
基于数据挖掘的图书管理系统分析与设计.docx

快乐****蜜蜂


1/3

2/3

3/3
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

基于数据挖掘的图书管理系统分析与设计.docx
基于数据挖掘的图书管理系统分析与设计随着数字化时代的到来,图书管理系统已逐渐从传统的手工管理转向计算机化管理。数据挖掘作为一种数据分析方法,可以帮助图书馆更好地了解读者需求、图书销售情况等方面的数据,从而优化图书馆的服务和管理。本文将基于数据挖掘的图书管理系统进行分析与设计。一、需求分析为了开发出适合读者和管理员使用的图书管理系统,需求分析是必不可少的环节。对于读者来说,他们需要快速、方便地搜索到所需的书籍,并了解相关信息,如图书的馆藏情况、借阅历史等。对于管理员来说,他们需要了解读者的借阅习惯和图书的销

基于数据挖掘的图书管理系统分析与设计的任务书.docx
基于数据挖掘的图书管理系统分析与设计的任务书一、任务背景随着数字化和信息化的快速发展,图书馆管理系统在现代化市场经济中起着至关重要的作用,它对于提高图书管理工作的效率、加强读者服务、完善社会信息化体系、改善图文信息资源等方面都具有十分重要的功能。因此,设计开发一套基于数据挖掘的图书管理系统具有现实意义和市场前景。二、任务目标本次设计和开发的基于数据挖掘的图书管理系统,将会实现以下目标:1.提高图书馆工作效率:通过数据挖掘技术,提高图书馆的图书借还效率、减少人为操作错误,提高管理工作效率。2.改善借阅体验:

基于数据挖掘的高校教务管理系统的系统分析与设计.docx
基于数据挖掘的高校教务管理系统的系统分析与设计随着信息技术的快速发展,高校教务管理系统已成为高校行政管理的重要组成部分。本文旨在探讨基于数据挖掘的高校教务管理系统的系统分析与设计,包括系统需求分析、系统设计以及系统性能评估等方面。一、系统需求分析1.用户需求分析高校教务管理系统的用户主要包括学生、教师和行政人员。针对不同的用户,系统的需求有所不同。学生方面,主要需求包括选课、查成绩、查课表、缴费等。同时,学生也需要能够查看个人信息和班级信息等。教师方面,主要需求包括录入成绩、查看学生信息、管理论文等。行政

基于数据挖掘的图书推荐系统的分析与设计.pptx
添加副标题目录PART01PART02数据挖掘的定义和原理数据挖掘在图书推荐系统中的应用数据挖掘的主要算法数据挖掘的优势和局限性PART03图书推荐系统的定义和分类图书推荐系统的关键技术图书推荐系统的应用场景图书推荐系统的发展趋势PART04系统需求分析系统架构设计数据预处理和特征提取模型训练和优化推荐算法的选择和实现PART05系统开发环境与工具系统实现过程系统测试与评估系统性能优化PART06案例一:基于协同过滤的图书推荐系统案例二:基于内容的图书推荐系统案例三:基于混合方法的图书推荐系统实践经验与教
基于XBRL的财务数据挖掘系统分析与设计.pdf
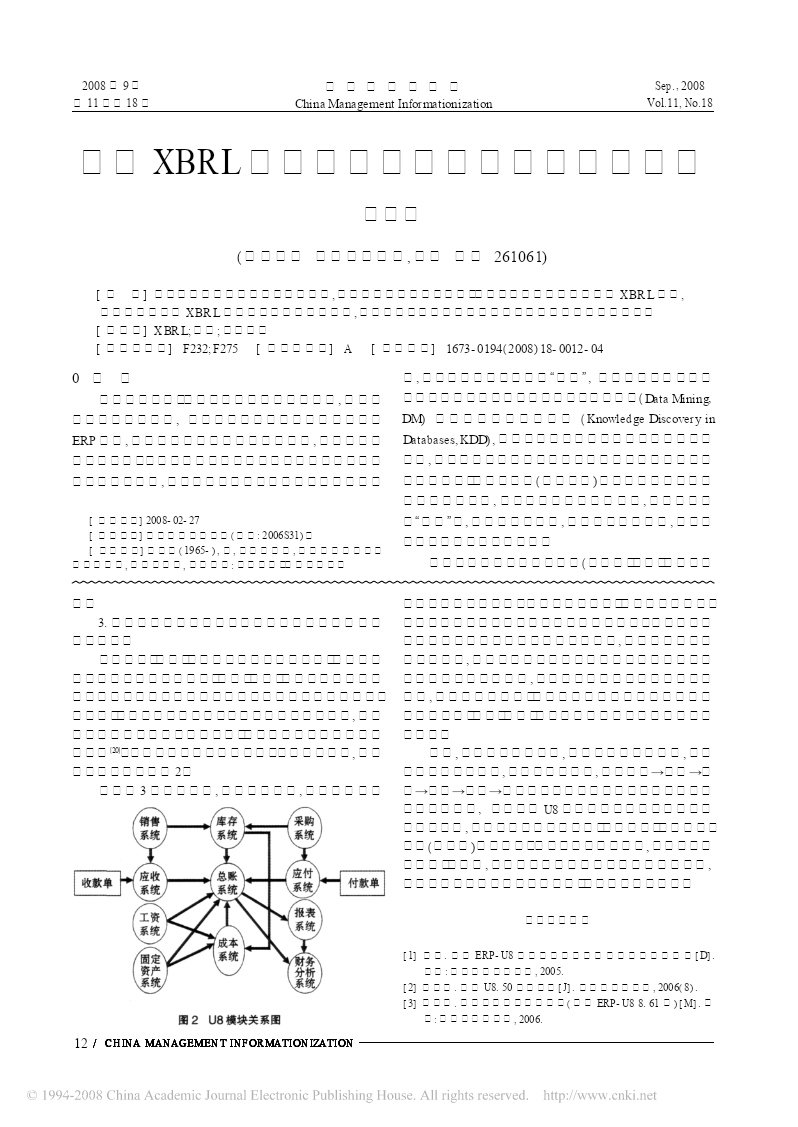
2008年9月中国管理信息化Sep.,2008第11卷第18期ChinaManagementInformationizationVol.11,No.18基于XBRL的财务数据挖掘系统分析与设计刘国英(潍坊学院经济管理学院,山东潍坊261061)[摘要]本文从数据挖掘系统原型架构出发,结合财务数据的特点分析、财务数据挖掘的一般过程和XBRL技术,设计出一种基于XBRL的财务数据挖掘系统模型,为进一步深入研究财务数据挖掘提供了一种较好的方法。[关键词]XBRL;财务;数据挖掘[中图分类号]F232;F275[