
搜索引擎基本原理及实现技术ppt课件.ppt

lj****88


1/10
2/10
3/10

4/10

5/10

6/10

7/10
8/10

9/10

10/10
亲,该文档总共43页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

搜索引擎基本原理及实现技术ppt课件.ppt
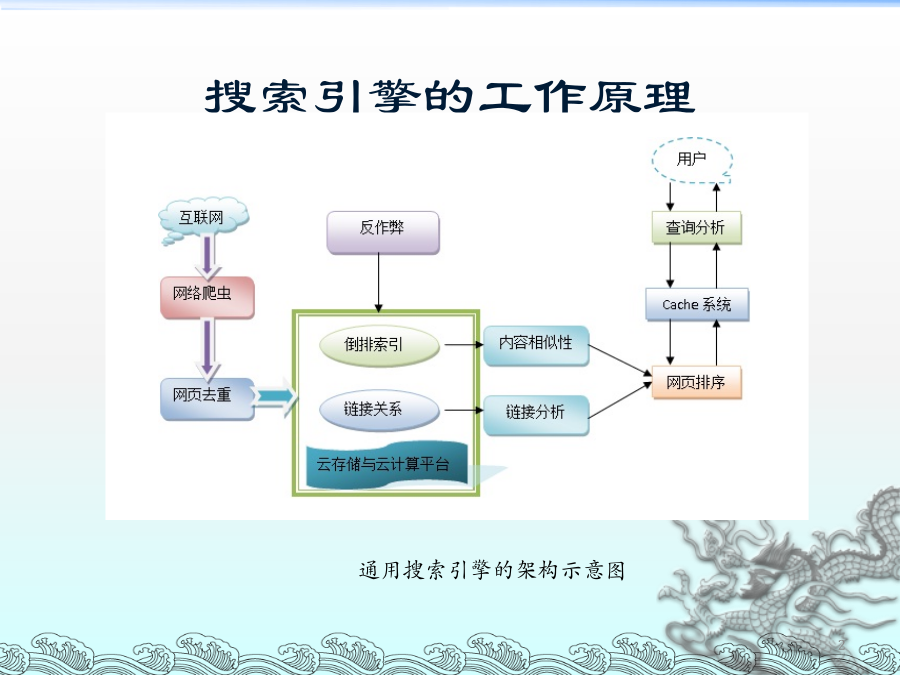
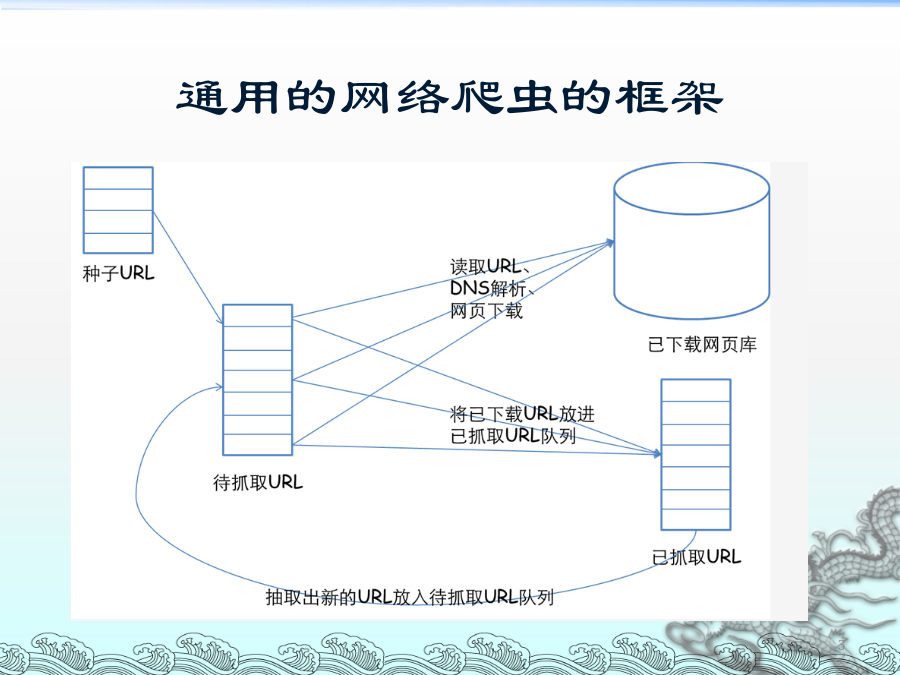
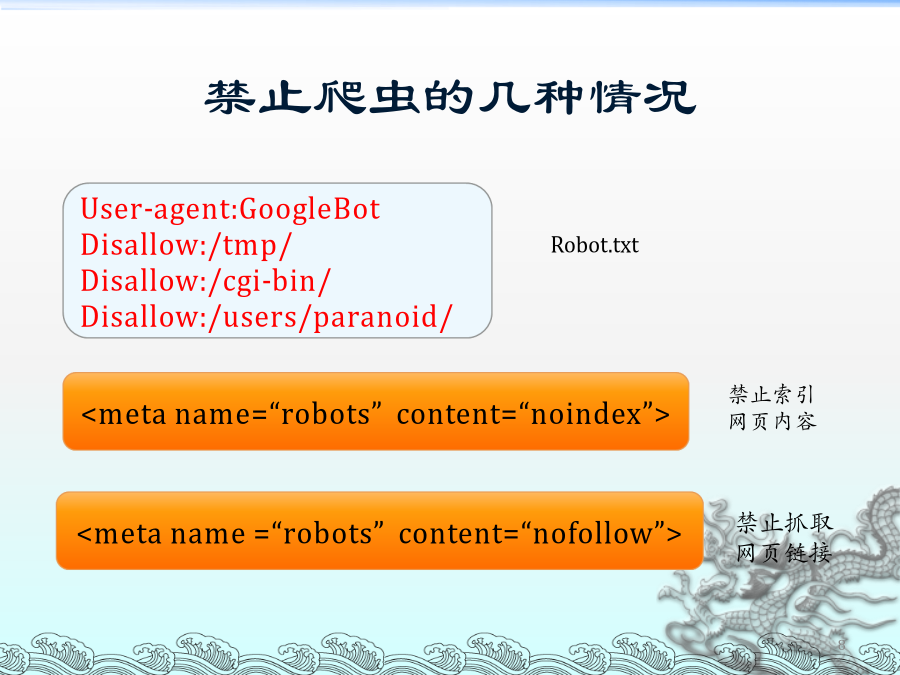
搜索引擎基本原理及实现技术搜索引擎的工作原理通用的网络爬虫的框架爬虫技术总体介绍:(一)网络爬虫是一个自动提取网页的程序,它为搜索引擎从Internet网上下载网页,是搜索引擎的重要组成。网络爬虫使用多线程技术,让爬虫具备更强大的抓取能力。网络爬虫还要完成信息提取任务,对于抓取回来的网页提取出来:新闻、电子图书、行业信息等。对于MP3、图片、Flash等各种不同内容,要实现自动识别、自动分类及相关属性测试(例如:MP3文件要包含的文件大小,下载速度等属性)。(二)抓取对象:1.静态网页:爬虫从一个或若干初

