
Hadoop云计算实验报告.docx

玄静****写意


1/10

2/10
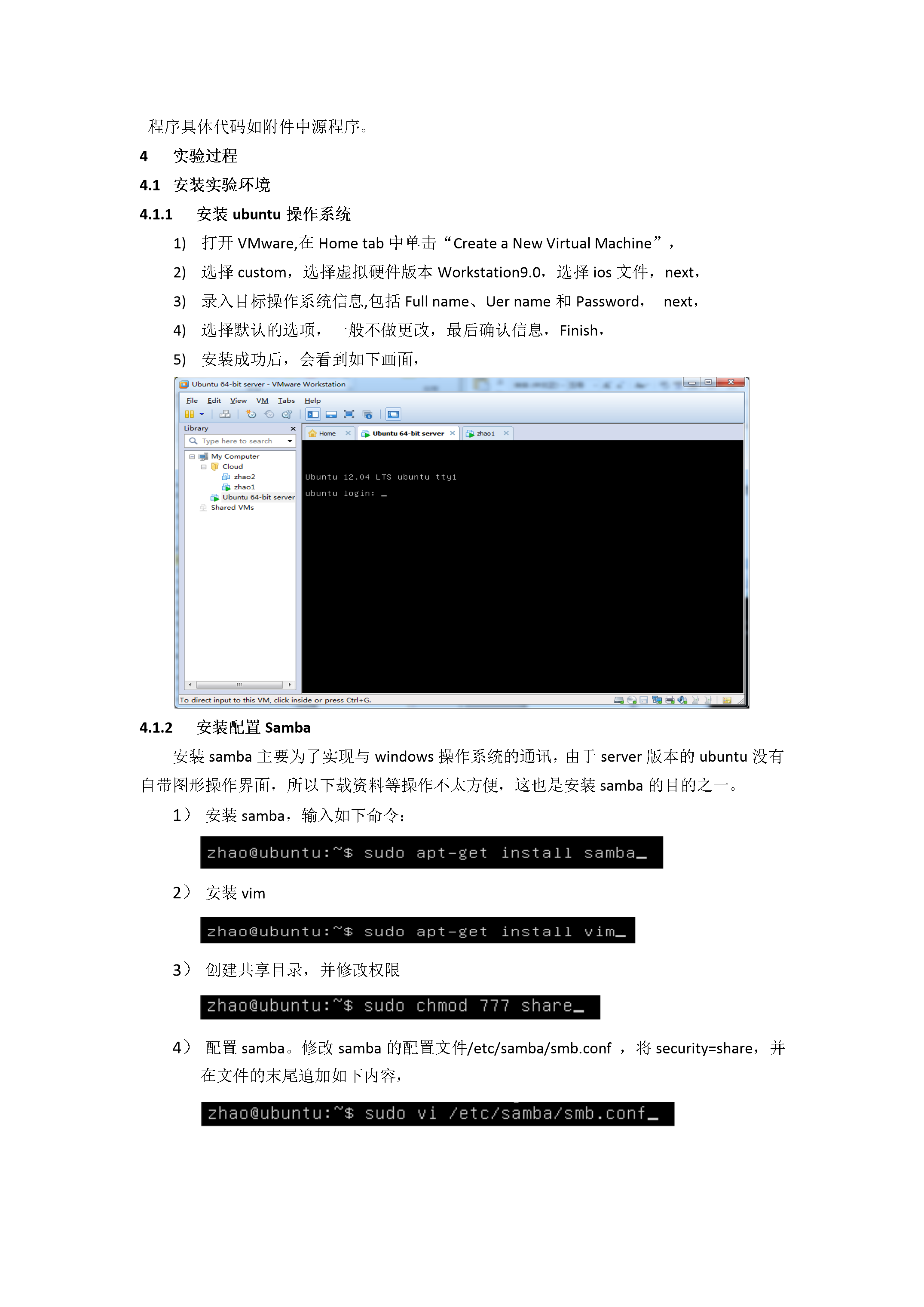
3/10

4/10

5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

Hadoop云计算实验报告.doc
Hadoop云计算实验报告Hadoop云计算实验报告Hadoop云计算实验报告Hadoop云计算实验报告Hadoop云计算实验报告实验目的在虚拟机Ubuntu上安装Hadoop单机模式和集群;编写一个用Hadoop处理数据的程序,在单机和集群上运行程序。实验环境虚拟机:VMware9操作系统:ubuntu—12.04—server—x64(服务器版),ubuntu—14.10—desktop—amd64(桌面版)Hadoop版本:hadoop1。2.1Jdk版本:jdk—7u80—linux-x64Ecl

Hadoop云计算实验报告.docx
Hadoop云计算实验报告Hadoop云计算实验报告实验目的在虚拟机Ubuntu上安装Hadoop单机模式和集群;编写一个用Hadoop处理数据的程序在单机和集群上运行程序。实验环境虚拟机:VMware9操作系统:ubuntu-12.04-server-x64(服务器版)ubuntu-14.10-desktop-amd64(桌面版)Hadoop版本:hadoop1.2.1Jdk版本:jdk-7u80-linux-x64Eclipse版本:eclipse-jee-luna-SR2-linux-gtk-x
Hadoop云计算实验报告.docx
Hadoop云计算实验报告Hadoop云计算实验报告实验目的在虚拟机Ubuntu上安装Hadoop单机模式和集群;编写一个用Hadoop处理数据的程序在单机和集群上运行程序。实验环境虚拟机:VMware9操作系统:ubuntu-12.04-server-x64(服务器版)ubuntu-14.10-desktop-amd64(桌面版)Hadoop版本:hadoop1.2.1Jdk版本:jdk-7u80-linux-x64Eclipse版本:eclipse-jee-luna-SR2-linux-gtk-x
Hadoop云计算实验报告.docx
Hadoop云计算实验报告Hadoop云计算实验报告实验目的在虚拟机Ubuntu上安装Hadoop单机模式和集群;编写一个用Hadoop处理数据的程序在单机和集群上运行程序。实验环境虚拟机:VMware9操作系统:ubuntu-12.04-server-x64(服务器版)ubuntu-14.10-desktop-amd64(桌面版)Hadoop版本:hadoop1.2.1Jdk版本:jdk-7u80-linux-x64Eclipse版本:eclipse-jee-luna-SR2-linux-gtk-x

Hadoop云计算实验报告.doc
Hadoop云计算实验报告Hadoop云计算实验报告Hadoop云计算实验报告Hadoop云计算实验报告Hadoop云计算实验报告实验目的在虚拟机Ubuntu上安装Hadoop单机模式和集群;编写一个用Hadoop处理数据的程序,在单机和集群上运行程序。实验环境虚拟机:VMware9操作系统:ubuntu—12.04—server—x64(服务器版),ubuntu—14.10—desktop—amd64(桌面版)Hadoop版本:hadoop1。2.1Jdk版本:jdk—7u80—linux-x64Ecl