
孤立汉语数字语音识别系统.pdf

文库****品店


1/5
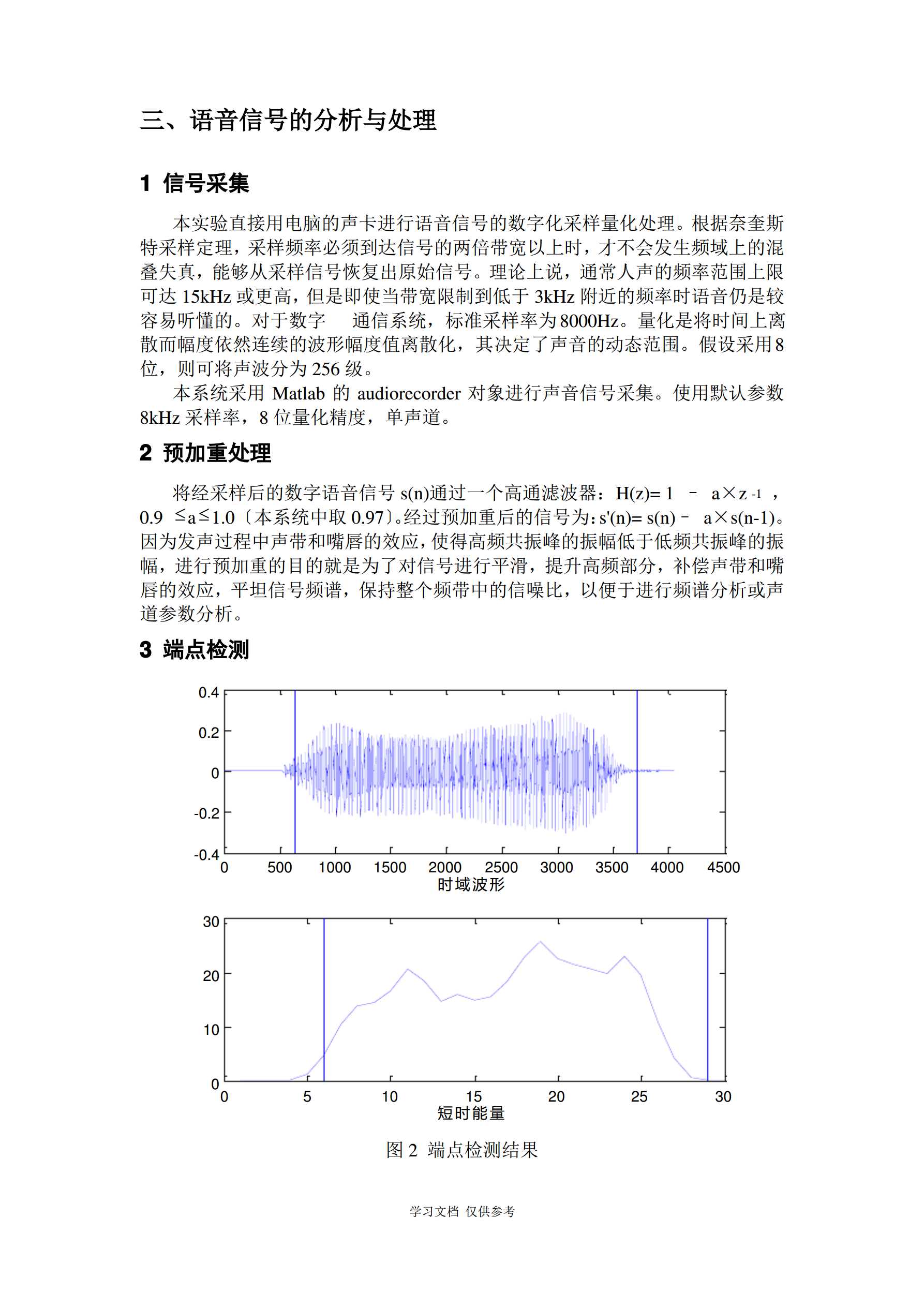
2/5
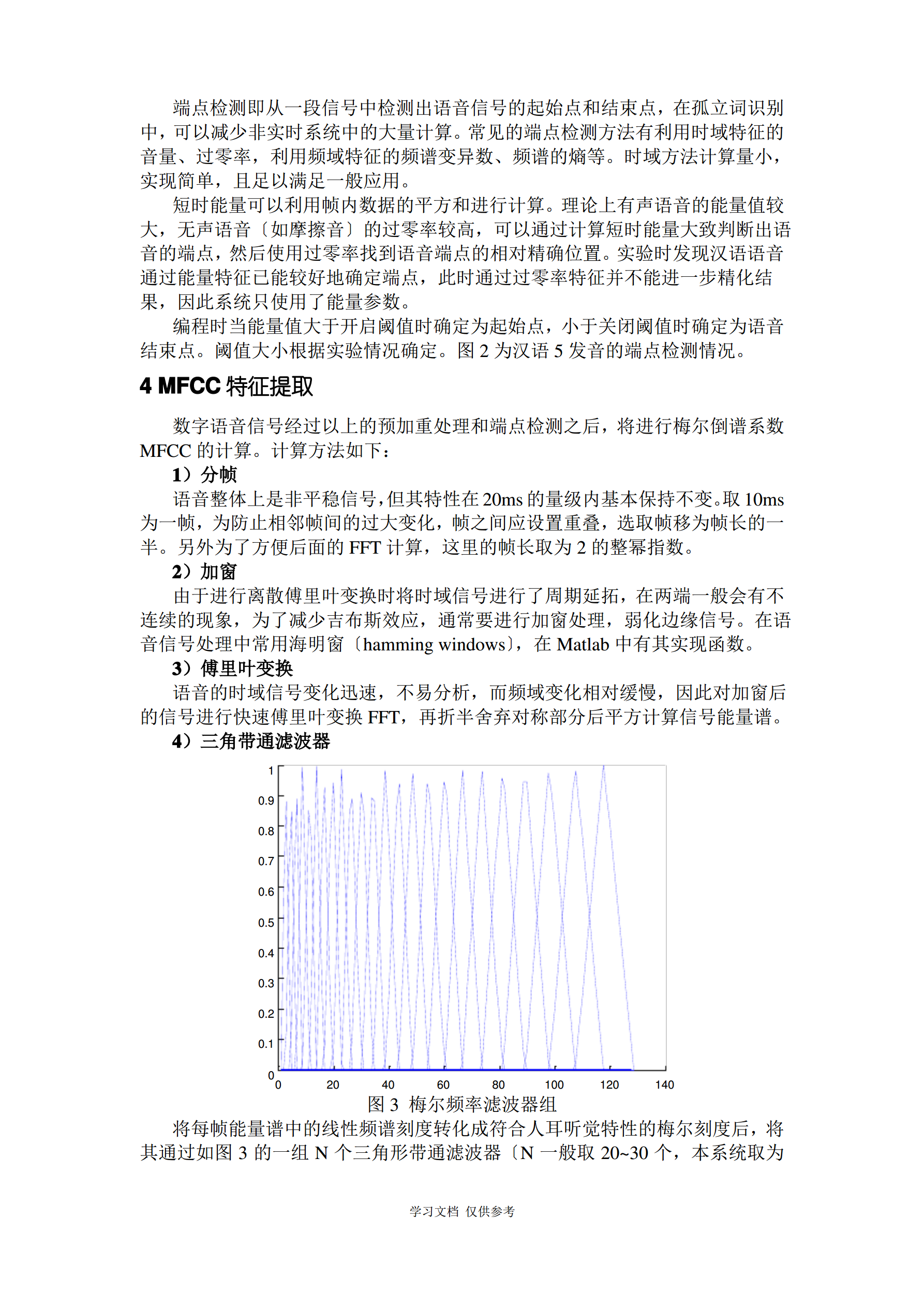
3/5

