
基于主题特征的半监督学习情感分类方法.pdf

小寄****淑k


1/7

2/7

3/7

4/7

5/7

6/7
7/7
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于主题特征的半监督学习情感分类方法.pdf
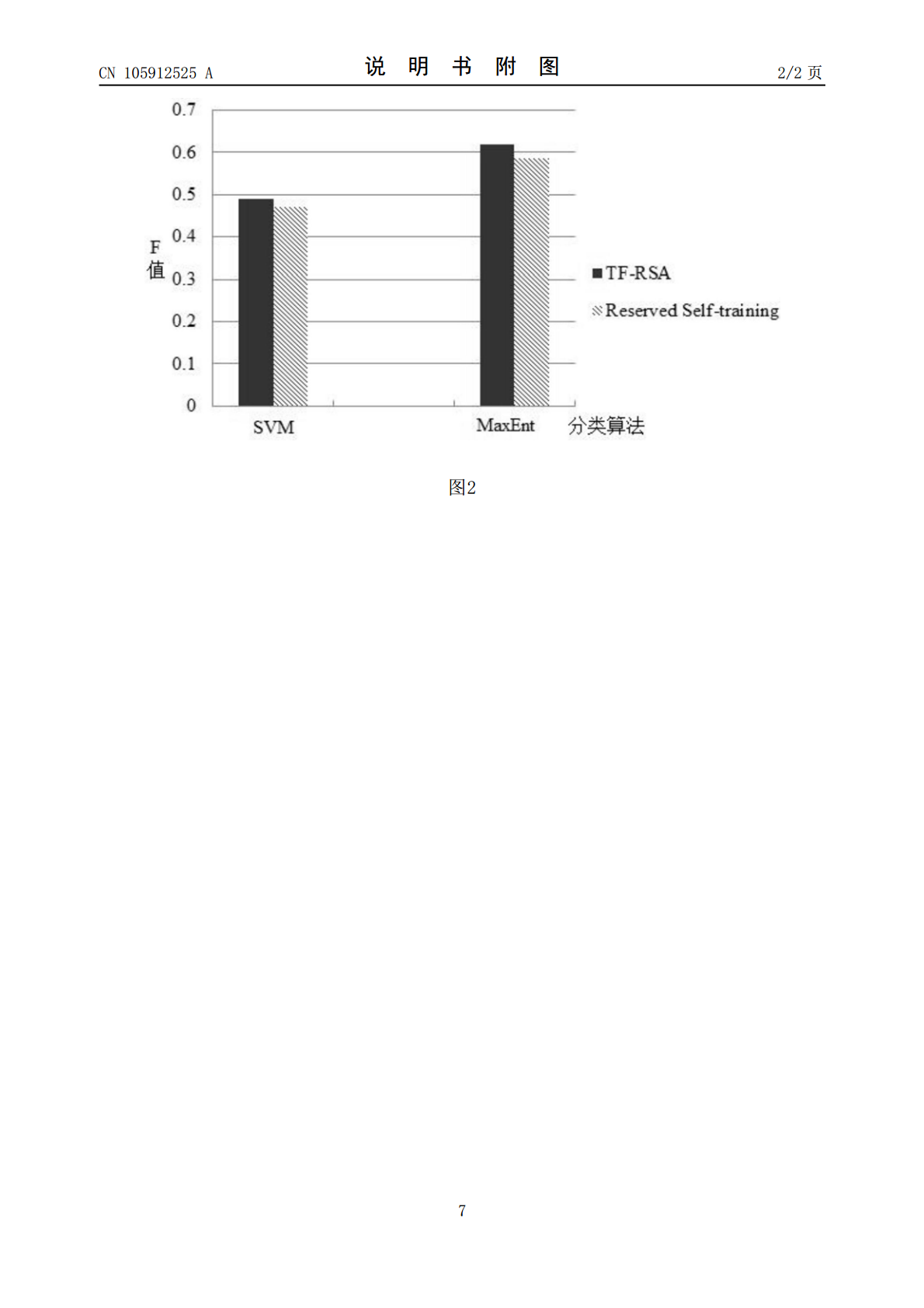
一种基于主题特征的半监督学习情感分类方法,包括:将数据文本进行预处理、文本分词及词性标注;进行特征选择,抽取文本的传统特征,还利用LDA建模技术抽取文本的主题特征;在保留半监督学习框架下,将得到的文本的传统特征和文本的主题特征作为数据集,分别用SVM算法和最大熵算法进行分类训练。本发明可以实现更精确的情感特征分类。为电子商务和社交网络的文本情感分类技术提供了一种新的思路。用户能更有效的寻找适合自己的服务。

基于半监督学习的情感分类方法研究.docx
基于半监督学习的情感分类方法研究摘要:情感分类在自然语言处理领域中是一个重要的任务,它可以帮助我们分析评论、推文等文本数据的情感倾向。传统的情感分类方法通常需要大量标记好的训练数据,但是获取大规模的标记数据是一项耗时且费力的工作。为了解决这个问题,本文提出了一种基于半监督学习的情感分类方法。我们利用少量标记数据和大量未标记数据进行训练,通过半监督学习算法自动挖掘未标记数据中的情感特征,从而提高情感分类的性能。实验证明,我们的方法在情感分类任务上取得了良好的性能,并且相较于传统方法具有更高的效率和灵活性。关

基于半监督的特征学习及分类方法研究的开题报告.docx
基于半监督的特征学习及分类方法研究的开题报告一、研究背景及意义数据分类是机器学习中的经典问题之一,其目标是预测新数据点属于哪个类别。传统的分类方法通常基于有标注的训练数据,利用监督学习技术进行分类,但是由于获取有标注数据的成本较高,在许多实际应用中,只有少量的有标注数据可用。因此,如何利用大量的未标注数据来提高分类准确率是一个非常重要的问题。半监督学习就是解决这一问题的一种重要方法。半监督学习利用有标注和未标注数据来学习数据的特征,并将其映射到一个更高维的特征空间中。因此,半监督学习可以更好地利用未标注数

基于半监督的特征学习及分类方法研究的任务书.docx
基于半监督的特征学习及分类方法研究的任务书一、任务简介特征学习及分类是机器学习领域的重要研究方向之一。在许多应用领域中,如图像识别、自然语言处理等,特征学习及分类方法都发挥了重要作用。然而,传统的特征学习及分类方法仍然存在着一些问题,如需要大量的标注数据来训练模型、难以处理高维数据等。因此,本次任务旨在探究基于半监督的特征学习及分类方法,旨在克服传统方法所存在的问题,提高模型的性能和泛化能力。二、任务背景随着计算机技术的不断发展,机器学习算法开始被广泛应用于各个领域,特别是图像识别、自然语言处理、语音识别

基于双语对抗学习的半监督情感分类.docx
基于双语对抗学习的半监督情感分类标题:基于双语对抗学习的半监督情感分类摘要:情感分类是自然语言处理(NLP)领域的一个重要任务,可应用于社交媒体分析、消费者评论挖掘等众多领域。然而,由于情感标注数据的获取成本高昂,情感分类模型通常面临着数据稀疏性和标注数据不足的问题。半监督学习技术能够利用大量未标注数据来提高模型性能,但在情感分类任务中,这种方法往往受到语言差异和领域差异的限制。另一方面,双语对抗学习(BiGAN)是一种有效的跨语言表示学习方法,可用于克服不同语言之间的差异。本论文提出了一种基于双语对抗学