
面向Graph500图遍历的存储结构和访存优化研究.docx

快乐****蜜蜂


1/3

2/3

3/3
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

面向Graph500图遍历的存储结构和访存优化研究.docx
面向Graph500图遍历的存储结构和访存优化研究面向Graph500图遍历的存储结构和访存优化研究摘要随着大规模数据集的快速增长,图遍历问题在图计算中变得越来越重要。Graph500是一个用于评估大规模图处理系统性能的基准,因此对于Graph500图遍历算法的存储结构和访存优化的研究具有重要意义。本文首先介绍了Graph500图遍历问题的背景和挑战,然后分析了当前图遍历算法中存在的存储结构和访存优化方面的问题,并提出了一些解决方案。最后,本文总结了未来在图遍历算法存储结构和访存优化方面的研究方向和挑战。

面向Graph500图遍历的存储结构和访存优化研究的开题报告.docx
面向Graph500图遍历的存储结构和访存优化研究的开题报告一、选题背景Graph500是一种基于图遍历的性能基准测试,是高性能计算领域中评估机器学习、社交网络等图处理性能指标的重要工具。Graph500的测试模型基于BFS(Breadth-First-Search)算法,旨在评估图处理系统的吞吐量和响应时间。Graph500测试主要通过以下三个指标来评估图处理系统的性能:1)问题规模,即图的大小;2)构造时间,即图的生成时间;3)BFS性能,即从任意起始点开始BFS的执行时间。图处理是计算机科学中的一个

面向Graph500图遍历的存储结构和访存优化研究的任务书.docx
面向Graph500图遍历的存储结构和访存优化研究的任务书任务书任务名称:面向Graph500图遍历的存储结构和访存优化研究任务背景:随着图计算技术的发展,越来越多的图算法开始被广泛应用在各个领域,例如社交网络分析、学术研究、智能推荐和安全监控等。其中Graph500作为图计算评估标准之一,已被广泛应用。在图遍历中,存储结构和访存优化是关键的因素,可以大大影响图遍历的性能和效率。任务描述:本次任务旨在针对Graph500图遍历,研究不同的存储结构和访存优化方式,探究如何优化图遍历的性能和效率。具体任务如下

面向深度学习的GPU访存优化研究.docx
面向深度学习的GPU访存优化研究面向深度学习的GPU访存优化研究摘要:近年来深度学习在诸多领域中取得了重大突破。然而,深度学习模型的计算复杂度以及对大量数据的需求导致了巨大的计算负载。为了解决这一问题,GPU作为深度学习的主要计算平台之一,发挥了重要的作用。然而,GPU的访存性能成为制约深度学习性能进一步提升的瓶颈。本文旨在通过研究面向深度学习的GPU访存优化方法,提高深度学习模型的训练和推理性能。1.引言深度学习是一种基于神经网络的机器学习算法,其最大的特点是可以自动从大量数据中进行学习和提取特征。随着
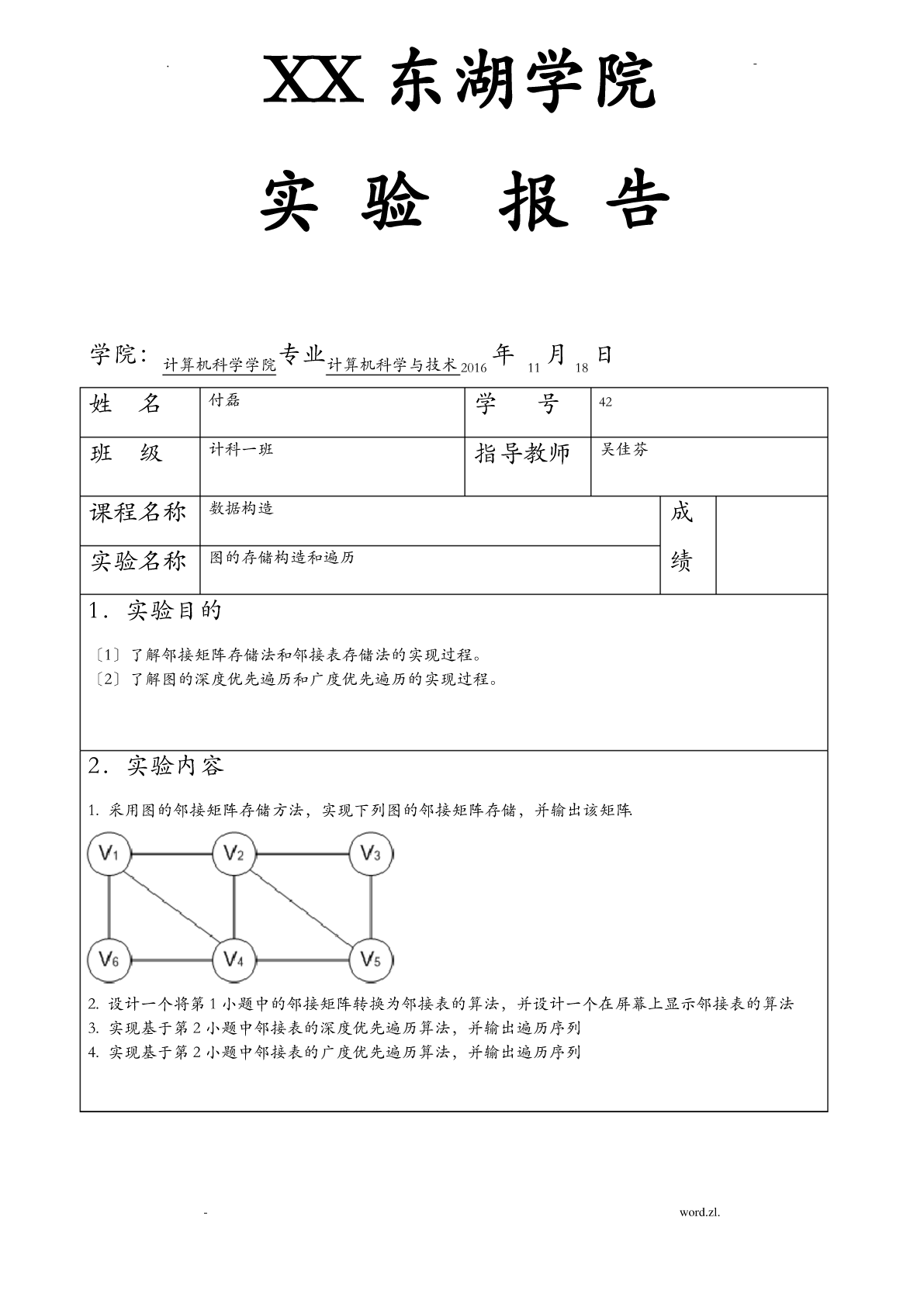
实验报告:图的存储结构和遍历.pdf
.XX东湖学院-实验报告学院:专业年月日计算机科学学院计算机科学与技术20161118姓名付磊学号42班级计科一班指导教师吴佳芬课程名称数据构造成实验名称图的存储构造和遍历绩1.实验目的〔1〕了解邻接矩阵存储法和邻接表存储法的实现过程。〔2〕了解图的深度优先遍历和广度优先遍历的实现过程。2.实验内容1.采用图的邻接矩阵存储方法,实现下列图的邻接矩阵存储,并输出该矩阵.2.设计一个将第1小题中的邻接矩阵转换为邻接表的算法,并设计一个在屏幕上显示邻接表的算法3.实现基于第2小题中邻接表的深度优先遍历算法,并输