
(2)判别模型、生成模型与朴素贝叶斯方法.pdf

as****16


1/10

2/10

3/10
4/10

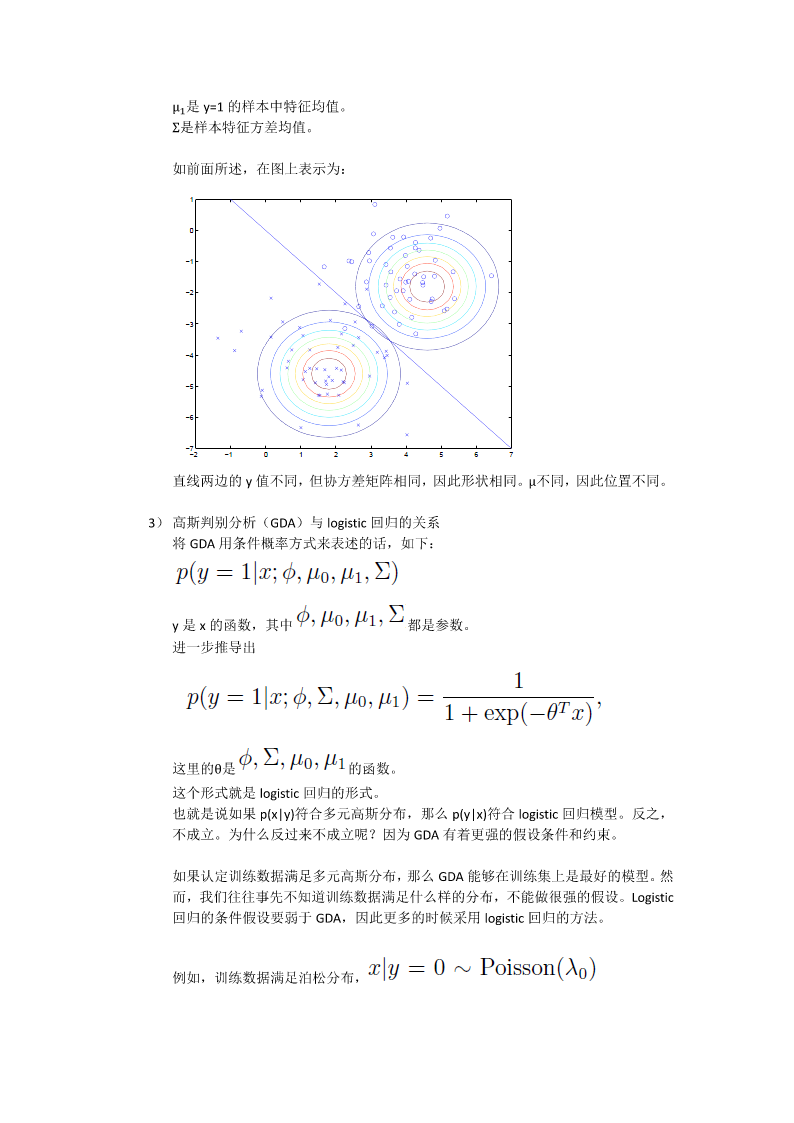
5/10

6/10

7/10

8/10

9/10

10/10
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

(2)判别模型、生成模型与朴素贝叶斯方法.pdf
判别模型、生成模型与朴素贝叶斯方法JerryLeadcsxulijie@gmail.com2011年3月5日星期六1判别模型与生成模型上篇报告中提到的回归模型是判别模型,也就是根据特征值来求结果的概率。形式化表示为푝(푦|푥;휃),在参数휃确定的情况下,求解条件概率푝(푦|푥)。通俗的解释为在给定特征后预测结果出现的概率。比如说要确定一只羊是山羊还是绵羊,用判别模型的方法是先从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。换一种思路,我们可以根据山羊的特征首先学习

贝叶斯网络模型代码.doc
贝叶斯网络模型代码贝叶斯网络模型代码贝叶斯网络模型代码addpath(genpathKPM(pwd))N=4;dag=zeros(N,N);C=1;S=2;R=3;W=4;dag(C,[RS])=1;dag(R,W)=1;dag(S,W)=1;discrete_nodes=1:N;node_sizes=2*ones(1,N);bnet=mk_bnet(dag,node_sizes,'discrete',discrete_nodes);onodes=[];bnet=mk_bnet(dag,node_size

贝叶斯网络模型代码.doc
贝叶斯网络模型代码贝叶斯网络模型代码贝叶斯网络模型代码addpath(genpathKPM(pwd))N=4;dag=zeros(N,N);C=1;S=2;R=3;W=4;dag(C,[RS])=1;dag(R,W)=1;dag(S,W)=1;discrete_nodes=1:N;node_sizes=2*ones(1,N);bnet=mk_bnet(dag,node_sizes,'discrete',discrete_nodes);onodes=[];bnet=mk_bnet(dag,node_size

基于朴素贝叶斯模型的虚假新闻过滤算法研究.pdf
基于朴素贝叶斯模型的虚假新闻过滤算法研究【摘要】社交媒体是一个高度开放和自由的互联网信息传播平台。随着信息媒体数量的增加随着自媒体的出现每个人都可以在微信微博等平台上发布和接收信息。由于信息量巨大准入和访问机制低给信息交流带来了极大的便利同时也出现了大量的谣言。虚假新闻的负面效应极大地影响了国家和社会的和谐稳定和个人日常生活。因此如何自动有效地识别谣言成为相关领域的研究热点。针对日常中的假新闻问题提出一种自动识别虚假新闻的办法该方法利用计算词向量相关度结合朴素贝叶

一种融合词向量模型和朴素贝叶斯的查询词改写方法.pdf
本发明提出一种融合词向量模型和朴素贝叶斯查询改写方法,涉及信息处理技术,该方法利用word2vec训练出向量模型并计算出与查询词最相似的前N个词构成初步的相关词库,然后进行相关度计算和分析得到对查询改写词库的候选词进行过滤,保留相关度高的词语,这种方法可有效提高查询结果的准确度和召回度,有效的解决了搜索查询无结果或者返回有效结果少的难题。