
Hadoop Mapreduce云计算 技术手册.pdf

qw****27


1/10

2/10

3/10

4/10

5/10

6/10

7/10
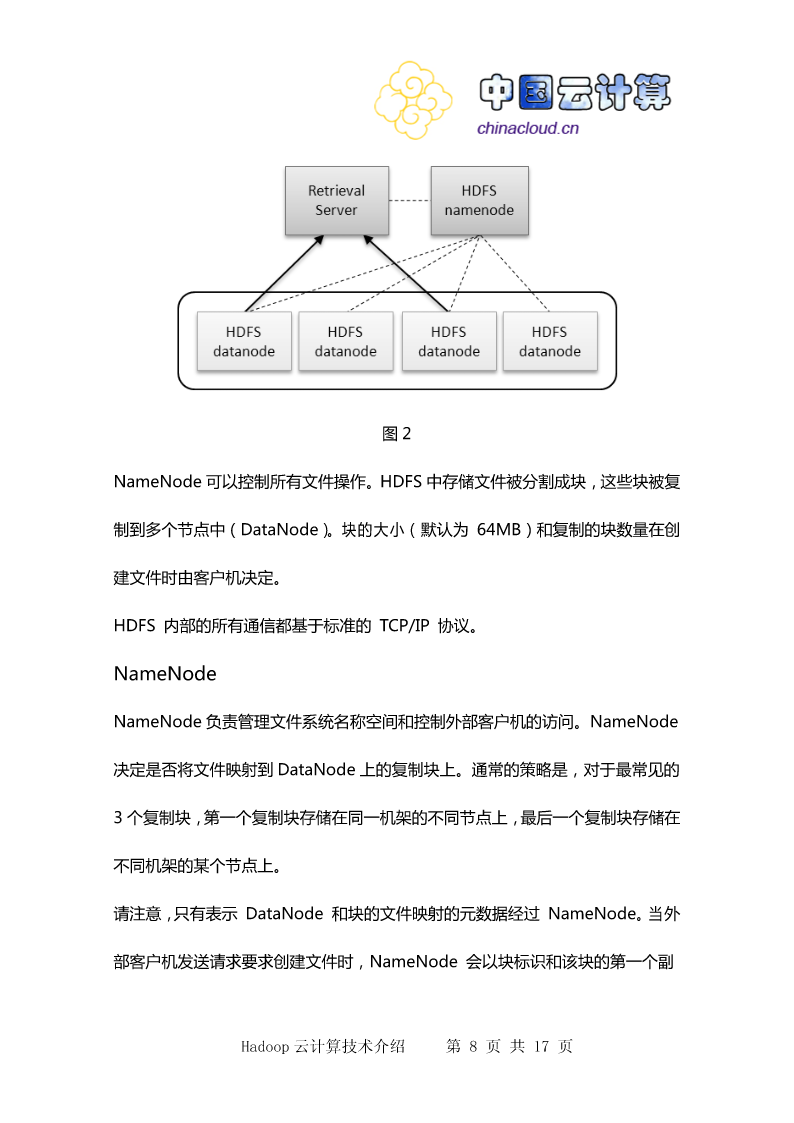
8/10
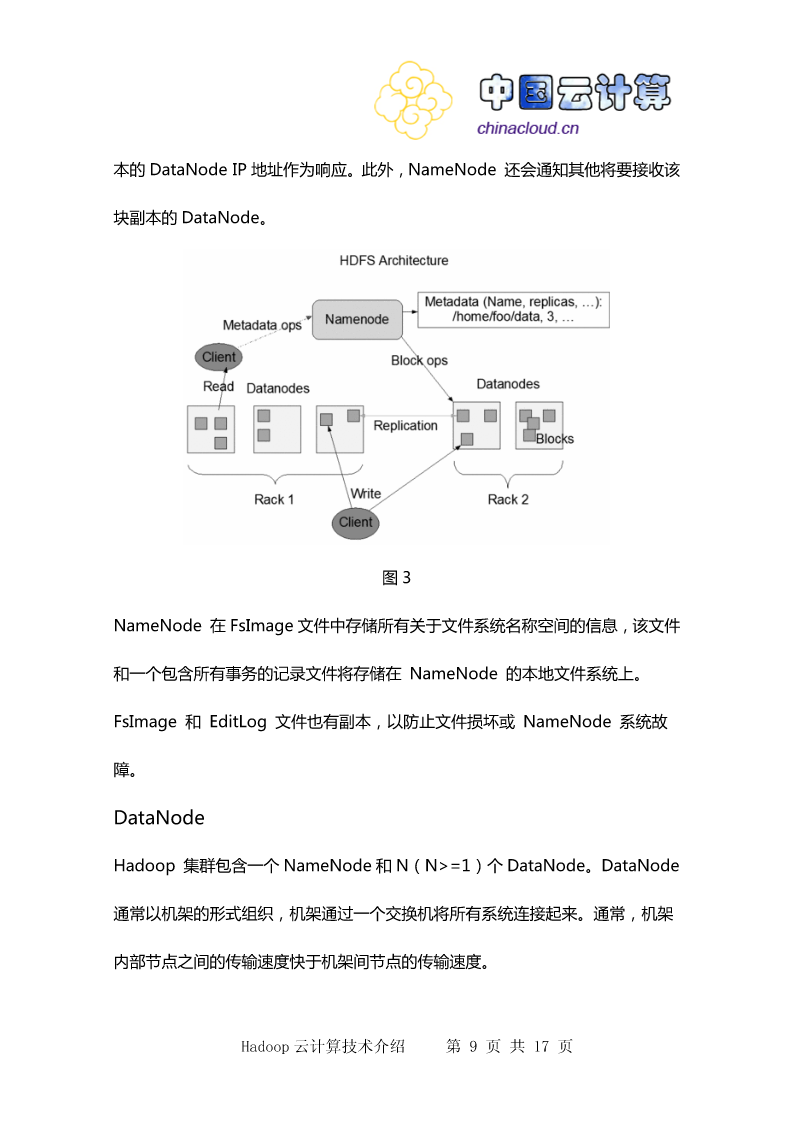
9/10

