
基于规则的中文分词与地址匹配.ppt

可爱****乐多


1/10

2/10

3/10
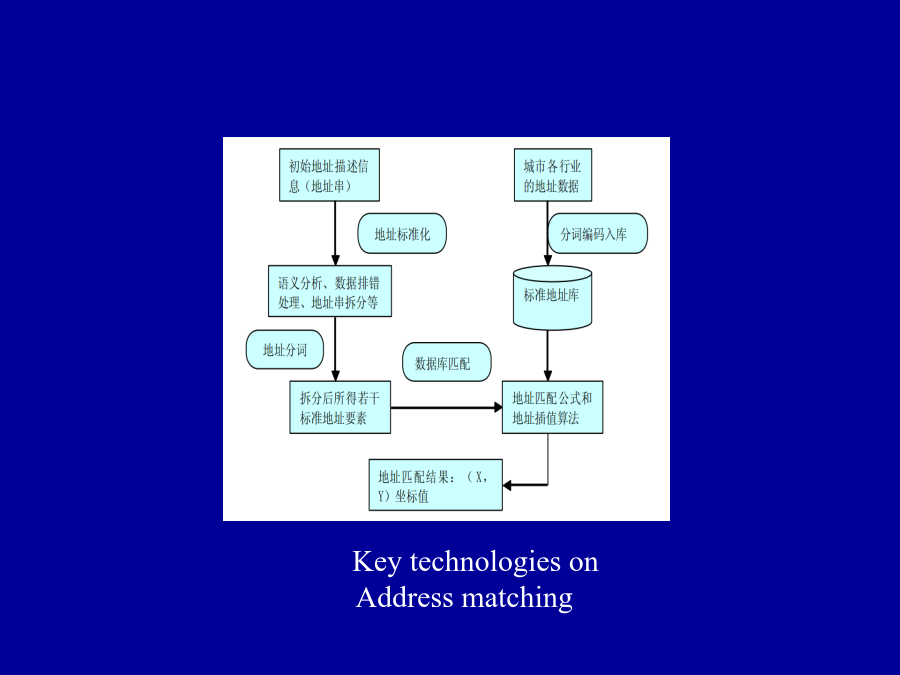
4/10
