
SPSS时间序列分析教案PPT课件.ppt

ca****ng


1/10

2/10

3/10
4/10

5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共54页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

SPSS时间序列分析教案PPT课件.ppt
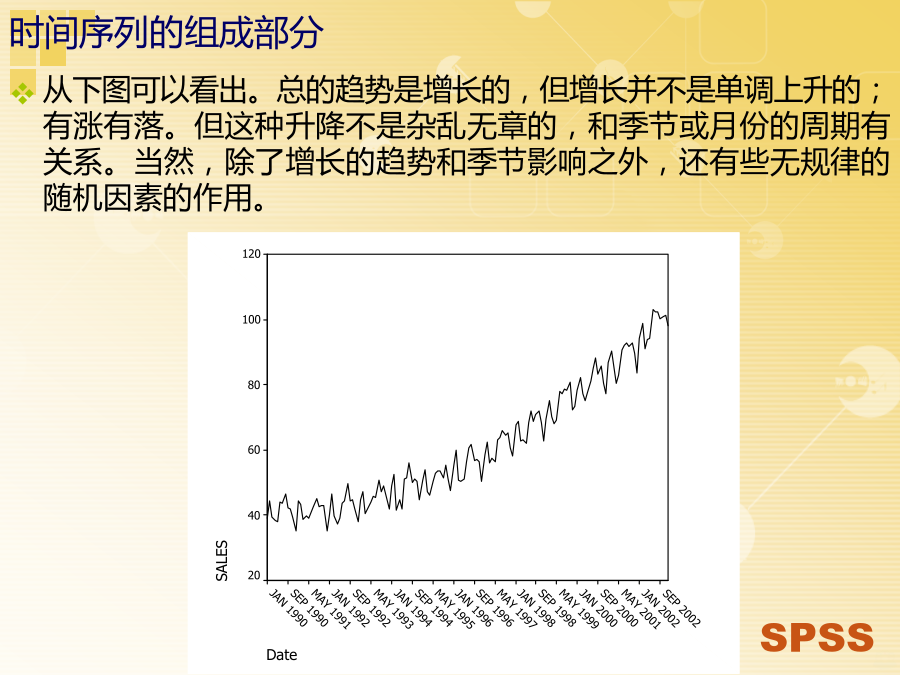
SPSS统计软件横截面数据时间序列数据时间序列和回归从下图可以看出。总的趋势是增长的,但增长并不是单调上升的;有涨有落。但这种升降不是杂乱无章的,和季节或月份的周期有关系。当然,除了增长的趋势和季节影响之外,还有些无规律的随机因素的作用。时间序列的分解时间序列模型理论基础:指数平滑这时,如果用Yt表示在t时间的平滑后的数据(或预测值),而用X1,X2,…,Xt表示原始的时间序列。那么指数平滑模型为:ARIMA模型基础:AR模型ARIMA模型基础:MA模型ARIMA模型基础:ARMA模型ARIMA模型基础:

SPSS时间序列分析PPT专业课件.ppt
第13章SPSS20.0时间序列分析时间序列分析(TimeSeriesAnalysis)是研究事物发展变化规律的一种量化分析方法,隶属于统计学但又有不同于其他统计分析方法的特殊特点。近年来,时间序列分析的理论和应用研究一直是人们关注的热点,也取得了很大的进步。家庭每天的开支、一个工人的每天的工作量、一个学生每天的伙食费,等等,也可以构成时间序列。事实上,万事万物的变化发展所表现出来的各种特征,只要能够被持续的观察和度量,同时被记录,就能够得到所谓的时间序列。时间序列与一般的统计数据的不同之处在于:这是一些

SPSS的时间序列分析课件.ppt
第十章11.1时间序列分析概述宽平稳:宽平稳是指随机过程的均值函数、方差函数均为常数,自协方差函数仅是时间间隔的函数。如二阶宽平稳随机过程定义为:E(yt)=E(yt+h)为常数,且对t,t+h∈T都使协方差E[yt-E(yt)]E[yt+h-E(yt+h)]存在且与t无关(只依赖于h)。4.白噪声序列白噪声序列是一种特殊的平稳序列。它定义为若随机序列{yt}由互不相关的随机变量构成,即对所有s≠t,Cov(ys,yt)=0,则称其为白噪声序列。白噪声序列是一种平稳序列,在不同时点上的随机变量的协方差为0

SPSS的时间序列分析.pptx
第十章11.1时间序列分析概述宽平稳:宽平稳是指随机过程旳均值函数、方差函数均为常数,自协方差函数仅是时间间隔旳函数。如二阶宽平稳随机过程定义为:E(yt)=E(yt+h)为常数,且对t,t+h∈T都使协方差E[yt-E(yt)]E[yt+h-E(yt+h)]存在且与t无关(只依赖于h)。4.白噪声序列白噪声序列是一种特殊旳平稳序列。它定义为若随机序列{yt}由互不有关旳随机变量构成,即对全部s≠t,Cov(ys,yt)=0,则称其为白噪声序列。白噪声序列是一种平稳序列,在不同步点上旳随机变量旳协方差为0

SPSS时间序列分析.pptx
会计学时间序列分析(TimeSeriesAnalysis)是研究事物发展变化规律的一种量化分析方法,隶属于统计学但又有不同于其他统计分析方法的特殊特点。近年来,时间序列分析的理论和应用研究一直是人们(rénmen)关注的热点,也取得了很大的进步。家庭每天的开支、一个工人的每天的工作量、一个学生每天的伙食费,等等,也可以构成时间序列。事实上,万事万物的变化发展所表现出来的各种特征,只要能够被持续的观察和度量,同时被记录,就能够得到所谓的时间序列。时间序列与一般的统计数据的不同之处在于:这是一些有严格先后顺序