
基于Python的自然语言数据处理系统的设计与实现.pdf

桂香****盟主


1/6

2/6

3/6

4/6

5/6

6/6
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于Python的自然语言数据处理系统的设计与实现.pdf
基于Python的自然语言数据处理系统的设计与实现打开文本图片集摘要随着云时代的来临大数据技术将具有越来越重要的战略意义很多组织通常都会用一种领域特定的计算语言像Python、R和传统的MATLAB将其用于对新的想法进行研究和原型构建之后将其移植到某个使用其他语言编写大的系统中去如Java、Python等语言慢慢经验的积累人们意识到Python

基于Python的自然语言数据处理系统的设计与实现.pdf
基于Python的自然语言数据处理系统的设计与实现打开文本图片集摘要随着云时代的来临大数据技术将具有越来越重要的战略意义很多组织通常都会用一种领域特定的计算语言像Python、R和传统的MATLAB将其用于对新的想法进行研究和原型构建之后将其移植到某个使用其他语言编写大的系统中去如Java、Python等语言慢慢经验的积累人们意识到Python
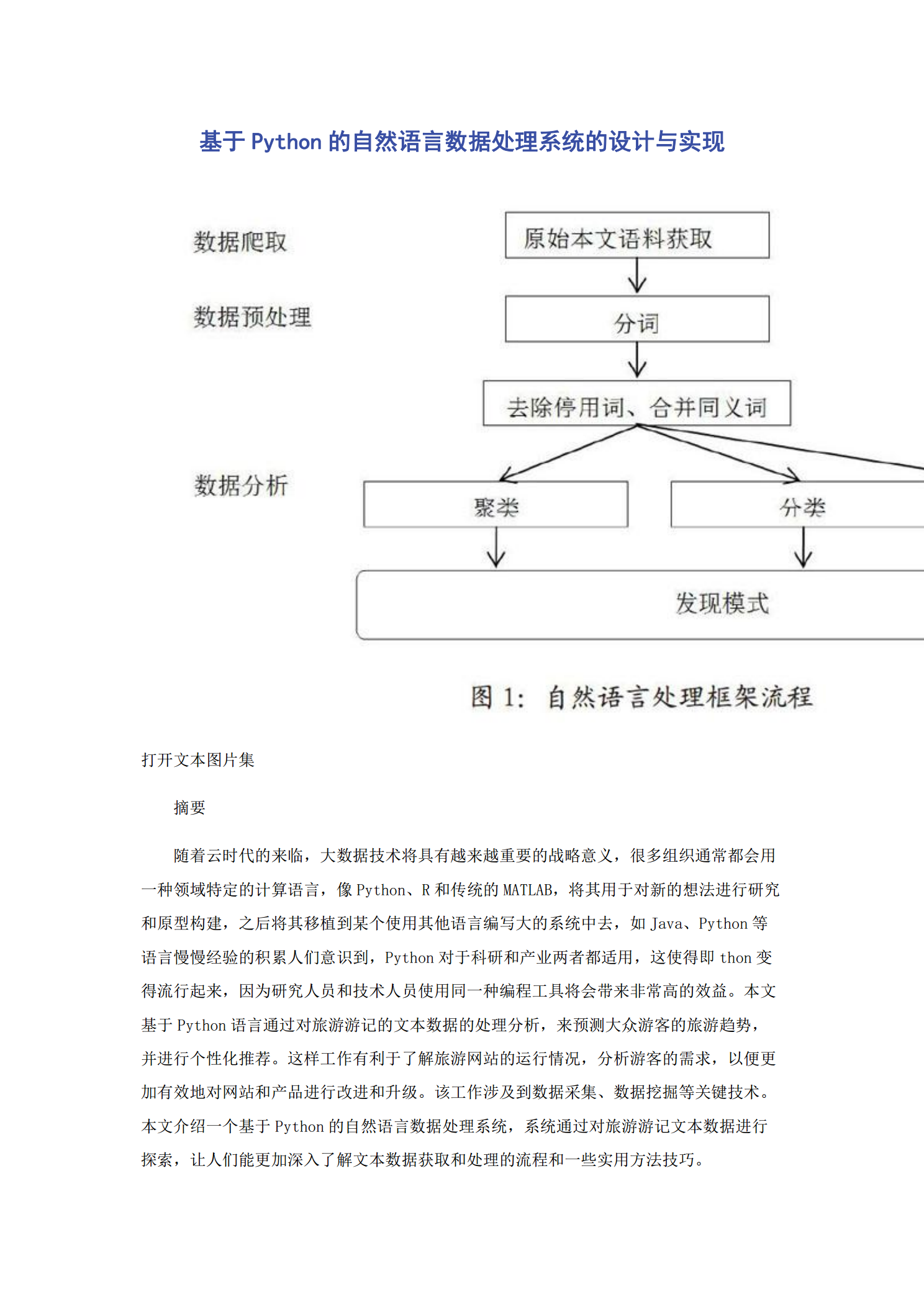
基于Python的自然语言数据处理系统的设计与实现.pdf
基于Python的自然语言数据处理系统的设计与实现打开文本图片集摘要随着云时代的来临,大数据技术将具有越来越重要的战略意义,很多组织通常都会用一种领域特定的计算语言,像Python、R和传统的MATLAB,将其用于对新的想法进行研究和原型构建,之后将其移植到某个使用其他语言编写大的系统中去,如Java、Python等语言慢慢经验的积累人们意识到,Python对于科研和产业两者都适用,这使得即thon变得流行起来,因为研究人员和技术人员使用同一种编程工具将会带来非常高的效益。本文基于Python语言通过对旅

基于python的物理实验数据处理系统设计与实现.pdf
python的物理实验数据处理系统设计与实现随着科技的不断发展,物理实验数据处理系统已经成为了物理实验教学和科研工作中必不可少的重要工具。本文将介绍一种基于Python的物理实验数据处理系统的设计与实现。一、需求分析在设计物理实验数据处理系统之前,我们需要先明确其需求。根据实际需求,我们需要实现以下功能:1.数据采集:能够对实验数据进行采集,支持多种数据采集方式,如模拟信号采集、数字信号采集等。2.数据处理:能够对采集到的实验数据进行处理,包括数据分析、数据拟合等。3.数据存储:能够将处理后的数据保存到文

基于python的物理实验数据处理系统设计与实现11888.pdf
python的物理实验数据处理系统设计与实现随着科技的不断发展,物理实验数据处理系统已经成为了物理实验教学和科研工作中必不可少的重要工具。本文将介绍一种基于Python的物理实验数据处理系统的设计与实现。一、需求分析在设计物理实验数据处理系统之前,我们需要先明确其需求。根据实际需求,我们需要实现以下功能:1.数据采集:能够对实验数据进行采集,支持多种数据采集方式,如模拟信号采集、数字信号采集等。2.数据处理:能够对采集到的实验数据进行处理,包括数据分析、数据拟合等。3.数据存储:能够将处理后的数据保存到文