
语音端点检测的方法.ppt

天马****23


1/10

2/10

3/10

4/10

5/10

6/10
7/10

8/10

9/10

10/10
亲,该文档总共35页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

语音端点检测的方法.ppt
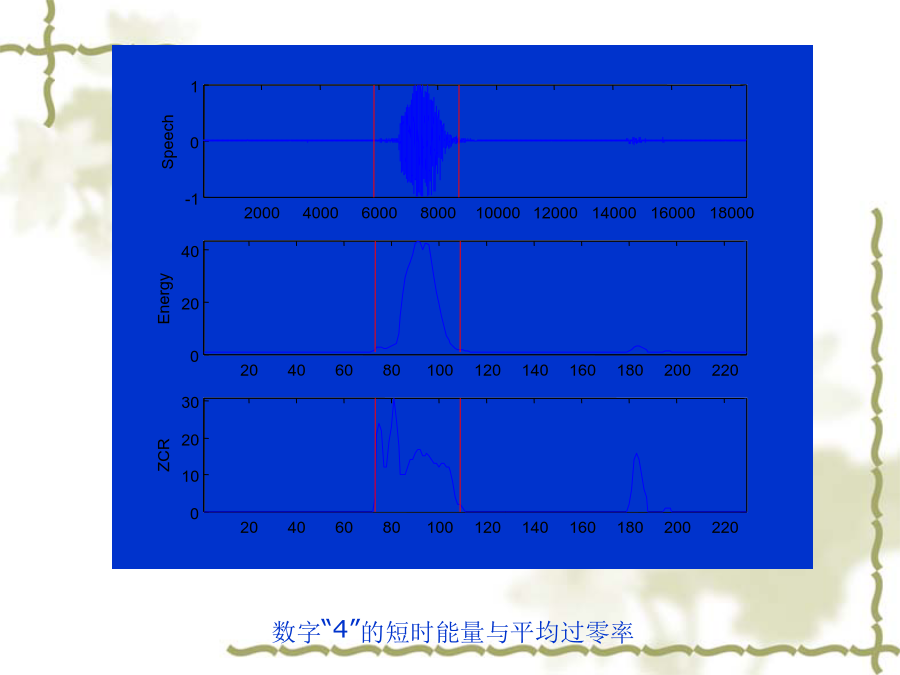
语音端点检测的目的和意义基于短时能量和短时平均过零率的端点检测基于倒谱特征的端点检测基于熵的端点检测基于复杂性的端点检测(KC复杂性和C0复杂性)不同语音端点检测方法的实验结果对比语音端点检测的目的和意义基于短时能量和短时平均过零率的端点检测短时平均过零率短时过零表示一帧语音信号波形穿过横轴(零电平)的次数。过零分析是语音时域分析中最简单的一种。对于连续语音信号,过零意味着时域波形通过时间轴;而对于离散信号,如果相邻的取样值的改变符号称为过零。过零率就是样本改变符号次数。信号{x(n)}的短时平均过零率定

语音端点检测方法及装置.pdf
本发明实施例提供一种语音端点检测方法及装置。接收待检测的语音信号帧并获取所述语音信号帧的特征矢量;根据所述特征矢量,获取所述语音信号帧在预先训练的音素声学模型中的最优到达路径;当根据所述最优到达路径检测到非静音信号帧并判定所述非静音信号帧之前存在预设数量的静音信号帧,则判定所述非静音信号帧为所述语音端点。实现了低复杂度、高效率的语音端点检测。

语音端点检测方法探析.docx
语音端点检测方法探析语音端点检测(VoiceActivityDetection,VAD)是语音信号处理中重要的一个环节,用于确定语音信号的起止位置。准确的语音端点检测对于语音识别、语音合成、电话语音传输等应用至关重要。本文将从几个方面对语音端点检测的方法进行探析。一、传统的基于能量的方法最早的语音端点检测方法是基于能量的方法,即通过检测语音信号的能量值来判断是否为语音。这种方法的基本思想是当语音信号活动时,信号的能量值较高,而在非语音段的能量值较低。根据这个思想,可以通过设置一个能量阈值来进行端点检测。然

语音端点检测方法研究.docx
语音端点检测方法研究摘要:文章在研究语音识别系统中端点检测基本算法的基础上分别对利用双门限的端点检测方法、利用小波变换的端点检测方法、利用倒谱相关理论的端点检测方法原理进行了阐述和说明并对几种端点检测方法的特点进行了分析。关键词:端点检测;双门限;小波变换;倒谱1概述就一般情况下来讲在语音通信过程当中大多采用有线电话网的方式来进行但是由于某些地区环境及场合需要等因素则需要通过无线电台来作为通信方式。与此同时在其实际应用过程中整个通话过程由语音

语音端点检测的方法设计与实现.docx
语音端点检测的方法设计与实现语音端点检测的方法设计与实现摘要:语音端点检测是语音信号处理中重要的一步,它用于确定语音信号的起始和终止位置。本文介绍了语音端点检测的意义和应用场景,并提出了一种基于能量和短时过零率的端点检测算法。该算法通过计算语音信号的能量和短时过零率的变化趋势,确定语音的起始和终止位置。实验证明,该算法在不同噪声环境下都能较准确地检测语音端点,并具有较好的实时性。关键词:语音端点检测、能量、短时过零率、噪声环境、实时性1.引言语音端点检测是语音信号处理中的一项重要任务,它在语音识别、语音增