
一种基于多模态交互的上下文感知的面向视觉问答的方法.pdf

小沛****文章


1/10

2/10

3/10

4/10

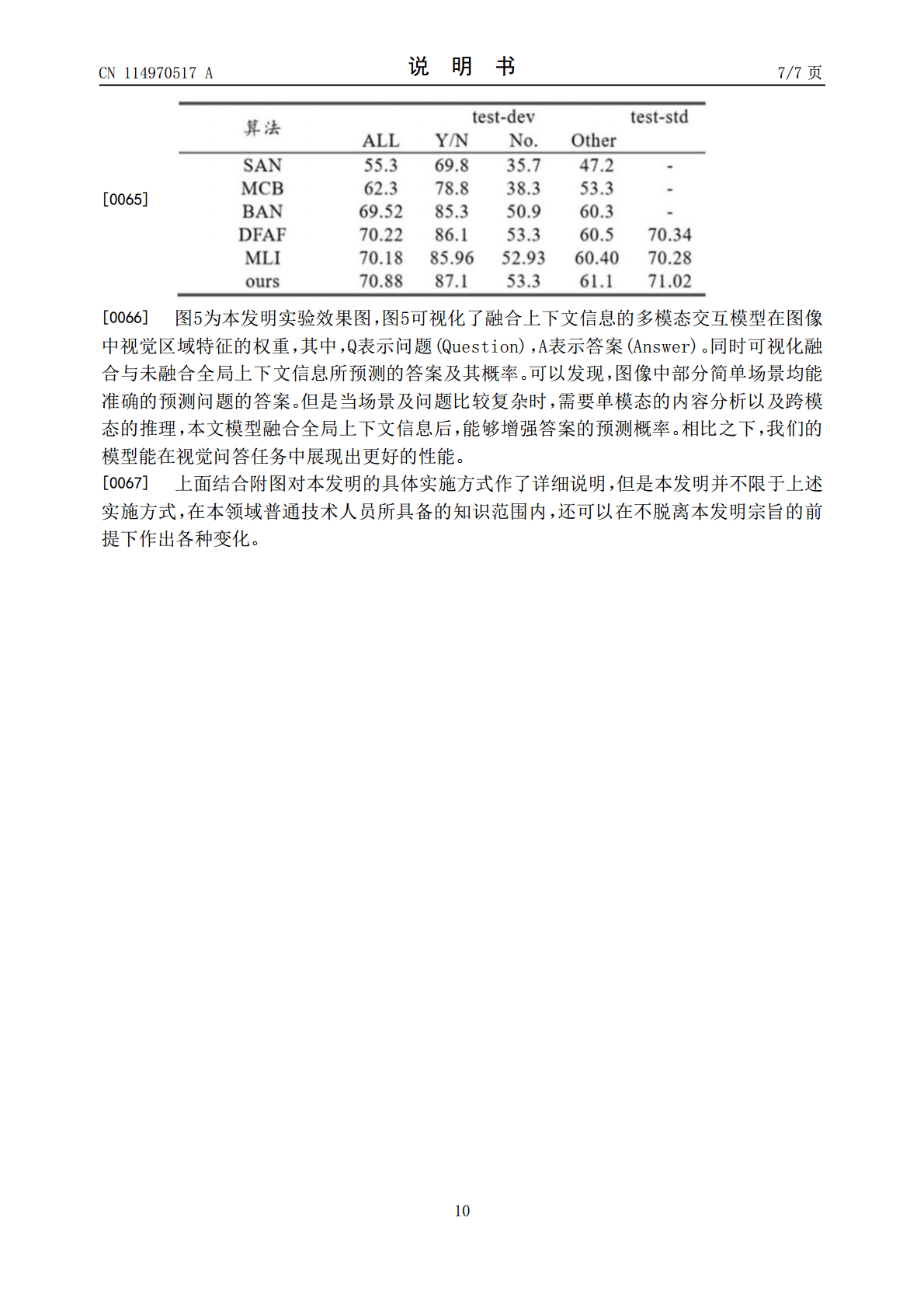
5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共13页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于多模态交互的上下文感知的面向视觉问答的方法.pdf
本发明涉及一种基于多模态交互的上下文感知的面向视觉问答的方法,属于计算机视觉语言跨模态领域。本发明包括步骤:首先通过预训练的目标检测模型提取图像视觉区域特征,使用预训练的词嵌入语言模型与GRU获得问题词向量,再根据上下文编码机制分别获得视觉与问题的全局上下文内容信息向量,然后利用融合上下文信息的注意力机制得到更新后的视觉特征与问题特征,最后融合视觉特征与问题特征获得融合特征,输入到分类层预测最终的答案分布。该方法有效增强模态内与模态间的信息交互,提高视觉问答的推理能力,其准确度比传统的视觉问答方法提高了约

一种基于多模态融合的视觉问答融合增强方法.pdf
本发明公开了一种基于多模态融合的视觉问答融合增强方法。本发明步骤如下:1、利用GRU结构构建时序模型,获得问题的特征表示学习、利用从FasterR‑CNN抽取的基于自底向上的注意力模型的输出作为图像的特征表示;2、基于注意力模型Transformer进行多模态推理,引入注意力模型对图片‑问题‑答案这个三元组进行多模态融合,建立推理关系;3、针对不同的隐含关系有不同的推理过程和结果输出,再根据这些结果输出来进行标签分布回归学习,来确定答案。本发明基于特定的图片和问题得到答案直接应用于服务于盲人的应用中,能

一种基于门的视频上下文多模态感知特征优化方法.pdf
一种基于门的视频上下文多模态感知特征优化方法,具体步骤为,步骤一:输入RGB视频序列和光流序列;步骤二:通过外观特征提取器和运动特征提取器提取得到双模态的基础特征;步骤三:输入双流特征优化结构;步骤四:通过连接的RGB特征优化记忆流和光流特征优化记忆流进行上下文和多模态的感知优化,得到对应的记忆流保留优化特征;步骤五:对RGB特征优化记忆流和光流特征优化记忆流保留特征进行串联,得到对应模态的优化特征;步骤六:对RGB特征优化特征和光流特征优化特征进行通道融合,形成视频级的特征表征。

面向智能交互的视觉问答研究综述.pptx
汇报人:/目录0102研究背景研究意义研究目的03视觉问答的定义与分类视觉问答的常用方法视觉问答的评估指标当前研究的挑战与问题04智能交互的定义与特点面向智能交互的视觉问答研究现状面向智能交互的视觉问答关键技术面向智能交互的视觉问答应用场景05深度学习在视觉问答中的应用多模态信息融合在视觉问答中的发展大规模视觉问答数据集的构建与挑战未来研究的重点与方向06研究成果总结对未来研究的建议与展望汇报人:

一种基于图文交互的多模态数据融合方法.pdf
本发明公开了一种基于图文交互的多模态数据融合方法,包括如下步骤:S1、获取多模态数据,所述多模态数据包括巡检图像数据和设备状态数据;S2、通过卷积神经网络获取巡检图像的图像特征图;S3、通过文本抽取器对设备状态数据进行预处理得到文本特征图;S4、构建多头注意力模块获取文本注意力权重和图像注意力权重;S5、基于文本注意力权重和图像注意力权重获取图像文本混合特征;S6、通过多头交叉注意力模块获取训练数据和目标的双向交互式信息;S7、通过特征图混合模块得到混合特征图信息并输出预测结果。方案通过对多模态特征进行融