
Hadoop云计算技术介绍.pdf

as****16


1/10

2/10

3/10

4/10

5/10

6/10

7/10
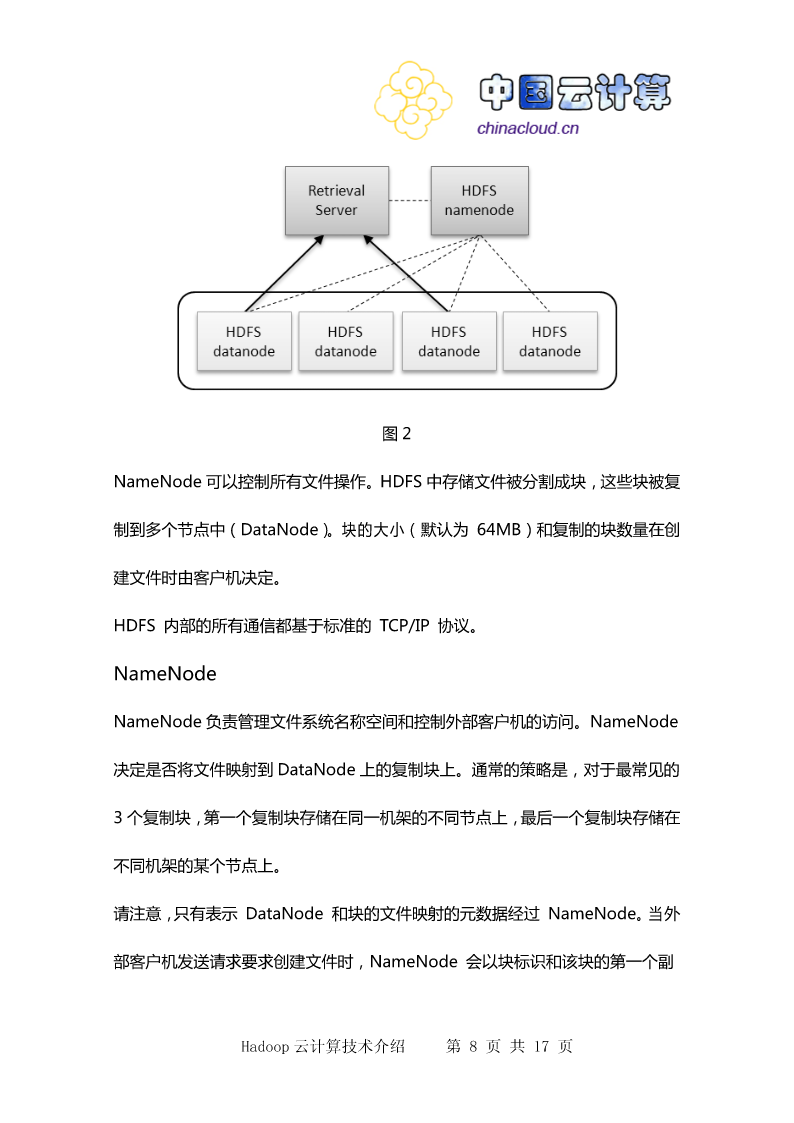
8/10

9/10
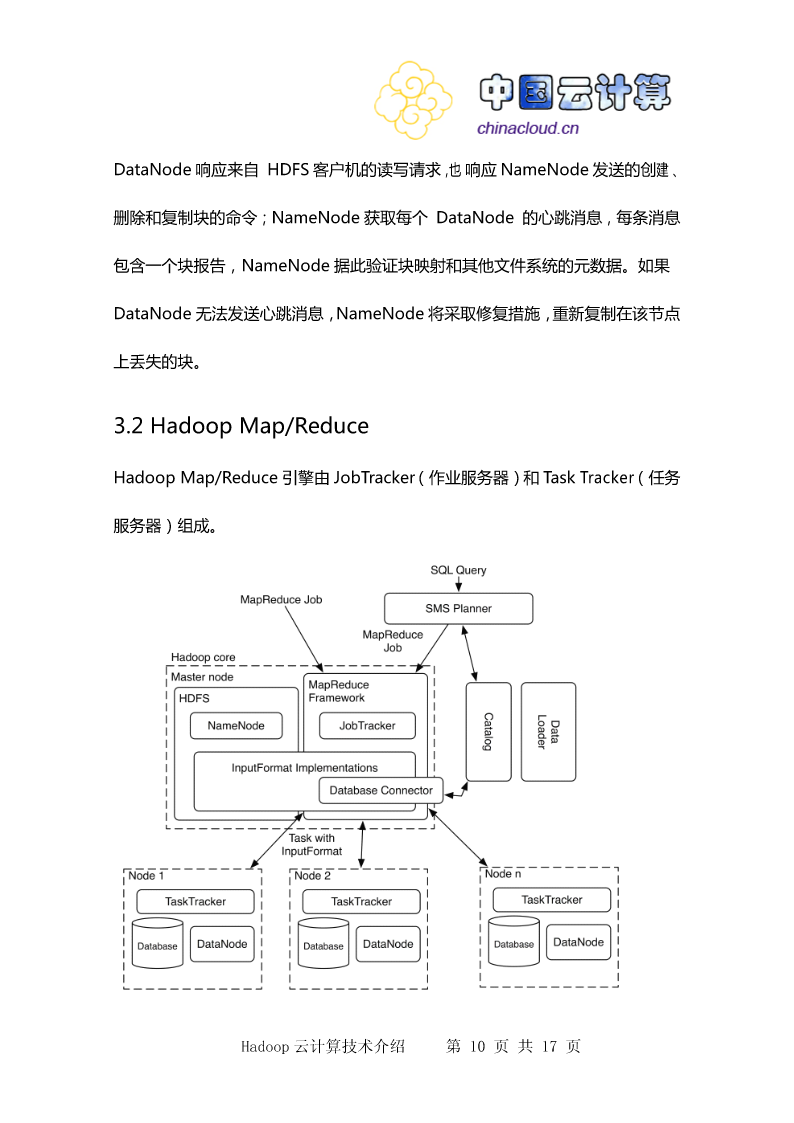
10/10
亲,该文档总共17页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

Hadoop云计算技术介绍.pdf
Hadoop云计算技术介绍作者:zbwd中国云计算论坛Email:xjtuzb@ieee.orgGTCRC@XJTU序言Hadoop是一个开源的分布式并行计算平台,它主要由MapReduce的算法执行和一个分布式的文件系统等两部分组成。Hadoop起源于DougCutting大牛领导开发的Nutch搜索引擎项目的子项目。现在是Apache软件基金会管理的开源项目。本文主要介绍Hadoop及相关技术,从Hadoop的起源开始讲述,主要涵盖了MapReduce算法思想,基本框架,运行流程和编程粒度等内容,以期

云计算技术介绍.pdf
云计算技术介绍云计算技术作为一种新型的计算模式,正在被越来越多的企业、组织、机构和个人采用。它不仅可以帮助用户实现网络化、高可靠性、高性能、可扩展性和灵活性的信息化服务,而且还可以节省大量的计算资源和成本,并且可以使用户的业务更加快速、灵活和安全。本文将介绍云计算技术的基本概念、特点、应用和发展趋势。