4/5
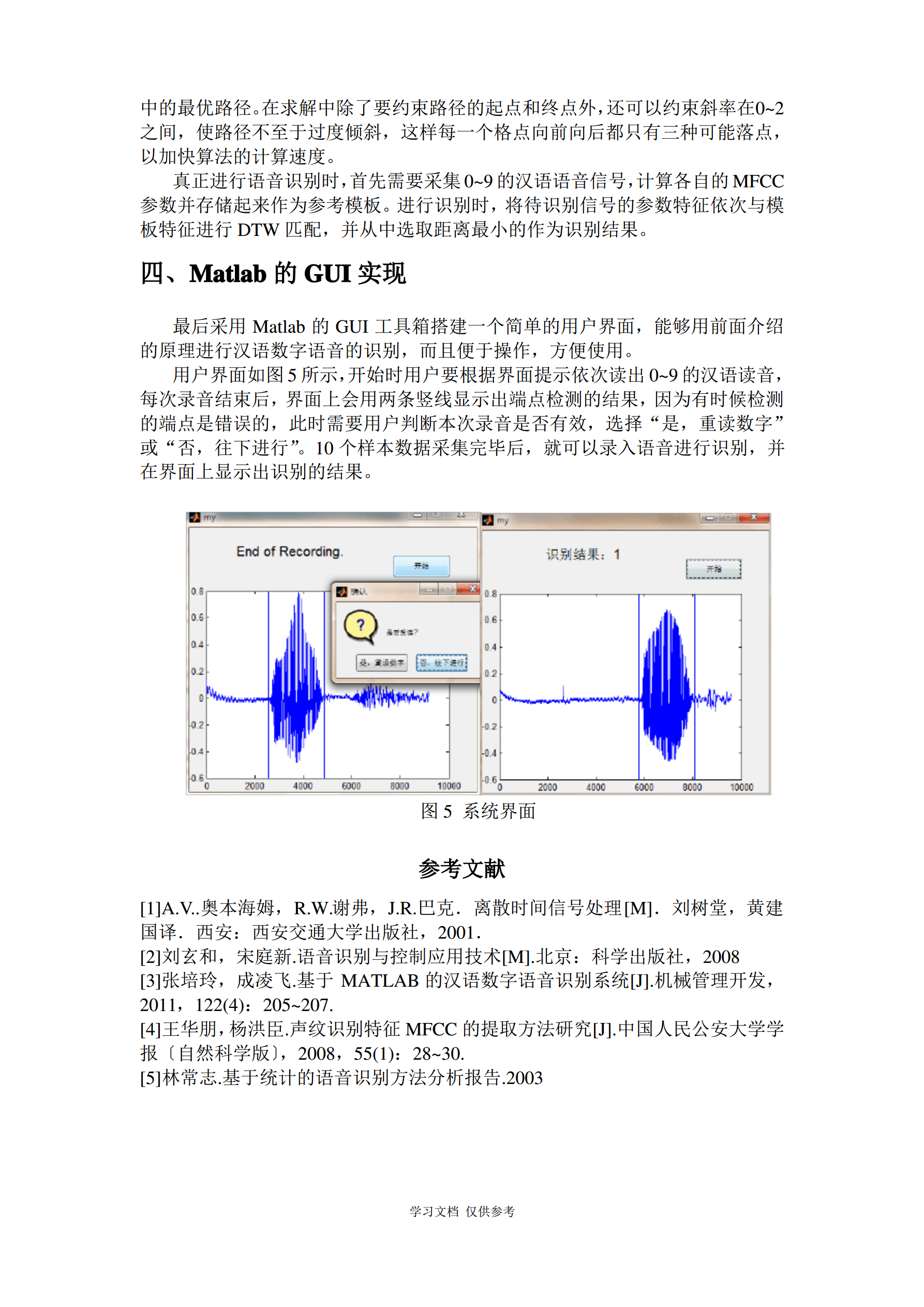
5/5
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

