
一种基于深度学习的人声检测算法.pdf

是丹****ni


1/9

2/9

3/9

4/9

5/9

6/9

7/9
8/9
9/9
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于深度学习的人声检测算法.pdf
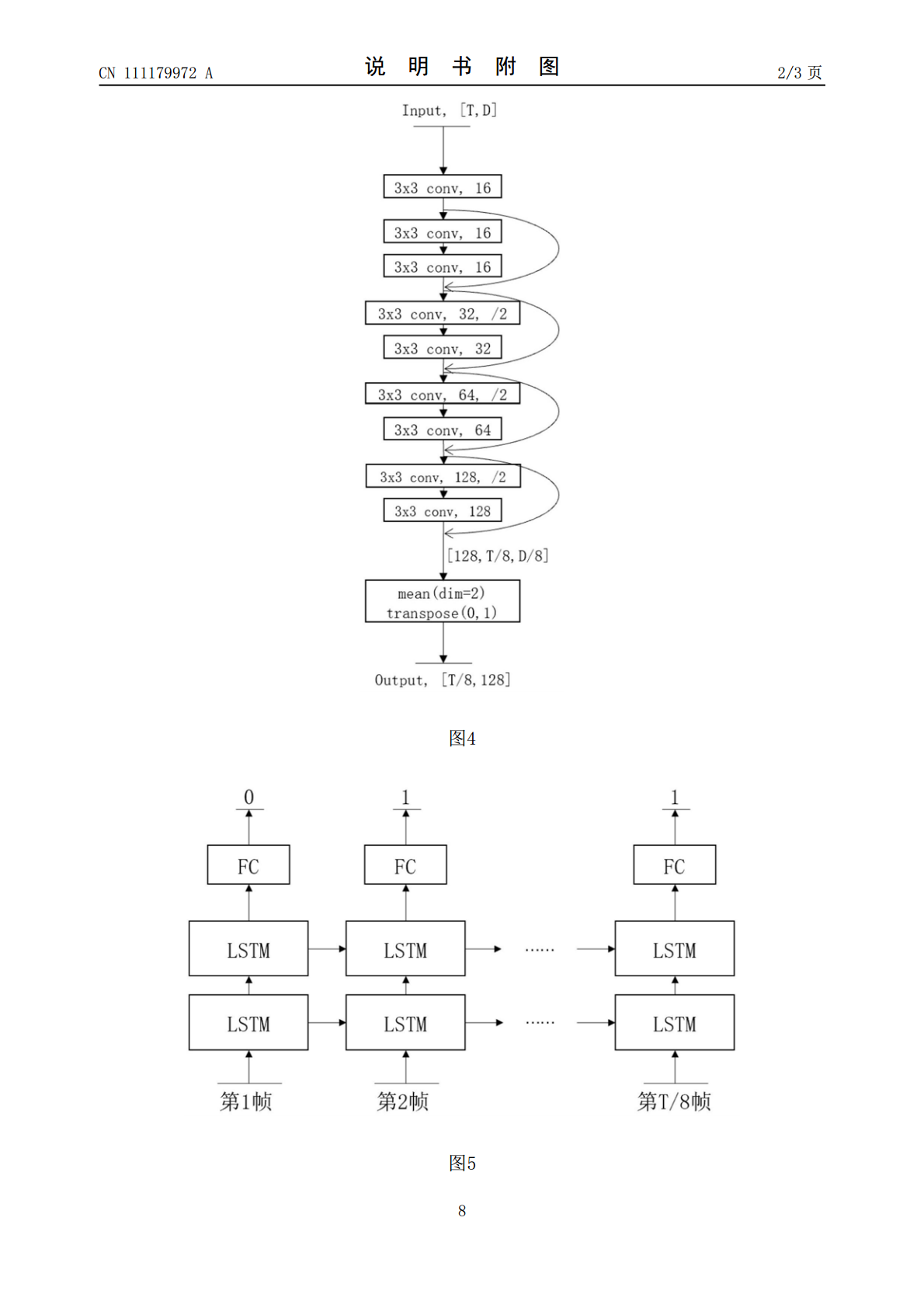
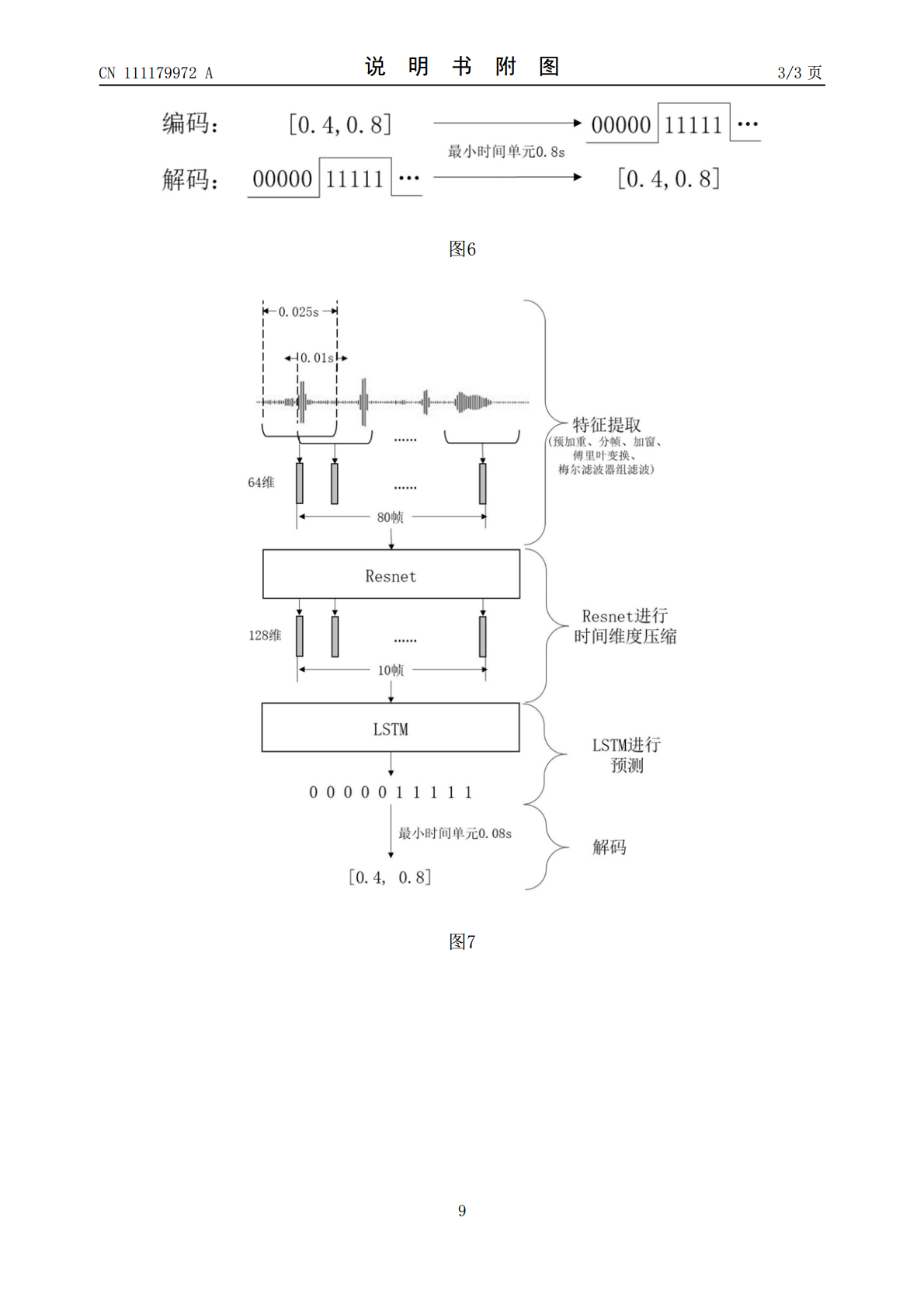
本发明涉及一种基于深度学习的人声检测算法。包括特征提取器、Resnet网络以及LSTM网络;所述的特征提取器用于从输入音频信号中提取梅尔频谱特征;所述的Resnet网络用于将连续输入的梅尔频谱特征在时间维度上进行压缩,将输入的T帧特征降低为T/8帧的同时保留人声检测的信息,从而减少后续LSTM的计算量;所述的LSTM网络采用两层的LSTM网络级联,输出连接全连接层后得到当前输入帧是否有人说话的预测,1表示有人说话,0则反之。本发明提供的一种基于深度学习的人声检测算法,加入了Resnet结构对信号在时间维度