一、云计算技术的基本概念云计算技术是一种按需提供计算资源和应用程序的技术,它基于虚拟化和分布式计算技术,将计算资源、存储资源、软件和服务等组成一种高度灵活的“云”计算平台,用户可以通过各种终端设备通过网络进行

云计算技术介绍.doc
课题组号04密级公开湖南科技职业学院软件学院信息检索与分析文档课题名称云计算技术介绍专业软件技术班级CMU3101学期第三学期指导教师胡胜丰课题组长刘锐课题组成员周东京龚涛易樟林彭有金二○一一年十月前言2006年谷歌推出了“Google101计划”,并正式提出“云”的概念和理论。随后亚马逊、微软、惠普、雅虎、英特尔、IBM等公司都宣布了自己的“云计划”,云安全、云存储、内部云、外部云、公共云、私有云……一堆让人眼花缭乱的概念在不断冲击人们的神经。那么到底什么是云计算技术呢?对云计算技术的产生、概念、原理、

云计算技术和产品介绍.ppt
Platform云计算技术和产品介绍Agenda关于PlatformComputing关于云计算的定义IT发展的最终目标20%电力模式IT的运维将是个三赢的局面降低生产厂商进入市场的门槛催生了运营商的市场最终用户是最大的受益者企业将IT资源置于集中调度管理WhatdoIbelieve?–BiggestOpp.3个层次的云计算服务数据中心体系很复杂,系统的维护和管理难度大IT成本高,资源占用多,配置峰值资源需求=浪费资源系统稳定性、可靠性低。人工服务为主,高成本、低满意度IT传统模式不能适应业务部署速度的需

NETAPP云计算技术及案例介绍.pdf