
多应用音频渲染.pdf

婀娜****aj


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共42页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

多应用音频渲染.pdf
本文公开了用于有效地渲染音频的系统和方法。一种方法可包括:接收呈现第一音轨的请求,其中,第一音轨基于包括共享模型分量和第一模型分量的第一音频模型;接收呈现第二音轨的请求,其中,第二音轨基于包括共享模型分量和第二模型分量的第二音频模型;基于第一音轨、第二音轨、共享模型分量、第一模型分量和第二模型分量,渲染声音;以及经由一个或多个扬声器呈现包括所渲染的声音的音频信号。

多通道音频渲染.pdf
多通道音频渲染系统包括音频渲染器(113),其为多个音频通道生成音频信号。多个可互换的扬声器单元(101-109)包括电池(205)和音频换能器(207),用于渲染音频信号。充电单元(115)和特定的音频通道相关联并且包括能够给附着的扬声器单元(101-109)的电池充电的充电源。链接电路(305)能够在它被附着到充电单元(115)时将扬声器单元(101-109)链接到第一音频通道。该系统能够永久地将特定的通道和充电单元(或不能充电的无源扬声器基底)相关联,并且可互换的扬声器单元(101-109)能够根据

音频和视频的多模式同步渲染.pdf
选择媒体以用于通过第一设备进行视频回放和通过经由无线网络连接的一个或多个单独的设备进行音频回放。可以基于一个或多个因素来选择用于同步音频和视频的不同技术,以改善媒体回放。
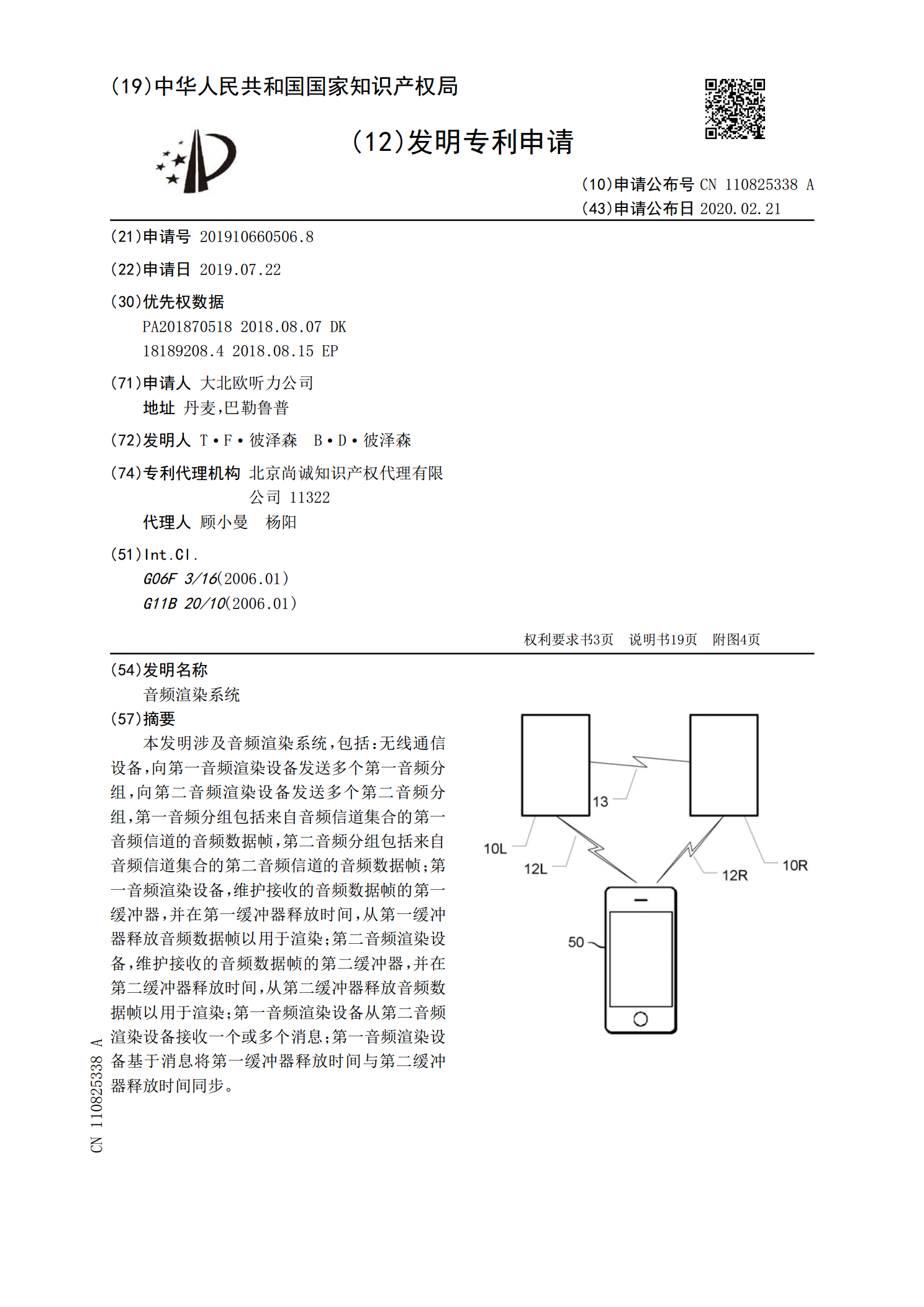
音频渲染系统.pdf
本发明涉及音频渲染系统,包括:无线通信设备,向第一音频渲染设备发送多个第一音频分组,向第二音频渲染设备发送多个第二音频分组,第一音频分组包括来自音频信道集合的第一音频信道的音频数据帧,第二音频分组包括来自音频信道集合的第二音频信道的音频数据帧;第一音频渲染设备,维护接收的音频数据帧的第一缓冲器,并在第一缓冲器释放时间,从第一缓冲器释放音频数据帧以用于渲染;第二音频渲染设备,维护接收的音频数据帧的第二缓冲器,并在第二缓冲器释放时间,从第二缓冲器释放音频数据帧以用于渲染;第一音频渲染设备从第二音频渲染设备接收

近场音频渲染.pdf
根据示例方法,识别与音频信号对应的源位置。确定与音频信号对应的声轴。对于用户的相应左耳和右耳中的每一个,确定声轴与相应耳朵之间的角度、确定与源位置和相应耳朵的位置共线的虚拟扬声器位置,其中虚拟扬声器位置位于与用户的头部同心的球体的表面上,该球体具有第一半径。确定与虚拟扬声器位置对应并与相应耳朵对应的头相关传递函数(HRTF);基于所确定的角度来确定源辐射滤波器;处理音频信号以针对相应耳朵生成输出音频信号;以及经由与可穿戴头部装置相关联的一个或多个扬声器向用户的相应耳朵呈现输出音频信号。