
基于并行运算的非下采样轮廓波变换优化方法.pdf

努力****亚捷


1/10

2/10

3/10

4/10

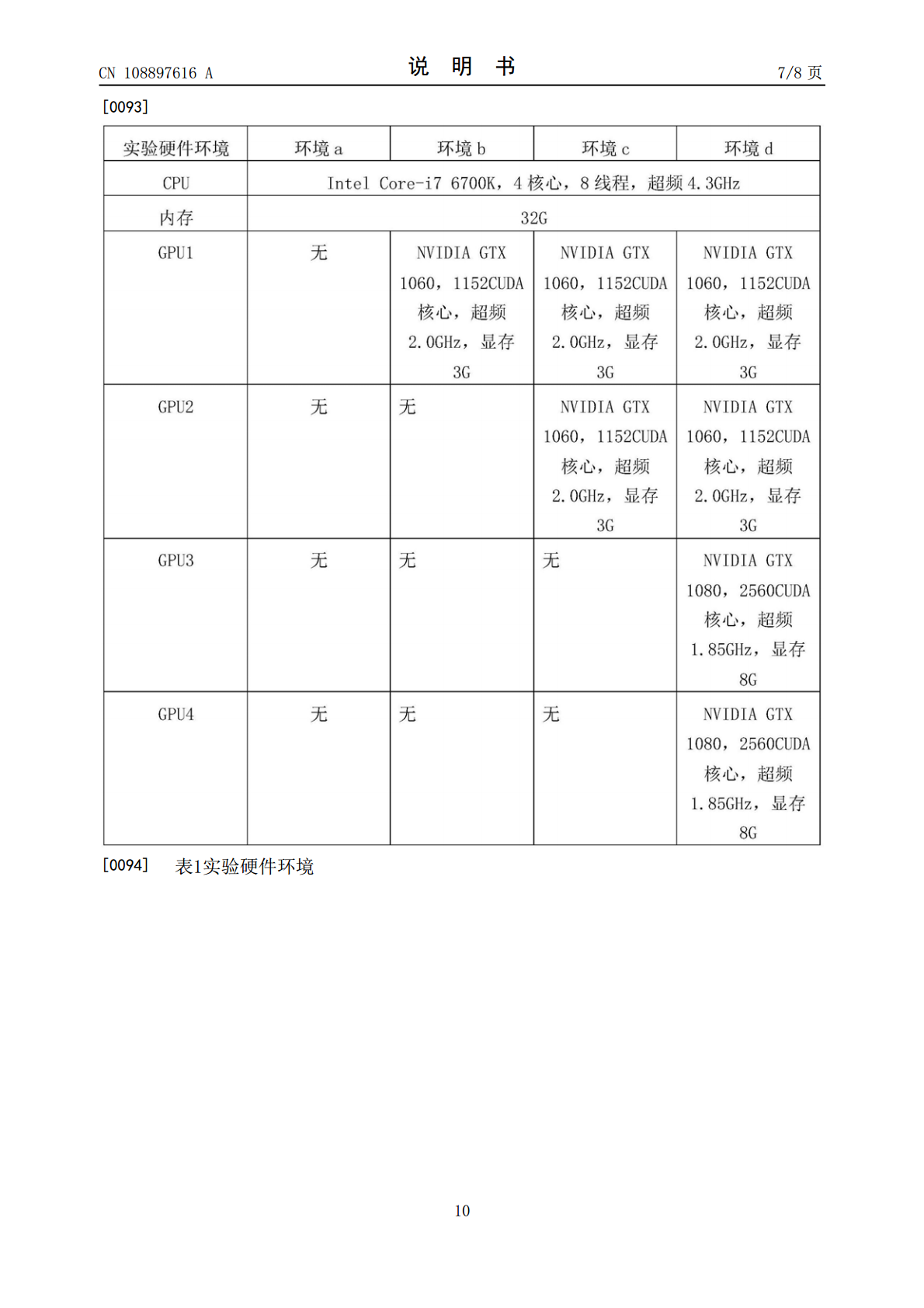
5/10

6/10

7/10

8/10

9/10
10/10
亲,该文档总共20页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

基于并行运算的非下采样轮廓波变换优化方法.pdf
本发明公开了一种基于并行运算的非下采样轮廓波变换优化方法,包括以下步骤(1)根据GPU和CPU配置情况,计算执行NSCT算法中多尺度分解与不同级别方向分解所需要启用的GPU数目和开启的CPU线程数,以及分配给每个GPU的实际计算量;(2)对NSCT分解与重构过程进行并行性分析,发现可以将图像数据移动至GPU,计算卷积,计算结果回存等过程进行并行处理;(3)使用OpenMP和CUDA并行执行NSCT分解和重构过程。本发明方法可以通过并行执行数据移动、像素级并行计算卷积等过程,显著提高NSCT运算速度,降低运

基于非下采样轮廓波变换的遥感图像道路提取方法.pdf
本发明公开了一种从遥感图像中提取道路的方法,属于图像处理技术领域,主要解决现有技术对道路检测定位不够准确、虚假目标多且连续性较差的问题。具体实现过程是:首先,对输入图像进行包括自适应直方图均衡化和Frost去噪的预处理;然后对其进行3层非下采样轮廓波变换,每层分解为8个方向,提取第1层和第2层各方向子带的模极大值作为道路的线性特征向量;再采用模糊C均值聚类算法对得到的特征向量进行聚类,获得道路的初始提取结果;最后,对初始提取进行非极大值抑制以及基于空间关系的道路后处理,得到最终的道路提取结果。

基于非下采样轮廓波变换的遥感图像道路增强方法.pdf
本发明公开了一种遥感图像道路增强的方法,主要解决现有技术增强后的道路失真大,道路目标检测不准确的问题。其实现过程是:首先对遥感图像进行3层非下采样的轮廓波变换,其中每层变换的方向个数由低到高排列分别分为4,4,8,再根据各层变换的方向个数,设定相应的结构元素;然后对变换后的系数采用与之相近方向的结构元素进行方向性增强;最后计算图像中每个像素点的方向,得到图像的方向矩阵,通过方向矩阵对增强系数中的噪声和背景进行处理,再对处理后的增强系数进行轮廓波反变换,得到图像的增强结果。本发明能在增强道路的同时,很好的保

非下采样轮廓波变换域的图像降噪方法.pdf
一种非下采样轮廓波变换域的图像降噪方法,属于图像降噪技术领域。其特征是,所述方法首先对输入的带噪图像经计算机进行周期延拓后,采用非下采样轮廓波变换对输入的图像进行多尺度、多方向的稀疏分解,并在非下采样轮廓波变换域运用尺度内模型,利用最大后验概率估计非下采样轮廓波域系数,然后通过非下采样轮廓波逆变换得到预降噪图像,最后再采用卡尔曼滤波方法对预降噪图像进行进一步的降噪处理,得到最终的降噪图像。本发明提供的图像降噪方法能提高降噪图像的质量,达到较理想的降噪效果。在军事领域和非军事领域如目标识别、安全监控、图像采

基于非下采样轮廓波变换的图像去噪方法及装置.pdf
本发明提供了一种基于非下采样轮廓波变换的图像去噪方法及装置,所述方法包括:利用非下采样轮廓波变换将待去噪的图像进行多尺度分解,获得每个尺度的低频分量的第一系数以及每个尺度的高频分量在各个方向上的第二系数;根据每个尺度的第二系数中与该尺度的上一尺度的第一系数的相关性,对各第二系数进行阈值收缩处理或保留,获得各尺度的去噪系数;根据所述去噪系数进行非下采样轮廓波逆变换,获得去噪后的图像。