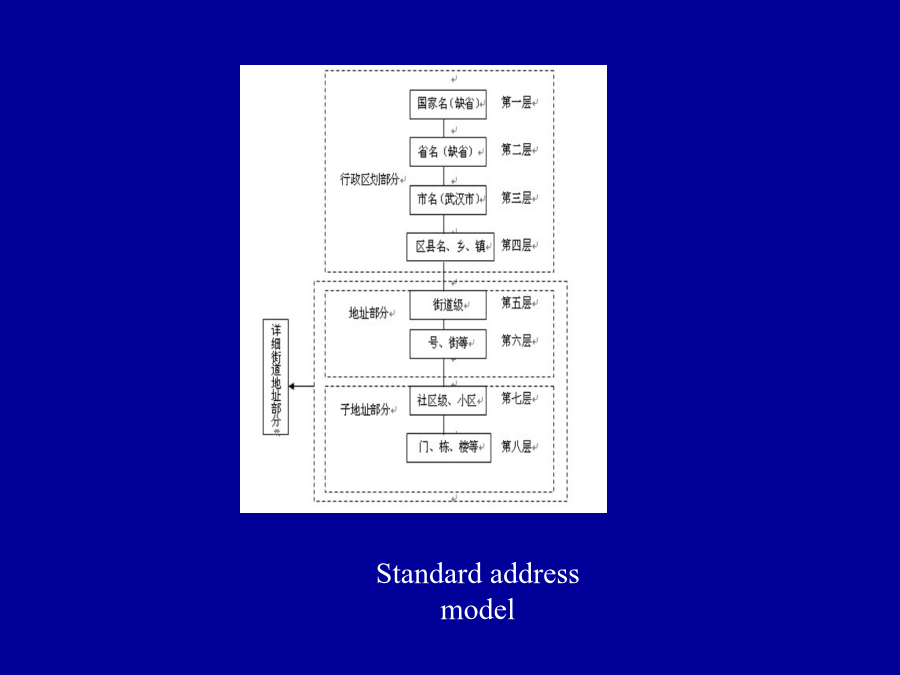
5/10
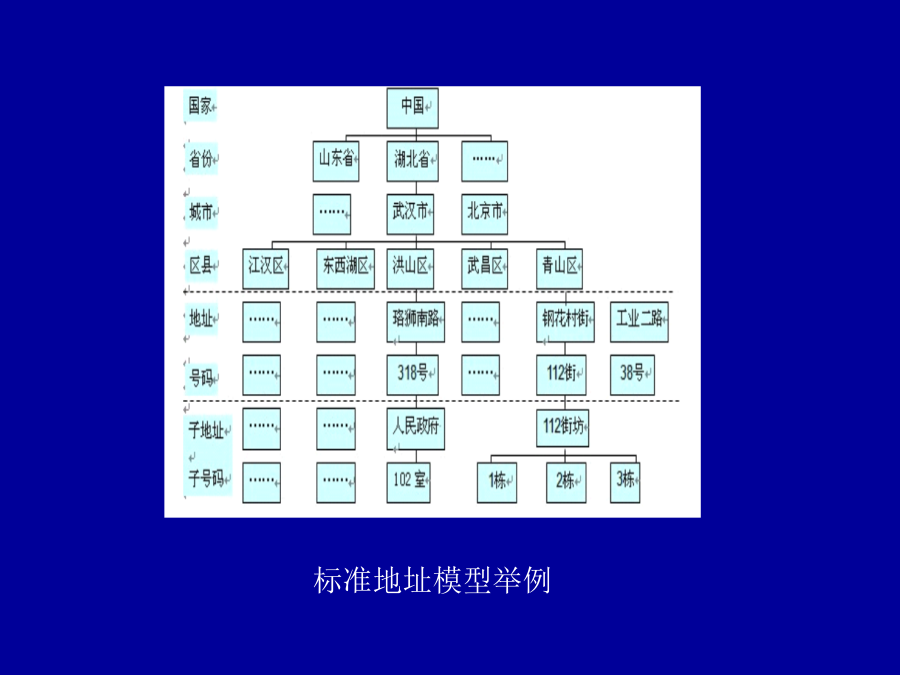
6/10

