
应用统计学数据管理.ppt

知识****SA


1/10

2/10
3/10

4/10

5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共90页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

应用统计学数据管理.ppt
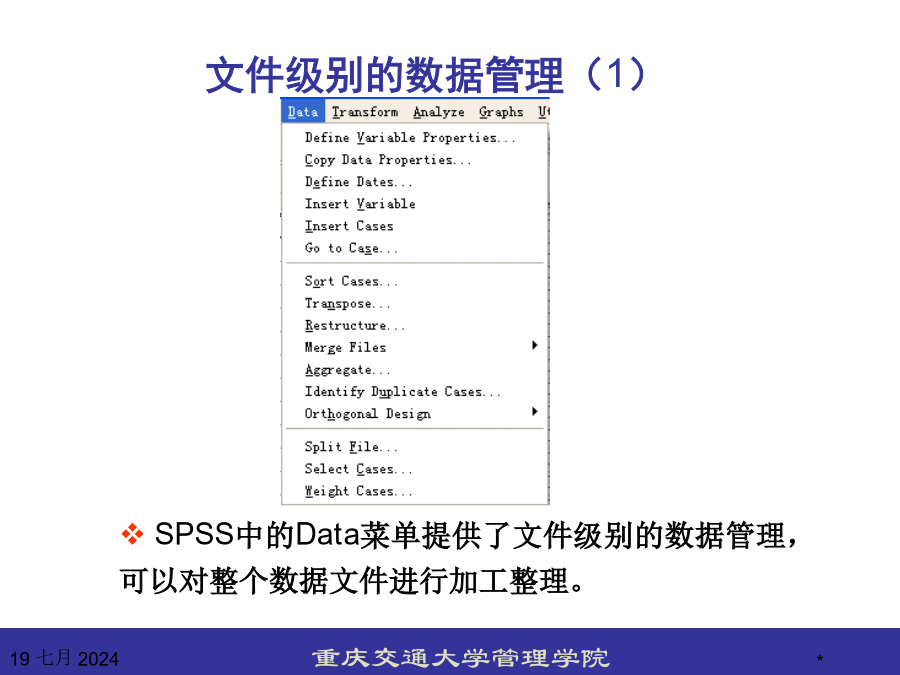
在数据文件建立好之后,还需要对数据进行必要的加工处理。对同一个数据往往需要从各种不同的侧面进行研究,采取多种统计方法进行分析,而不同的统计方法对数据文件结构的要求不尽相同,这就需要对数据文件的结构进行重新调整或转换,以便适合于相同的统计方法。文件级别的数据管理(1)InsertVariable:插入变量InsertCases:插入记录GotoCase:到达某条记录DefineVariableProperties:定义数据字典CopyVariableProperties:将预定义的数据字典直接引入当前数据文

管理统计学SPSS数据管理-实验报告.doc
数据管理实验目的与要求1.掌握计算新变量、变量取值重编码的基本操作。2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作。3.了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。二、实验内容提要1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作2.针对SPSS自带数据Employeedata.sav进行以下练习。(1)根据变量bdate生成一个新变量“年龄”(2)根据jobcat分组计算salary的秩次(3)根据雇员的性别变量对salary的平均值进行汇总(4)生成新变量grade

管理统计学SPSS数据管理-实验报告.doc
数据管理实验目的与要求1。掌握计算新变量、变量取值重编码的基本操作。2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作.3。了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。二、实验内容提要1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作2.针对SPSS自带数据Employeedata。sav进行以下练习。(1)根据变量bdate生成一个新变量“年龄”(2)根据jobcat分组计算salary的秩次(3)根据雇员的性别变量对salary的平均值进行汇总(4)生成新变量grade

管理统计学SPSS数据管理-实验报告.doc
数据管理实验目的与要求1。掌握计算新变量、变量取值重编码的基本操作。2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作.3。了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。二、实验内容提要1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作2.针对SPSS自带数据Employeedata。sav进行以下练习。(1)根据变量bdate生成一个新变量“年龄”(2)根据jobcat分组计算salary的秩次(3)根据雇员的性别变量对salary的平均值进行汇总(4)生成新变量grade

大数据管理与应用.pdf
大数据管理与应用随着科技的发展、互联网的进入千家万户,数据已不再是一个分立的单元,而是成为了我们生活中的一个重要组成部分,从个人数据到企业运营数据、领导公共数据等等,大量数据的储存和管理已成为了一项必要工作,而大数据的应用也已经成为了人们与未来交互、创新和挑战的新传统。本文将从大数据的定义与特点、大数据管理与应用的意义、大数据管理与应用的方法和未来大数据发展等几个方面展开论述。第一部分:大数据的定义与特点大数据的定义与特点:大数据是一种由海量数据、高速数据以及多样化的数据构成的数据集合。大数据具有数据量极