孤立汉语数字语音识别系统.pdf
孤立汉语数字语音识别系统摘要:本文通过提取声音信号的Mel倒谱系数作为特征,利用动态时间规整技术实现匹配算法,实现了特定人孤立汉语数字语音的识别,并利用Matlab编写了简单的图形用户界面。关键词:语音识别;MFCC;DTW一、引言语言是人类所特有的最重要最自然的交流工具,也是人类信息的重要来源之一。让机器拥有“听懂”人类口述语言的能力,将使得人与电脑之间的沟通变得更为方便快捷。自从1952年AT&T贝尔实验室的开发出能识别十个英文数字的Audry系统以来,语音识别技术已经得到了飞速发展,其中IBM、Mi

孤立语音识别系统的实验研究.docx
孤立语音识别系统的实验研究孤立语音识别系统的实验研究摘要随着科技的不断发展和应用的广泛推广,语音识别技术在日常生活中得到了越来越广泛的应用。而孤立语音识别系统作为其中的一种重要技术手段,具有一定的研究意义和应用价值。本文旨在通过实验研究,探讨孤立语音识别系统的关键技术和性能指标,并提出一种有效的系统配置和参数调优方法,以提高孤立语音识别系统的识别准确度。关键词:语音识别;孤立语音;系统配置;参数调优;准确度引言语音识别技术是指通过计算机对人的语言进行识别和理解的技术。随着科技的发展,语音识别技术已广泛应用

基于DTW的孤立词语音识别系统设计.docx
基于DTW的孤立词语音识别系统设计基于DTW的孤立词语音识别系统设计摘要:近年来,孤立词语音识别系统在语音识别领域中得到了广泛的应用。孤立词语音识别是指识别单个词语的语音信号,并将其转化为相应的文字或指令。本文介绍了一种基于动态时间规整(DynamicTimeWarping,DTW)的孤立词语音识别系统设计。该系统通过对语音信号进行特征提取和模板匹配两个主要步骤,实现了对孤立词的准确识别。实验结果表明,该系统具有较高的准确率和稳定性,适用于实际应用。关键词:孤立词语音识别;动态时间规整;特征提取;模板匹配

基于人工神经网络的汉语数字语音识别系统.pdf
广西科学:~基于人工神经网络的汉语数字语音识别

基于人工神经网络的汉语数字语音识别系统.pdf
广西科学:~基于人工神经网络的汉语数字语音识别