
一种基于持久内存的日志结构合并树分级存储方法及系统.pdf

宏硕****mo


1/8

2/8

3/8

4/8

5/8

6/8
7/8
8/8
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种基于持久内存的日志结构合并树分级存储方法及系统.pdf
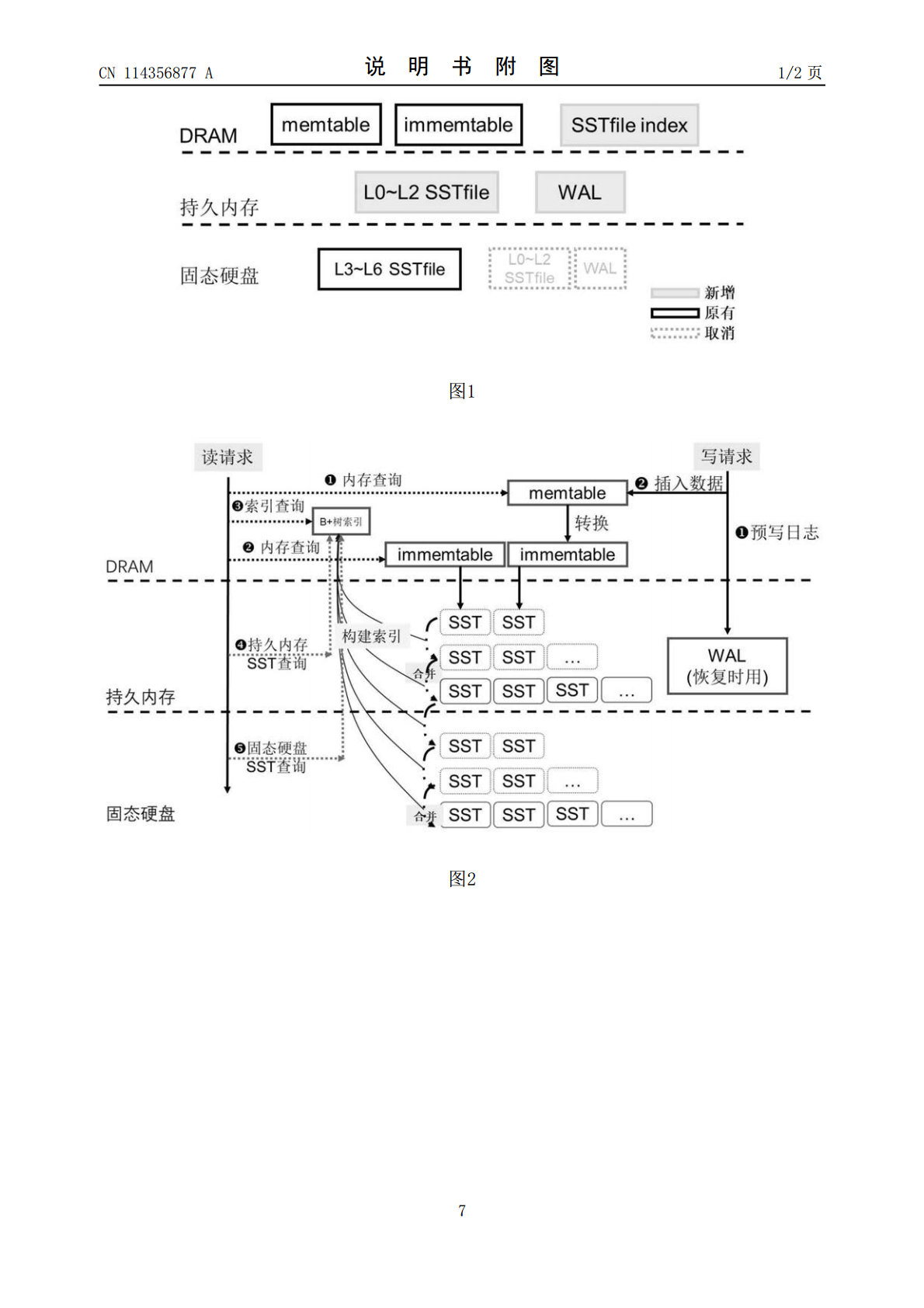
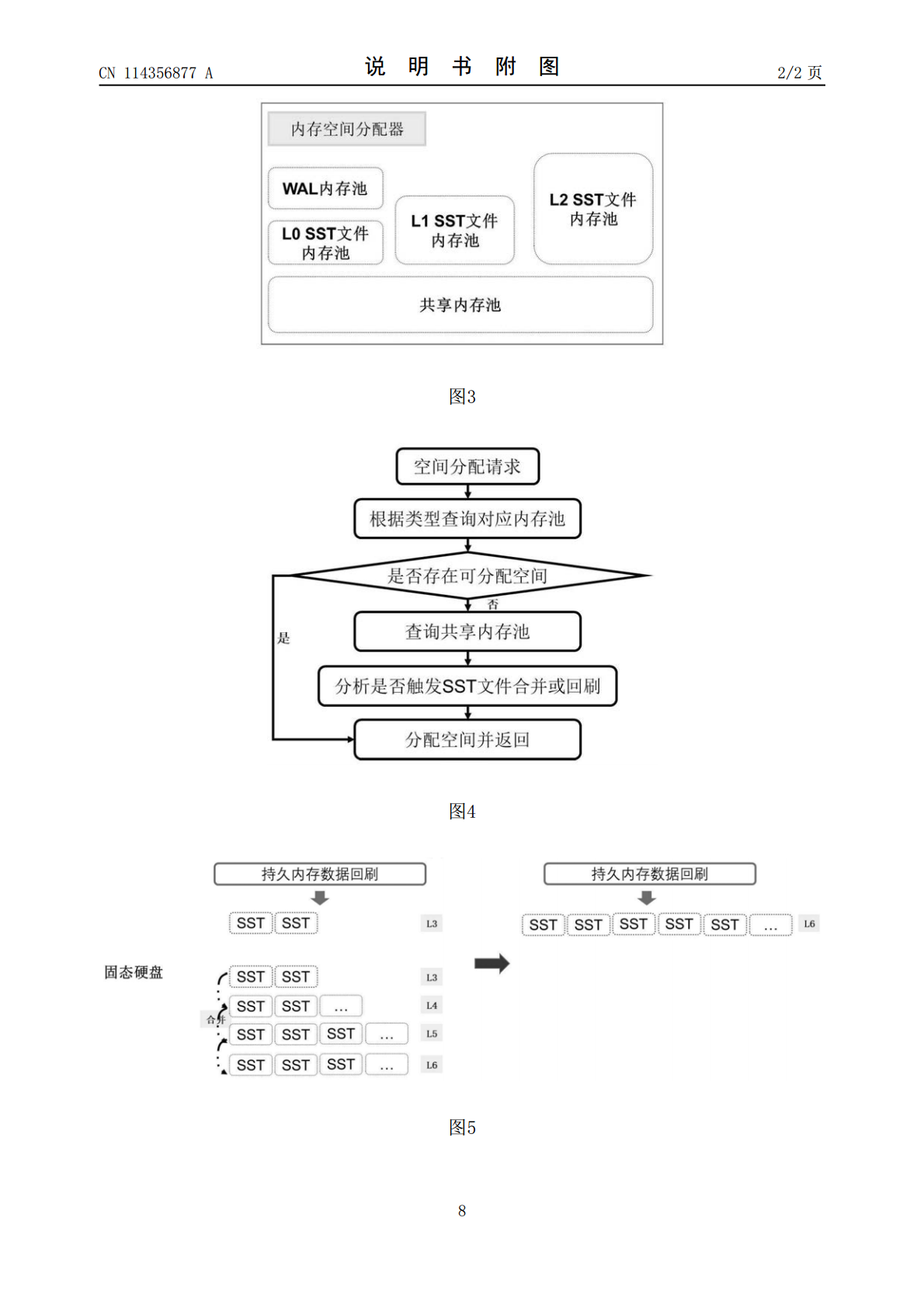
本发明公开了一种基于持久内存的日志结构合并树分级存储方法及系统,属于内存数据存储技术领域。本发明的基于持久内存的日志结构合并树分级存储方法基于持久内存分配器、文件二级索引、动态键值分离,将日志结构合并树分级存储在普通内存、持久内存和固态硬盘,普通内存保留核心关键元数据,预写日志WAL和LSM‑TreeL0‑L2层数据记录在持久内存中,L3‑L6层文件数据存放在固态硬盘中。该发明的基于持久内存的日志结构合并树分级存储方法能够充分发挥持久内存低延迟和硬盘大容量的特性,提高数据合并和数据访问效率,具有很好的推

