
基于isodata算法的Iris数据分类.doc

是笛****加盟


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共24页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于isodata算法的Iris数据分类.doc
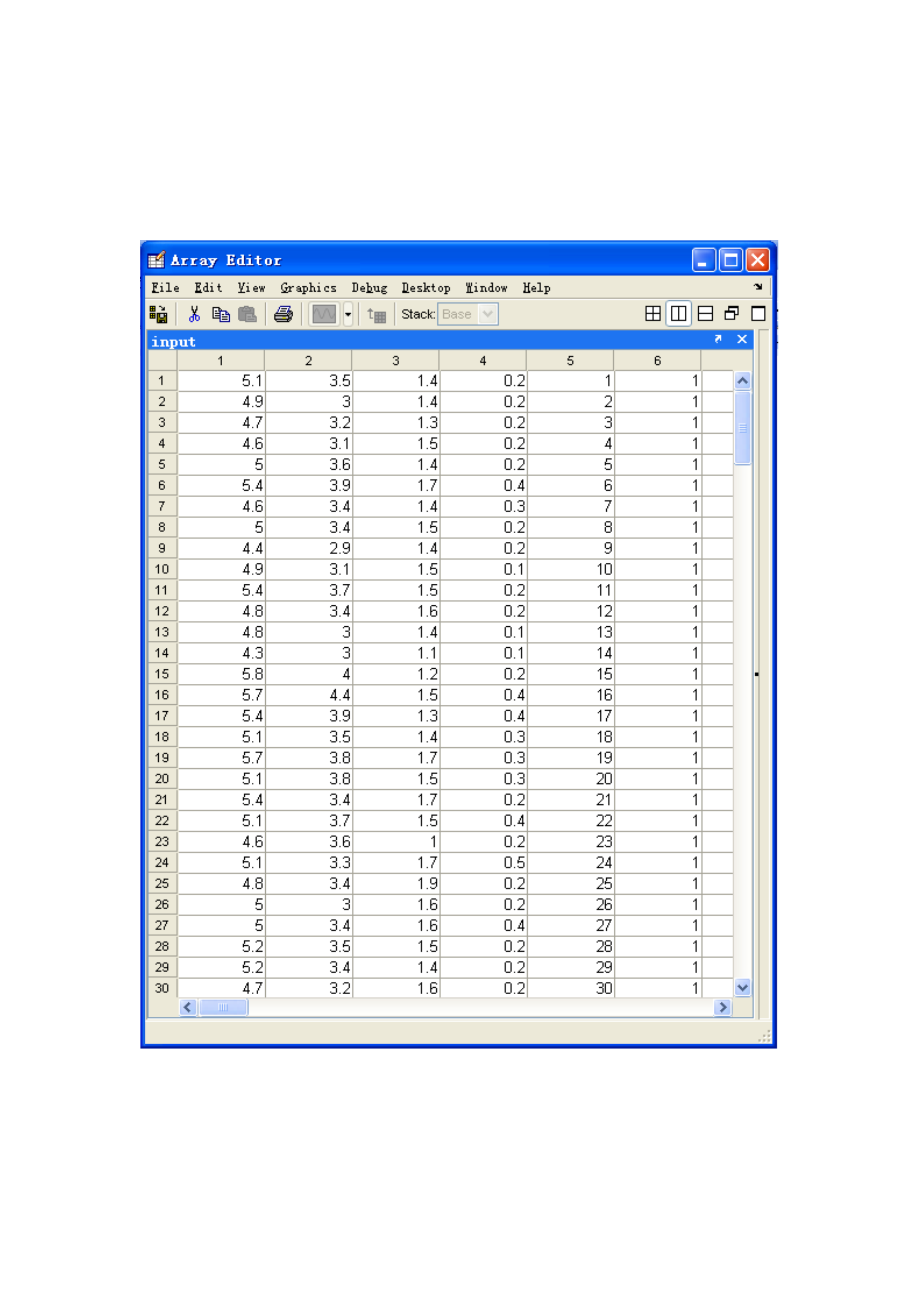
实验目的通过对Irisdata采用Isodata算法进行聚类掌握Isodata算法的原理以及具体实施步骤。二.实验原理C均值算法比较简单但它的自我调整能力也比较差。这主要表现在类别数不能改变受代表点初始选择的影响也比较大。ISODATA算法的功能与C均值算法相比在下列几方面有改进。1.考虑了类别的合并与分裂因而有了自我调整类别数的能力。合并主要发生在某一类内样本个数太少的情况或两类聚类中心之间距离太小的情况。为此设有最小类内样本数限制以及类间中心距离参数。若出现两类聚类中心距离小于的情况可考虑将此两

基于isodata算法的Iris数据分类.doc
实验目的通过对Irisdata采用Isodata算法进行聚类,掌握Isodata算法的原理以及具体实施步骤。二.实验原理C均值算法比较简单,但它的自我调整能力也比较差。这主要表现在类别数不能改变,受代表点初始选择的影响也比较大。ISODATA算法的功能与C均值算法相比,在下列几方面有改进。1.考虑了类别的合并与分裂,因而有了自我调整类别数的能力。合并主要发生在某一类内样本个数太少的情况,或两类聚类中心之间距离太小的情况。为此设有最小类内样本数限制,以及类间中心距离参数。若出现两类聚类中心距离小于的情况,可

基于isodata算法的Iris数据分类.docx
编号:时间:2021年x月x日书山有路勤为径学海无涯苦作舟页码:实验目的通过对Irisdata采用Isodata算法进行聚类掌握Isodata算法的原理以及具体实施步骤。二.实验原理C均值算法比较简单但它的自我调整能力也比较差。这主要表现在类别数不能改变受代表点初始选择的影响也比较大。ISODATA算法的功能与C均值算法相比在下列几方面有改进。1.考虑了类别的合并与分裂因而有了自我调整类别数的能力。合并主要发生在某一类内样本个数太少的情况或两类聚类中心之间

基于isodata算法的Iris数据分类.docx
编号:时间:2021年x月x日书山有路勤为径,学海无涯苦作舟页码:实验目的通过对Irisdata采用Isodata算法进行聚类,掌握Isodata算法的原理以及具体实施步骤。二.实验原理C均值算法比较简单,但它的自我调整能力也比较差。这主要表现在类别数不能改变,受代表点初始选择的影响也比较大。ISODATA算法的功能与C均值算法相比,在下列几方面有改进。1.考虑了类别的合并与分裂,因而有了自我调整类别数的能力。合并主要发生在某一类内样本个数太少的情况,或两类聚类中心之间距离太小的情况。为此

基于isodata算法的Iris数据分类.doc
实验目的通过对Irisdata采用Isodata算法进行聚类,掌握Isodata算法的原理以及具体实施步骤。二.实验原理C均值算法比较简单,但它的自我调整能力也比较差。这主要表现在类别数不能改变,受代表点初始选择的影响也比较大。ISODATA算法的功能与C均值算法相比,在下列几方面有改进。1.考虑了类别的合并与分裂,因而有了自我调整类别数的能力。合并主要发生在某一类内样本个数太少的情况,或两类聚类中心之间距离太小的情况。为此设有最小类内样本数限制,以及类间中心距离参数。若出现两类聚类中心距离小于的情况,可