
第7章分布滞后模型与自回归模型.pdf

qw****27


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10

9/10

10/10
亲,该文档总共81页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

第7章分布滞后模型与自回归模型.pdf
计量经济学第七章分布滞后模型与自回归模型1引子:货币政策效应的时滞货币供给的变化对经济影响很大,货币政策总是备受关注。货币政策的影响效应存在着时间上的滞后。在货币政策的传导过程中,货币扩张首先促使利率降低,或者一般价格水平的上升,这需要一段时间。这些因素对以GDP为代表的经济增长的影响,更是需要一段时间才能显示出来。只有经过一段时间以后,支出对利率的反应增强,投资、进出口和消费才会不断上升,货币政策才最终促使GDP增加。通常,货币扩张对GDP影响的最高点可能是在政策实施以后的一到两年间达到。2思考在现实经

计量经济学课件分布滞后模型与自回归模型.doc
第七章分布滞后模型与自回归模型第一节分布滞后模型与自回归模型的基本概念一、问题的提出1、滞后效应的出现。(1)在经济学分析中,研究消费函数,人们的消费行为不仅要受到当期收入的影响(绝对收入假设),还要受到前期收入的影响,甚至要受到前期消费的影响(相对收入假设)。(2)研究投资问题,由于投资周期的原因,本年度投资的形成,与上年度,甚至再上年度的投资形成有关。(3)运用经济政策调控宏观经济运行,经济政策的实施所产生的政策效果是一个逐步波及的扩散过程。用计量经济学模型研究这类问题,怎样度量变量的滞后影响?怎样估

分布滞后模型.ppt
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121
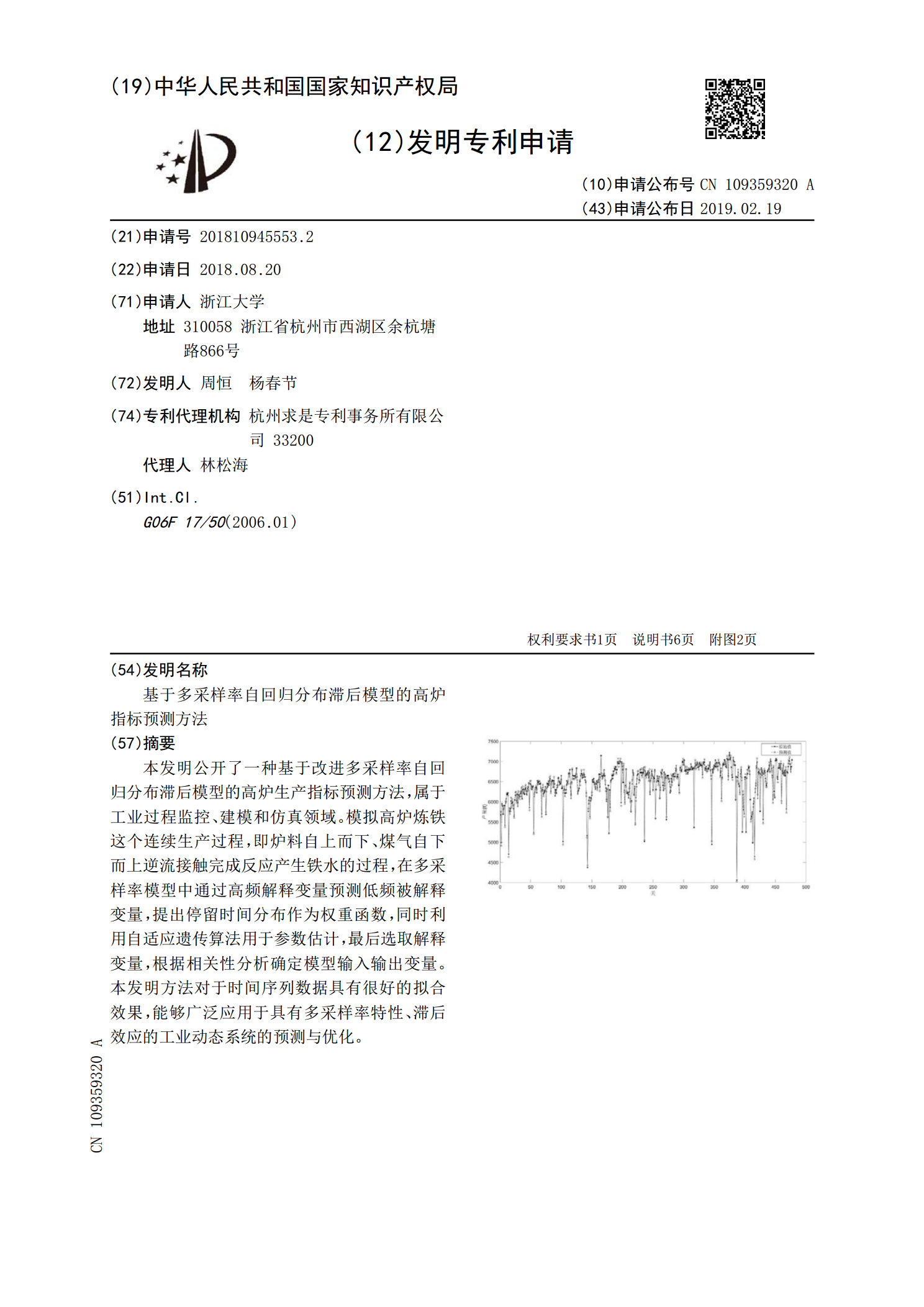
基于多采样率自回归分布滞后模型的高炉指标预测方法.pdf
本发明公开了一种基于改进多采样率自回归分布滞后模型的高炉生产指标预测方法,属于工业过程监控、建模和仿真领域。模拟高炉炼铁这个连续生产过程,即炉料自上而下、煤气自下而上逆流接触完成反应产生铁水的过程,在多采样率模型中通过高频解释变量预测低频被解释变量,提出停留时间分布作为权重函数,同时利用自适应遗传算法用于参数估计,最后选取解释变量,根据相关性分析确定模型输入输出变量。本发明方法对于时间序列数据具有很好的拟合效果,能够广泛应用于具有多采样率特性、滞后效应的工业动态系统的预测与优化。

分布滞后模型及其估计.pptx
第二节分布滞后模型及其估计2、多重共线性问题(三)滞后长度难以确定在大对数情况下,有限分布滞后模型的最大滞后长度S是未知的(而我们又没有充分的先验信息确定S=?)。需要预先对S进行估计,估计滞后长度的方法有很多,其中:Xt3)Λ型滞后结构:权数表现为“中间大,两头小”从而估计多项式的系数,再由多项式的系数与模型参数间的关系,最后得到分布滞后模型。即例)二、有限分布滞后模型的修正估计方法一般:(1)多项式次数的选择(原则)a)b)m在理论上应大于散点图的转向点c)用试探法。(2)滞后长度S的选择a)以的最大