10/10
亲,该文档总共17页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

Hadoop Mapreduce云计算 技术手册.pdf
Hadoop云计算技术手册作者:zbwd中国云计算论坛Email:xjtuzb@ieee.orgGTCRC@XJTU序言Hadoop是一个开源的分布式并行计算平台,它主要由MapReduce的算法执行和一个分布式的文件系统等两部分组成。Hadoop起源于DougCutting大牛领导开发的Nutch搜索引擎项目的子项目。现在是Apache软件基金会管理的开源项目。本文主要介绍Hadoop及相关技术,从Hadoop的起源开始讲述,主要涵盖了MapReduce算法思想,基本框架,运行流程和编程粒度等内容,以期

近200篇云计算、虚拟化、Hadoop、MapReduce、HDFS等云计算相关资料整理下载.doc
[PPT]ÔƼÆËãʱ´úµÄÉç½»ÍøÂçƽ̨ºÍ¼¼Êõ[PPT]ººÖÜÔƼÆËã°×ƤÊé¼ò°æ[PDF]¡¶ÔƼÆËãÐÅÏ¢²úÒµÐÂÀ˳±¡·µÚһƪÔƼÆËã¸ÅÄî½â¶Á--·æÂõÕýµÂÔƼÆË㱨¸æ[PPT]3Gʱ´úµÄÔƼÆËã-ÁõÅô[PDF]¡¾°Ù¶ÈÊÀ½ç2011¡¿Ç±Áú½¾Ê×Ö¾ÔÚÁèÔÆ[PDF]HDFS2,Ò»ÖÖ·Ö²¼Ê½NNʵÏÖ[PDF]HadoopÔÚº£Á¿ÍøÒ³¼ìË÷ÖеÄÓ¦ÓÃÖ®ÎÒ¼

近200篇云计算、虚拟化、Hadoop、MapReduce、HDFS等云计算相关资料整理下载.doc
[PPT]ÔƼÆËãʱ´úµÄÉç½»ÍøÂçƽ̨ºÍ¼¼Êõ[PPT]ººÖÜÔƼÆËã°×ƤÊé¼ò°æ[PDF]¡¶ÔƼÆËãÐÅÏ¢²úÒµÐÂÀ˳±¡·µÚһƪÔƼÆËã¸ÅÄî½â¶Á--·æÂõÕýµÂÔƼÆË㱨¸æ[PPT]3Gʱ´úµÄÔƼÆËã-ÁõÅô[PDF]¡¾°Ù¶ÈÊÀ½ç2011¡¿Ç±Áú½¾Ê×Ö¾ÔÚÁèÔÆ[PDF]HDFS2,Ò»ÖÖ·Ö²¼Ê½NNʵÏÖ[PDF]HadoopÔÚº£Á¿ÍøÒ³¼ìË÷ÖеÄÓ¦ÓÃÖ®ÎÒ¼

近200篇云计算、虚拟化、Hadoop、MapReduce、HDFS等云计算相关资料整理下载.doc
[PPT]ÔƼÆËãʱ´úµÄÉç½»ÍøÂçƽ̨ºÍ¼¼Êõ[PPT]ººÖÜÔƼÆËã°×ƤÊé¼ò°æ[PDF]¡¶ÔƼÆËãÐÅÏ¢²úÒµÐÂÀ˳±¡·µÚһƪÔƼÆËã¸ÅÄî½â¶Á--·æÂõÕýµÂÔƼÆË㱨¸æ[PPT]3Gʱ´úµÄÔƼÆËã-ÁõÅô[PDF]¡¾°Ù¶ÈÊÀ½ç2011¡¿Ç±Áú½¾Ê×Ö¾ÔÚÁèÔÆ[PDF]HDFS2,Ò»ÖÖ·Ö²¼Ê½NNʵÏÖ[PDF]HadoopÔÚº£Á¿ÍøÒ³¼ìË÷ÖеÄÓ¦ÓÃÖ®ÎÒ¼

云计算核心技术MapReduce介绍.doc
MapReduce:超大机群上旳简朴数据处理摘要MapReduce是一种编程模型,和处理,产生大数据集旳有关实现.顾客指定一种map函数处理一种key/value对,从而产生中间旳key/value对集.然后再指定一种reduce函数合并所有旳具有相似中间key旳中间value.下面将列举许多可以用这个模型来表达旳现实世界旳工作.以这种方式写旳程序能自动旳在大规模旳一般机器上实现并行化.这个运行时系统关怀这些细节:分割输入数据,在机群上旳调度,机器旳错误处理,管理机器之间必要旳通信.这样就可以让那些没有并