7/10

8/10
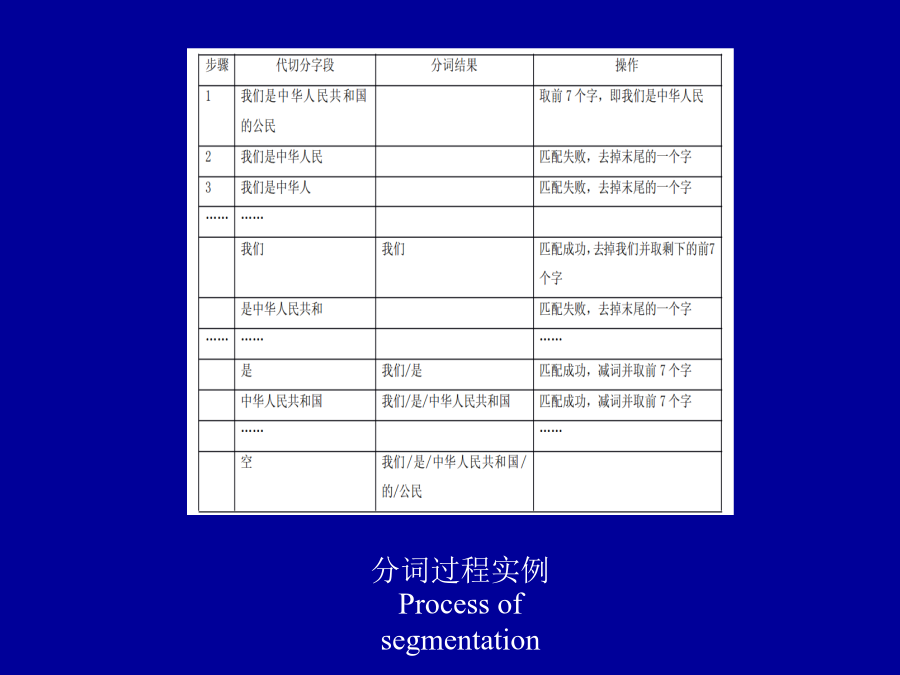
9/10

10/10
亲,该文档总共16页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于规则的中文分词与地址匹配.ppt
基于规则的中文地址分词与匹配方法研究背景及意义随着地理信息系统(GIS)的不断发展和其在各行业的广泛应用,人们对信息共享的要求也越来越迫切。例如在城市管网、交通导航、工商管理、公共卫生、灾害管理等领域,地理信息系统作为信息共享的平台,其应用越来越广泛。城市各行业的数据库都保存着大量和地理位置有关的非空间数据。但是这些行业建设的GIS系统并没有足够的空间位置数据进行支撑,因为地址数据并不能够批量、准确地转化为空间化的信息。这些数据大多都没有空间位置坐标,无法对应到电子地图上,也就无法进行空间分析和管理决策。

基于BERT的中文地址分词方法.pptx
汇报人:目录PARTONEPARTTWOBERT模型的基本原理BERT模型在中文分词上的应用BERT模型的优势与局限性PARTTHREE中文地址的复杂性分词的难点与挑战现有分词方法的不足PARTFOUR方法概述数据预处理与标注BERT模型训练与优化分词效果评估与改进PARTFIVE实验设置与数据集实验结果对比与分析分词效果的可视化展示性能优化与未来工作PARTSIX在地址匹配与标准化中的应用在智能物流与配送中的应用在智能客服与地址解析中的应用未来研究方向与挑战THANKYOU

基于规则与词典的地址匹配算法.docx
基于规则与词典的地址匹配算法随着信息时代的到来,大量的信息需要进行处理。其中,数据的归类和处理是其中一个关键的环节。而对于各种数据中,地址信息是一个很常见的数据类型。由于地址信息的不规则性以及在不同平台和领域中的多样性,地址匹配成为一个经典的问题。对于地址匹配问题,基于规则与词典的算法是一种很常见的解决方案。本文首先介绍了地址匹配问题的背景和意义。然后,介绍了基于规则与词典的地址匹配算法的基本思路和实现方法。接下来,我们将讨论该算法的优缺点以及适用范围。最后,我们将对该算法的未来发展做出展望。一、地址匹配

基于街道的地址匹配规则研究.docx
基于街道的地址匹配规则研究基于街道的地址匹配规则研究摘要:随着互联网的发展以及电子商务的兴起,地址匹配在物流配送、地理信息系统以及电子商务等领域中变得越来越重要。本文将探讨基于街道的地址匹配规则的研究,并提出一种改进的街道地址匹配算法。通过对现有的地址匹配方法进行研究和分析,我们发现在复杂的居民区和商业区,地址字符串的规范化和标准化是解决地址匹配问题的关键。因此,我们提出一种基于街道的地址匹配规则,通过对街道名称和门牌号的特征进行提取和分析,实现地址标准化和匹配。1.引言地址匹配是将用户提供的地址与地图数

基于中文分词的地址匹配技术在警用地理信息系统中的应用.docx
基于中文分词的地址匹配技术在警用地理信息系统中的应用摘要:通过对基于盘古分词的地址匹配研究结合重庆市地址名称的特殊性对盘古分词功能进行了扩展并进行了词库的建设和索引的优化并以此为基础在警用地理信息系统中进行了成功的应用。关键词:盘古分词地址匹配警用地理信息系统中图分类号:TP391.1文献标识码:A文章编号:1674-098X(2013)01(b)-00-03地址匹配也称地理编码是指将地址映射成地理坐标的过程是用户输入一个地址串即可返回其