
基于异构平台的高性能Linpack基准测试程序优化方法和设备.pdf

元枫****文章


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于异构平台的高性能Linpack基准测试程序优化方法和设备.pdf
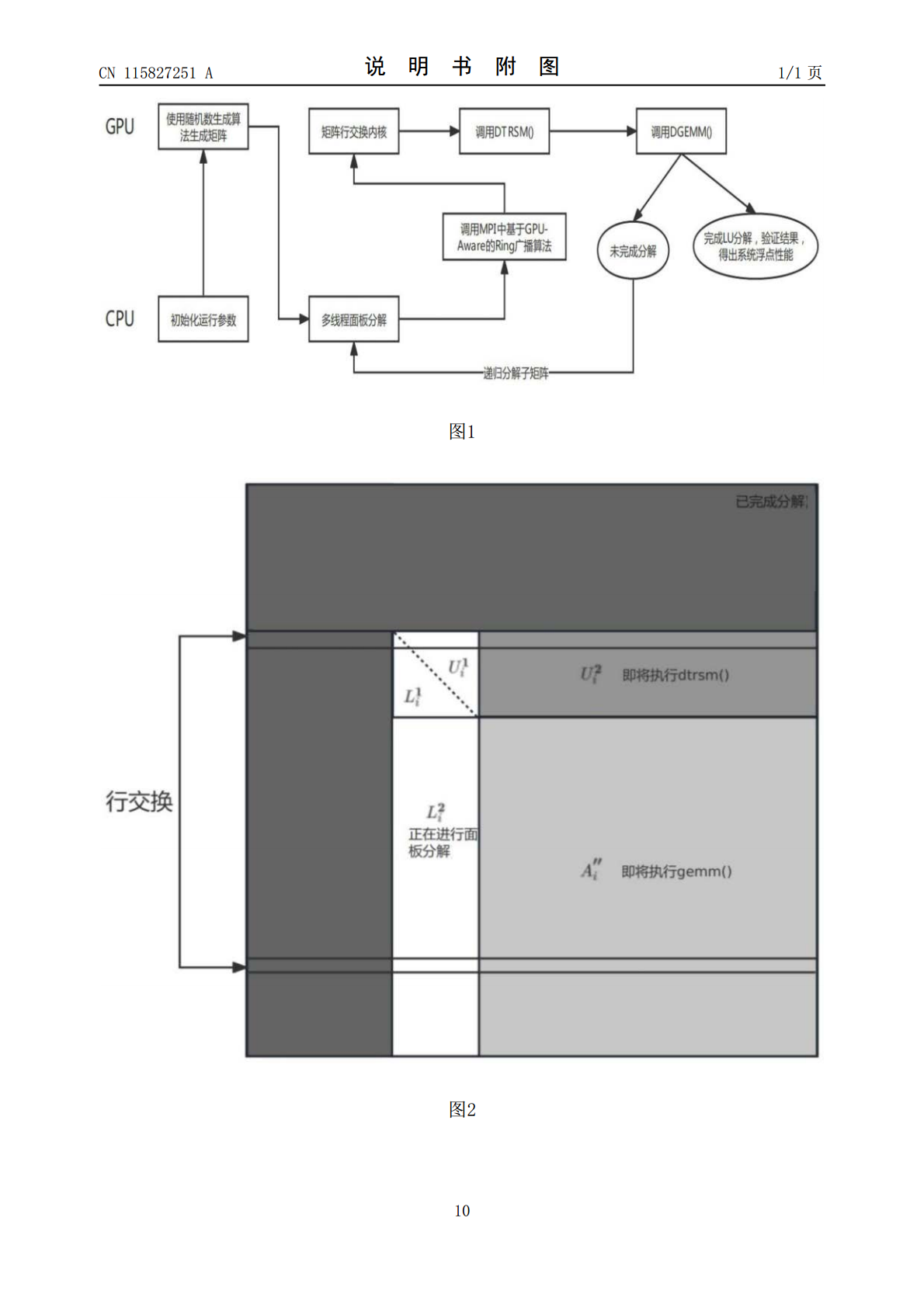
本发明面向高性能计算领域,为基于异构平台的高性能Linpack基准测试程序优化方法和设备。该方法包括:根据配置文件初始化HPL的运行参数,使用随机数生成算法生成设定规模的矩阵;以OpenMP多线程并行化的方式在CPU上执行面板分解过程;使用基于GPU‑Aware的Ring广播算法将分解完成的面板数据以及矩阵行交换信息广播至位于同一行的其余列进程;调用自定义内核对存放在显存中的矩阵完成行交换操作;GPU使用接收到的面板矩阵数据更新剩余的矩阵数据,更新上三角矩阵和尾随矩阵;调用定时函数计算矩阵完成分解的总时间

异构高性能计算系统Linpack效率受限因素分析.docx
异构高性能计算系统Linpack效率受限因素分析异构高性能计算系统(HeterogeneousHighPerformanceComputingSystem)是一种采用多个不同类型的处理器或加速器来共同解决计算问题的计算系统。在这种系统中,不同处理器的性能和能力存在差异,但通过合理的任务划分和调度可以充分发挥整个系统的计算能力。Linpack效率是衡量计算系统性能的重要指标之一,它通过测量解线性代数方程组的能力来评估计算系统的性能水平。然而,在异构高性能计算系统中,Linpack效率可能会受到多种因素的限制

Nehalem平台的Linpack参数训练与优化.docx
Nehalem平台的Linpack参数训练与优化随着计算机程序的日益复杂,需要更高效的计算能力去支持和处理复杂的数据计算。在此背景下,高性能计算成为计算机科学发展的一个重要分支领域。其中,Linpack参数训练与优化是提高高性能计算机运行速度的一个重要步骤。1.Linpack简介Linpack是一种有名的数值线性代数库,主要用于求解大规模的稠密矩阵方程。尤其在高性能计算领域中,Linpack表现得尤为突出。这主要得益于Linpack能够对超级计算机的计算性能进行全面评测。Linpack测试所测得的实测峰值

HPC高性能计算平台Linpack测试手册-以太网络.pdf
Linpack测试手册(1)千兆以太网:Step1:安装MPICH2将MPICH2安装包放到/hpc目录下,运行:tar–xvfmpich2-1.0.2p1.tarcdmpich2-1.0.2p1创建MPICH2安装目录:mkdir/hpc/mpich2设置MPICH2安装目录:./configure--prefix=/hpc/mpich2配置完成后makemakeinstall安装完成后退出当前目录进入/root目录编辑环境变量文件cd/rootvi.bashrc在文件最后附加一行PATH="$PATH

HPC高性能计算平台Linpack测试手册-以太网络.pdf
Linpack测试手册(1)千兆以太网:Step1:安装MPICH2将MPICH2安装包放到/hpc目录下,运行:tar–xvfmpich2-1.0.2p1.tarcdmpich2-1.0.2p1创建MPICH2安装目录:mkdir/hpc/mpich2设置MPICH2安装目录:./configure--prefix=/hpc/mpich2配置完成后makemakeinstall安装完成后退出当前目录进入/root目录编辑环境变量文件cd/rootvi.bashrc在文件最后附加一行PATH="$PATH