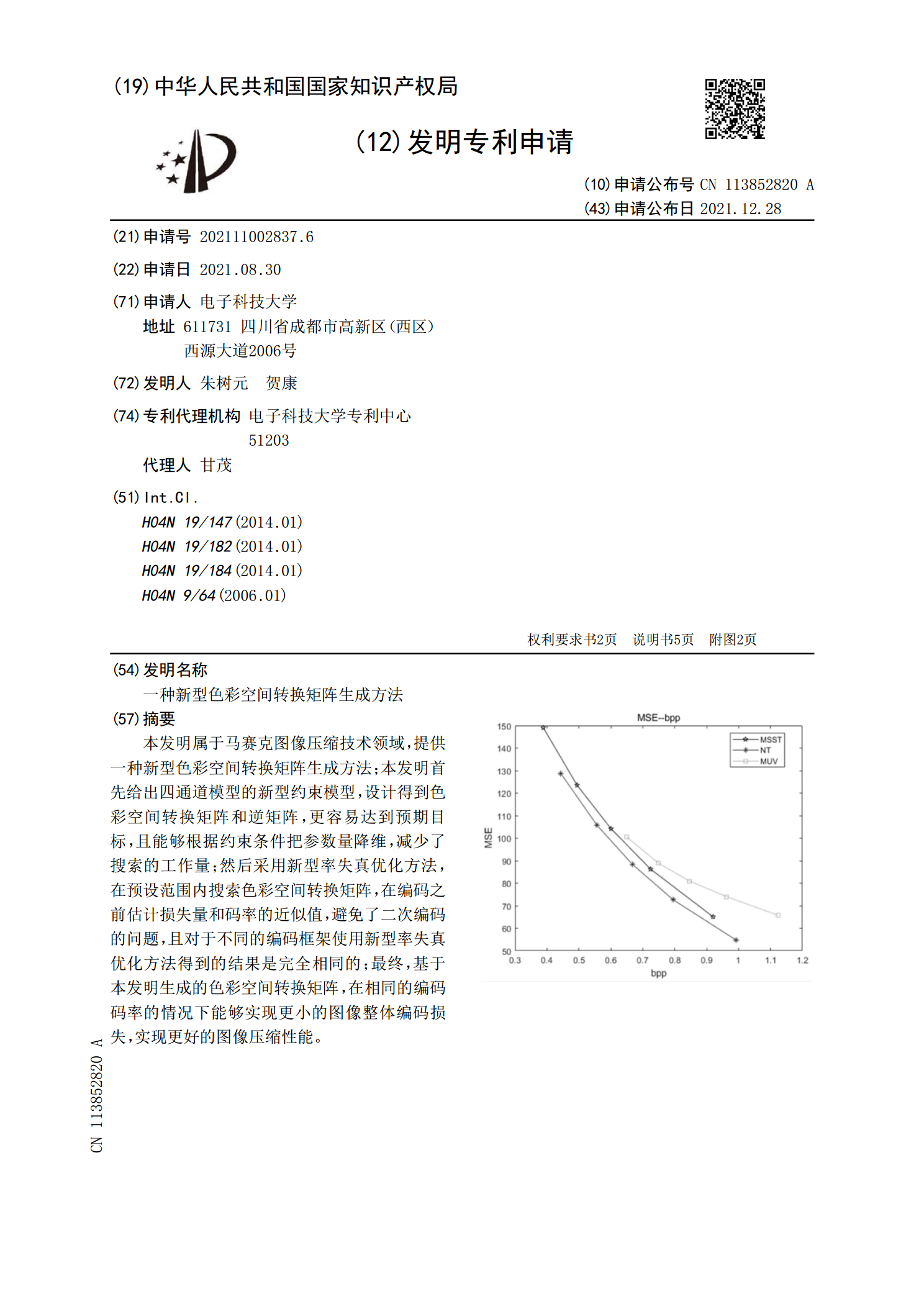
一种新型色彩空间转换矩阵生成方法.pdf
本发明属于马赛克图像压缩技术领域,提供一种新型色彩空间转换矩阵生成方法;本发明首先给出四通道模型的新型约束模型,设计得到色彩空间转换矩阵和逆矩阵,更容易达到预期目标,且能够根据约束条件把参数量降维,减少了搜索的工作量;然后采用新型率失真优化方法,在预设范围内搜索色彩空间转换矩阵,在编码之前估计损失量和码率的近似值,避免了二次编码的问题,且对于不同的编码框架使用新型率失真优化方法得到的结果是完全相同的;最终,基于本发明生成的色彩空间转换矩阵,在相同的编码码率的情况下能够实现更小的图像整体编码损失,实现更好的

一种基于矩阵束的信道预测方法.pdf
本发明公开了一种基于矩阵束的信道预测方法,考虑了由用户端运动引起的多径时延变化的实际问题,针对信道的时变特性,尤其是时延的变化对信道的影响,通过构建三维矩阵束,估计不同时刻的时延,得到时延变化的规律,基于矩阵束的超分辨率方法,分别估计出了多径方位角、俯仰角、时变的时延和多普勒参数,并基于估计出的信道参数,重构信道,能够有效克服信道状态信息(CSI)过时对通信的不利影响,实现对未来时变信道的准确预测。