
聚类分析及MATLAB实现PPT资料.pptx

胜利****实阿


1/10

2/10

3/10

4/10
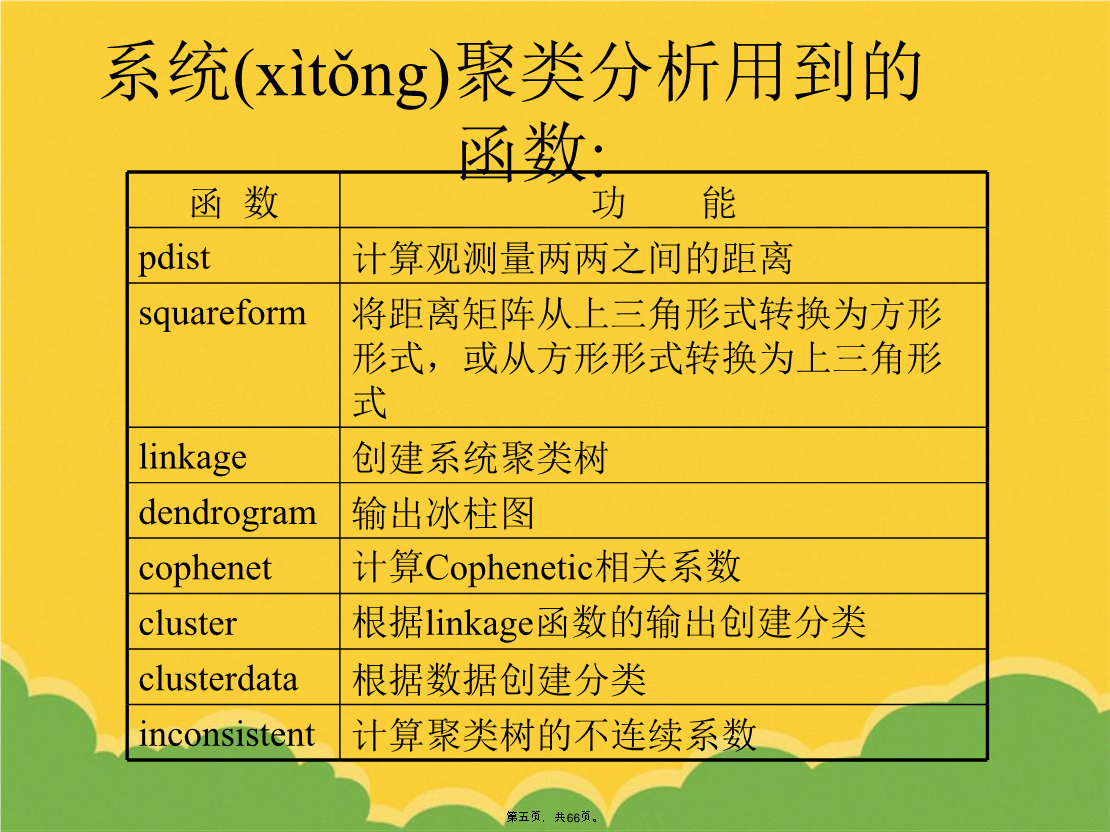
5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共66页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

聚类分析及MATLAB实现PPT资料.pptx
第4章聚类分析(clusteranalysis)统计(tǒngjì)方法(聚类分析):统计(tǒngjì)方法(系统聚类分析步骤):系统(xìtǒng)聚类分析:系统(xìtǒng)聚类分析用到的函数:聚类分析第七页,。聚类分析有两种:一种(yīzhǒnɡ)是对样品的分类,称为Q型,另一种(yīzhǒnɡ)是对变量(指标)的分类,称为R型。4.1样品(yàngpǐn)(变量)间相近性度量4.1.1聚类分析的基本思想设有n个样品的p元观测数据组成一个(yīɡè)数据矩阵4.1.2样品间的相似度量(dùlià

聚类分析和MATLAB实现ppt课件.ppt
第4章聚类分析(clusteranalysis)统计方法(聚类分析):统计方法(系统聚类分析步骤):系统聚类分析:系统聚类分析用到的函数:聚类分析.聚类分析有两种:一种是对样品的分类,称为Q型,另一种是对变量(指标)的分类,称为R型。4.1样品(变量)间相近性度量4.1.1聚类分析的基本思想设有n个样品的p元观测数据组成一个数据矩阵4.1.2样品间的相似度量—距离7.兰氏距离例1.为了研究辽宁、浙江、河南、甘肃、青海5省1991年城镇居民生活消费规律,需要利用调查资料对五个省进行分类,指标变量共8个,意义

聚类分析及MATLAB实现ppt课件.ppt
第4章聚类分析(clusteranalysis)统计方法(聚类分析):统计方法(系统聚类分析步骤):系统聚类分析:系统聚类分析用到的函数:聚类分析.聚类分析有两种:一种是对样品的分类,称为Q型,另一种是对变量(指标)的分类,称为R型。4.1样品(变量)间相近性度量4.1.1聚类分析的基本思想设有n个样品的p元观测数据组成一个数据矩阵4.1.2样品间的相似度量—距离7.兰氏距离例1.为了研究辽宁、浙江、河南、甘肃、青海5省1991年城镇居民生活消费规律,需要利用调查资料对五个省进行分类,指标变量共8个,意义

聚类分析和MATLAB实现(课堂PPT).ppt
第4章聚类分析(clusteranalysis)统计方法(聚类分析):统计方法(系统聚类分析步骤):系统聚类分析:系统聚类分析用到的函数:聚类分析7聚类分析有两种:一种是对样品的分类,称为Q型,另一种是对变量(指标)的分类,称为R型。4.1样品(变量)间相近性度量4.1.1聚类分析的基本思想设有n个样品的p元观测数据组成一个数据矩阵4.1.2样品间的相似度量—距离7.兰氏距离例1.为了研究辽宁、浙江、河南、甘肃、青海5省1991年城镇居民生活消费规律,需要利用调查资料对五个省进行分类,指标变量共8个,意义

聚类分析和MATLAB实现.ppt
第4章聚类分析(clusteranalysis)统计方法(聚类分析):统计方法(系统聚类分析步骤):系统聚类分析:系统聚类分析用到的函数:聚类分析2021/10/10聚类分析有两种:一种是对样品的分类,称为Q型,另一种是对变量(指标)的分类,称为R型。4.1样品(变量)间相近性度量4.1.1聚类分析的基本思想设有n个样品的p元观测数据组成一个数据矩阵4.1.2样品间的相似度量—距离7.兰氏距离例1.为了研究辽宁、浙江、河南、甘肃、青海5省1991年城镇居民生活消费规律,需要利用调查资料对五个省进行分类,指