搜索引擎技术介绍PPT课件.ppt
搜索引擎技术介绍2007年8月目录一、搜索引擎总体介绍一、搜索引擎总体介绍一、搜索引擎总体介绍一、搜索引擎总体介绍二、爬虫技术介绍二、爬虫技术介绍二、爬虫技术介绍二、爬虫技术介绍二、爬虫技术介绍二、爬虫技术介绍二、爬虫技术介绍二、爬虫技术介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍三、中文分词和排序算法介绍四、查询

CT基本原理与技术进展ppt课件.ppt
CT基本原理与技术进展内容目标CT发展史CT成像系统CT成像的工作流程CT成像的物理数学基础CT为什么要旋转扫描?第一代CT?原始数据的采集体素voxelCT值的概念人体组织器官的标准CT值(HU)CT值测量8图像重建数/模转换重建图像技术进展螺旋扫描技术(SpiralScan)多排螺旋CTMulti-DetectorrowCT,MDCT多排螺旋CT(MDCT)技术优势CT进展比较CT检查技术增强扫描Enhancedscanning同层动态增强扫描多期相增强扫描小肝癌平扫+双期增强扫描小肝癌肝血管瘤肝血

税收筹划基本原理与技术方法ppt课件.ppt
税收筹划基本原理与技术方法(一)税收筹划的基本原理税收筹划最重要的原理是节税原理。节税原理又可细分为绝对节税原理、相对节税原理、风险节税原理三个主要部分。1.绝对节税原理。绝对节税是指直接使纳税绝对总额减少,即在多个可供选择的纳税方案中,选择缴纳税款额最少的方案。这种节税可以是直接减少纳税人的纳税总额,也可以是直接减少其在一定时期内的纳税总额。一般情况下,企业可采用减少税基、适用较低税率的方式来减少纳税总额。2.相对节税原理。相对节税是指一定时期内的纳税总额并没有减少,但由于考虑货币的时间价值因素,推迟税

免疫检测技术的基本原理ppt课件.ppt
第三节免疫检测技术的基本原理2免疫学检测技术的优点免疫分析技术的应用凝集试验试管法半定量试验2.间接凝集法3.间接凝集抑制试验凝集反应2.沉淀反应单向琼脂扩散试验双向琼脂扩散试验对流免疫电泳3.中和反应如抗“O”试验免疫标记技术酶联免疫吸附试验酶及其底物酶结合物是酶与抗体或抗原,半抗原在交联剂作用下联结的产物。是ELISA成败的关键试剂,它不仅具有抗体抗原特异的免疫反应,还具有酶促反应,显示出生物放大作用,但不同的酶选用不同的底物,将得到不同的颜色反应.酶戊二醛交联法(一步法)戊二醛交联法(二步法)过碘酸