一种基于深度学习的夜间行人检测算法.pdf
本发明涉及一种基于深度学习的夜间行人检测算法,属于目标检测技术领域。首先针对因夜间图像的弱光照特性导致的无法区分前景与背景问题,使用Zero‑DCE算法进行光照增强,以便于后续检测;然后针对YoloV4算法在夜间场景下特征提取能力不足的问题,提出双主干网络改进方案;最后改进特征融合模块,加强不同层特征图之间的信息流通。本发明采用以上方案构成夜间行人检测算法法,实现了比YoloV4算法更好的检测效果,为车辆辅助驾驶、智能机器人等研究方向提供技术支持。

一种基于深度学习算法的工位目标检测系统.pdf
本发明公开了一种基于深度学习算法的工位目标检测系统,包括:数据存储模块、目标识别模块、结果标识模块和结果纠正模块。本发明提供的基于深度学习算法的工位目标检测系统通过结果纠正模块对目标识别模块中数据对比结果进行人为判断,并对对比结果进行纠正,通过深度学习算法优化目标识别模块的识别算法,提高目标识别精度,即结果标识的准确性。

基于深度学习的阴影检测算法.docx
基于深度学习的阴影检测算法基于深度学习的阴影检测算法摘要阴影检测是计算机视觉领域中的一个重要任务,对于许多应用场景具有重要意义,如自动驾驶、智能视频监控等。然而,传统的阴影检测算法通常依赖于手工设计的特征或规则,其性能较差。随着深度学习的兴起,基于深度学习的阴影检测算法逐渐受到研究者的关注。本文提出了一种基于深度学习的阴影检测算法,通过使用深度卷积神经网络(DCNN)来学习特征表示,并采用全卷积神经网络(FCN)进行像素级别的阴影检测。实验证明,所提出的算法在不同场景和光照条件下都具有较高的检测准确率和鲁

一种基于AI深度学习算法的表面缺陷检测方法.pdf
本发明公开了一种基于AI深度学习算法的表面缺陷检测方法,包括如下步骤:建立基础卷积神经分类网络,并插入Coordinate注意力机制模块,然后在大型数据集图像网上进行预训练获得预训练权重,保存权重;将待检测图片输入建立的卷积神经网络,获得多个特征图与注意力图;由得到的注意力图指导进行数据增强;将获取到的注意力图与特征图进行双线性注意力叠加的全局平均池化,以得到特征向量,而后拼接成为特征矩阵;构建网络的损失函数,设置网络的超参数并采用带有弱标签的数据集以进行训练。本发明通过替代的弱注释来减少人类在图像标记方