
基于Simhash改进的文本去重算法.pptx

快乐****蜜蜂


1/10

2/10

3/10

4/10

5/10
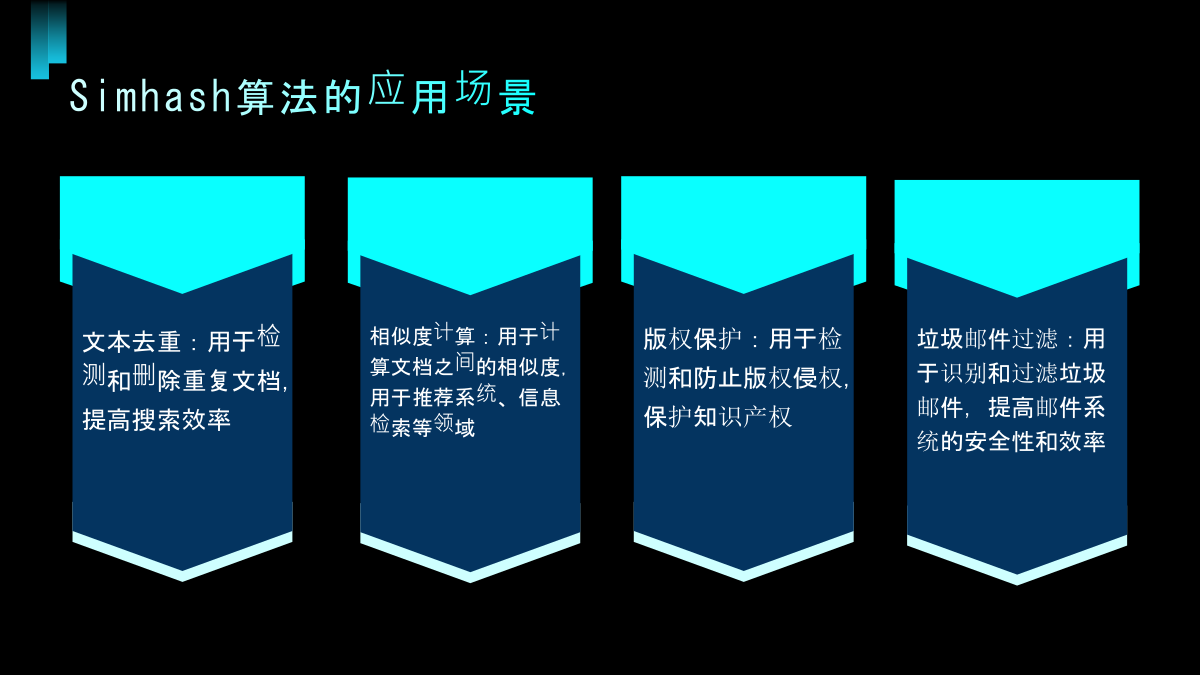
6/10

7/10

8/10

9/10

10/10
亲,该文档总共26页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于Simhash改进的文本去重算法.pptx
汇报人:目录PARTONEPARTTWOSimhash算法的基本原理Simhash算法的应用场景Simhash算法的优缺点PARTTHREE文本预处理特征提取Simhash值计算判断是否重复PARTFOUR引入权重因子引入特征选择机制动态调整阈值优化存储结构PARTFIVE实验数据集实验环境与参数设置实验结果结果分析PARTSIX结论展望THANKYOU

基于Simhash的大规模文档去重改进算法研究.docx
基于Simhash的大规模文档去重改进算法研究基于Simhash的大规模文档去重改进算法研究摘要:随着互联网的飞速发展,海量文档的生成与传播变得日益普遍。文档去重是文本处理和信息检索中的一个重要任务,其主要目标是识别重复或相似的文档并消除冗余。Simhash算法作为一种常见且高效的文档去重算法,已在实际应用中取得广泛应用。然而,在处理大规模文档集合时,传统的Simhash算法在精确度和效率方面存在一些限制。本文针对这些限制,提出了几种改进的Simhash算法,并通过实验证明了其优越性。1.引言随着互联网的

基于Simhash的中文文本去重技术研究.docx
基于Simhash的中文文本去重技术研究随着互联网技术的发展,越来越多的文本数据产生,其中缺乏效率的去重技术已经成为一个重要的瓶颈。文本去重技术是指在大规模数据的情况下,根据文本内容将相似且重复的文本自动判别并移除。为了解决这个问题,一个基于Simhash的中文文本去重技术已经被提出。本文将介绍Simhash技术的原理、应用和优点。一、Simhash技术的原理Simhash是一种哈希算法,根据余弦定理,确定文本相似度的技术。它将每个文本表示为一个K位二进制数字的向量,然后通过计算向量之间的汉明距离来确定文

基于Simhash算法相似聚类的海量文本去重技术研究的开题报告.docx
基于Simhash算法相似聚类的海量文本去重技术研究的开题报告一、选题的背景和意义随着互联网技术的不断发展,互联网上产生了海量的文本数据。其中,很多文本内容可能存在重复,这不仅浪费存储空间,还会影响文本分析的精度与效率。因此,在海量文本处理的过程中,文本去重显得尤为重要。传统的文本去重算法如基于Hash的方法、语义分析法等,虽然有一定的效果,但容易受到文本长度、格式、噪声等因素的影响。而Simhash算法作为一种新型的文本去重算法,具有高效、精准、鲁棒性强等优点,被广泛应用于文本去重领域。本文基于Simh

基于SimHash的文本相似检测算法研究.docx
基于SimHash的文本相似检测算法研究基于SimHash的文本相似检测算法研究摘要:随着互联网的快速发展,文本数据的规模不断扩大,如何有效地进行文本相似性检测成为一个重要的研究课题。本文针对该问题,基于SimHash算法进行了深入的研究和分析。首先介绍了文本相似性检测的背景和意义,接着详细介绍了SimHash算法的原理和应用。通过实验验证,本文证明了SimHash算法在文本相似性检测方面的优越性能,并对其局限性进行了探讨。最后,展望了SimHash算法在未来的发展方向。关键词:文本相似性检测、SimHa