
K均值聚类算法-C均值算法ppt课件.ppt

lj****88


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10
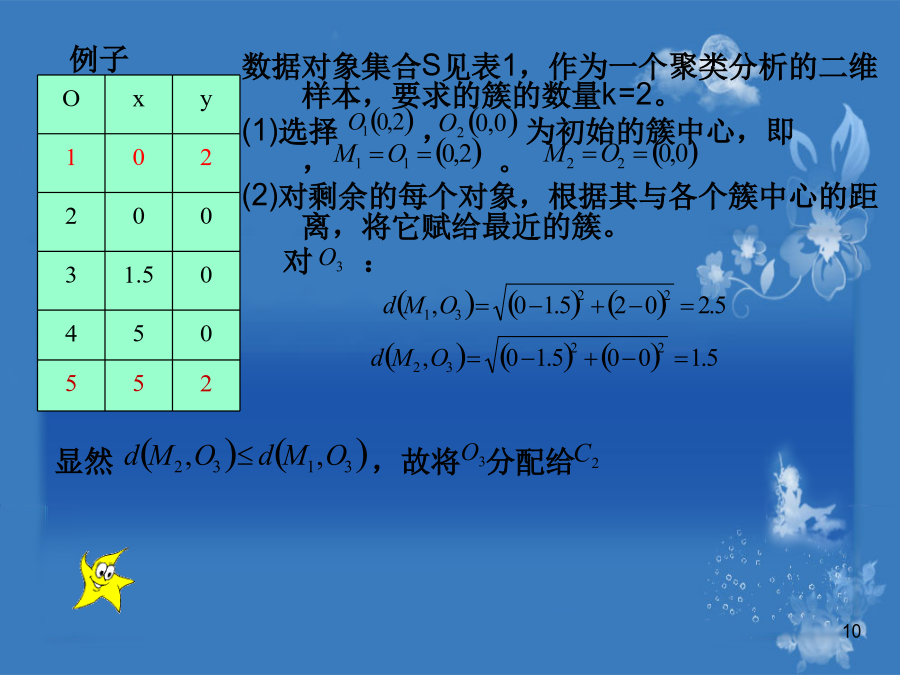
10/10
亲,该文档总共20页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

K均值聚类算法-C均值算法ppt课件.ppt
算法简介算法描述为中心向量c1,c2,…,ck初始化k个种子分组:将样本分配给距离其最近的中心向量由这些样本构造不相交(non-overlapping)的聚类确定中心:用各个聚类的中心向量作为新的中心重复分组和确定中心的步骤,直至算法收敛算法k-means算法输入:簇的数目k和包含n个对象的数据库。输出:k个簇,使平方误差准则最小。算法步骤:1.为每个聚类确定一个初始聚类中心,这样就有K个初始聚类中心。2.将样本集中的样本按照最小距离原则分配到最邻近聚类3.使用每个聚类中的样本均值作为新的聚类中心。4.重

K-MEANS(K均值聚类算法-C均值算法).ppt
2.13.2Thek-MeansAlgorithm(K-均值聚类算法)主讲内容算法简介算法描述为中心向量c1,c2,…,ck初始化k个种子分组:将样本分配给距离其最近的中心向量由这些样本构造不相交(non-overlapping)的聚类确定中心:用各个聚类的中心向量作为新的中心重复分组和确定中心的步骤,直至算法收敛算法k-means算法输入:簇的数目k和包含n个对象的数据库。输出:k个簇,使平方误差准则最小。算法步骤:1.为每个聚类确定一个初始聚类中心,这样就有K个初始聚类中心。2.将样本集中的样本按照最

k-均值聚类算法c语言版.docx
k-均值聚类算法c语言版#include<stdio.h>#include<math.h>#defineTRUE1#defineFALSE0intN;//数据个数intK;//集合个数int*CenterIndex;//初始化质心数组的索引double*Center;//质心集合double*CenterCopy;//质心集合副本double*AllData;//数据集合double**Cluster;//簇的集合int*Top;//集合中元素的个数,也会用作栈处理//随机生成k个数x(0<=x<=n-1

基于遗传算法的K调和均值聚类算法.docx
基于遗传算法的K调和均值聚类算法基于遗传算法的K调和均值聚类算法摘要:聚类是一种常用的数据分析方法,在许多领域中都有着广泛应用。本文基于遗传算法提出了一种K调和均值聚类算法,该算法综合了K均值聚类算法和调和均值聚类算法的优点,有效地解决了聚类中的初始聚类中心选择问题和聚类结果的稳定性问题。实验结果表明,该算法在数据集聚类效果上具有较好的性能。关键词:聚类,遗传算法,K调和均值聚类算法1.引言聚类是一种无监督的数据分析方法,其目标是将相似的数据对象划分到同一类别中,使得不同类别之间的差异最大化,同一类别内的

基于改进粒子群算法的k均值聚类算法.docx
基于改进粒子群算法的k均值聚类算法随着互联网技术的迅猛发展,数据规模呈现爆炸式增长,如何有效地对数据进行处理,成为了数据分析领域的重要研究方向。其中,聚类算法是数据分析中最常用的方法之一,其主要目的是将相似的数据点分到同一个簇中,从而实现对数据进行分类。k均值聚类算法是最常用的聚类算法之一,其基本思想是根据数据点之间的距离进行聚类。该算法首先随机选取k个初始聚类中心,然后计算每个数据点与这些聚类中心的距离,将每个数据点分配到距其最近的聚类中心所在的簇中,然后重新计算每个簇的聚类中心,重复上述过程直到收敛为