一种基于日志结构合并树的两阶段合并方法.pdf
本发明涉及一种基于日志结构合并树的两阶段合并方法,包括以下步骤:1)根据不均衡得分在开源系统中选出空间分布最不合理的一层;2)根据轮询原则选出空间分布最不合理一层中的目标文件;3)将目标文件按覆盖相同键值范围的下层文件分割碎片,将每一碎片与对应键值范围的下层文件链接,并为每一下层文件增加SliceLink;4)检查每一下层文件SliceLink数量,若所有下层文件SliceLink数量均不超过预设阈值则进入步骤2),直到存在下层文件SliceLink数量超过预设阈值则进入步骤5);5)将SliceLink

一种基于持久性内存的列式存储方法、装置及设备.pdf
本申请公开了一种基于持久性内存的列式存储方法,该方法将文件转换为哈希结构数据并存储在持久性内存上,由于持久性内存具备字节寻址及非易失性,因此能够在数据读写过程中避免经过文件系统栈,大幅地提升数据查询速度;相比传统列式存储,该存储方式更易于实现修改、删除等实时数据操作,扩大了列式存储的应用场景;此外,该方法了采用一种逻辑简单的且占用空间极小的位图索引数据描述列块上的数据分布情况,避免了记录粉碎和组装算法的复杂性,在保留列式存储优势的同时简化存储逻辑,进一步提升列式存储的数据读写性能。此外,本申请还公开了一种

一种基于安全内存的存储优化方法及系统.pdf
本说明书一个或多个实施例涉及一种基于安全内存的存储优化方法;所述方法包括:获取安全内存的可用容量;获取模型或者模型某一层的待计算数据;获取所述模型或者模型某一层的权重;根据所述权重,以及所述待计算数据,确定内存需求量;所述内存需求量为完成计算预计需要占用的安全内存的存储空间;将所述内存需求量与所述内存的可用容量进行对比;当比较结果满足预设条件时,对所述权重进行修正,获取量化权重,基于所述量化权重进行计算;所述量化权重对内存的需求量小于所述权重对内容的需求量。

一种基于内存映射的异步日志构建方法和系统.pdf
本发明公开了一种基于内存映射的异步日志构建方法和系统,涉及互联网技术领域。该基于内存映射的异步日志构建方法,有效提升了传统日志库的性能,提高了日志库的可靠性,提供了一种简单易用的日志框架,使用异步模式可以解决传统同步日志库的性能问题,异步模式使用双buffer缓冲的设计,提高了传统异步日志的性能;基于mmap内存映射的存储模块,解决了传统日志库需要反复进行系统调用的问题,通过实现内存与文件的相互映射,实现日志文件的高性能读写与日志不丢失,并且设计接口支持自定义输出的设计,用户可通过注册日志输出,使用自定义