
一种基于深度学习的实时性道路图像语义分割方法及系统.pdf

一只****ua


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10
10/10
亲,该文档总共12页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于深度学习的实时性道路图像语义分割方法及系统.pdf
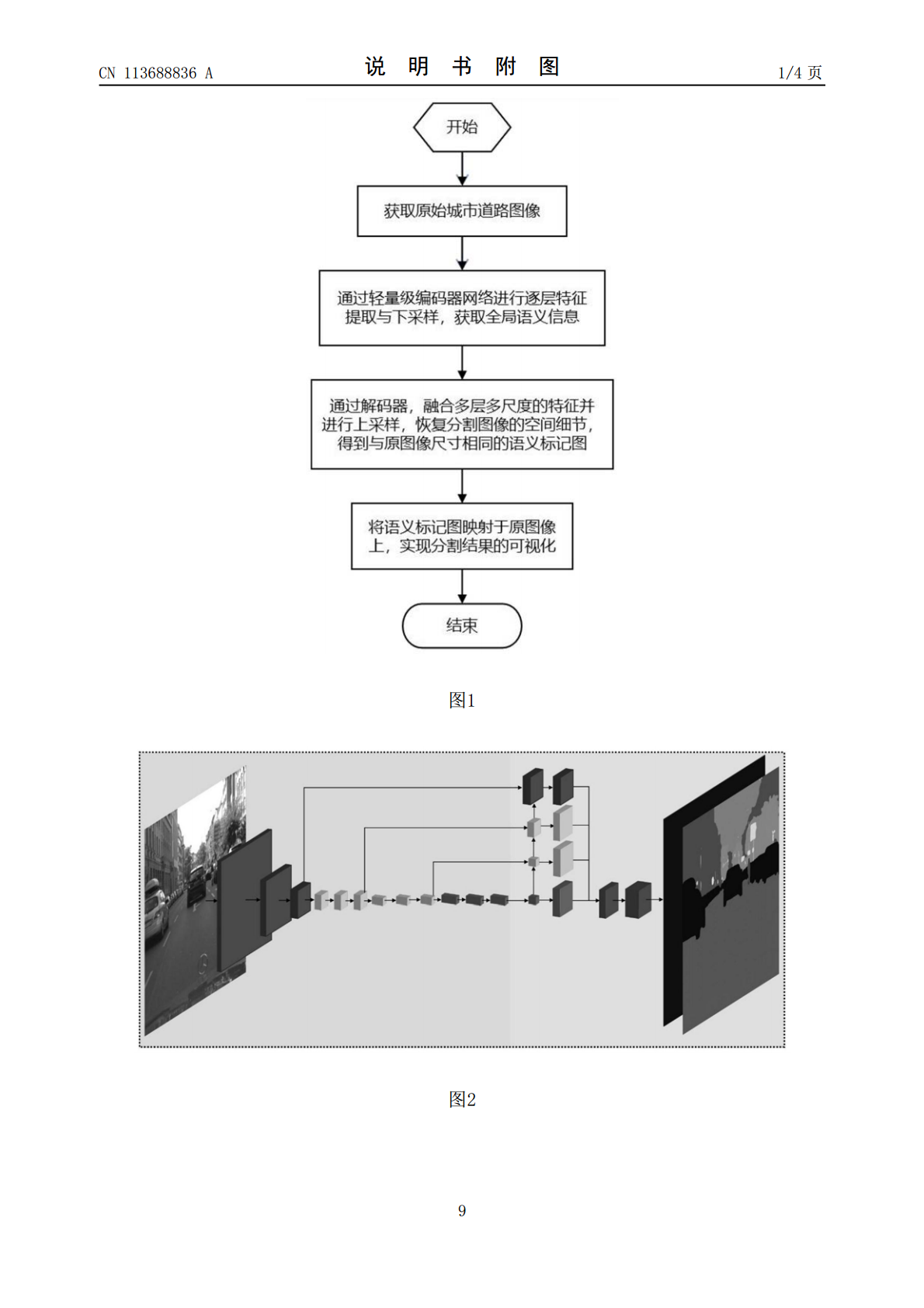
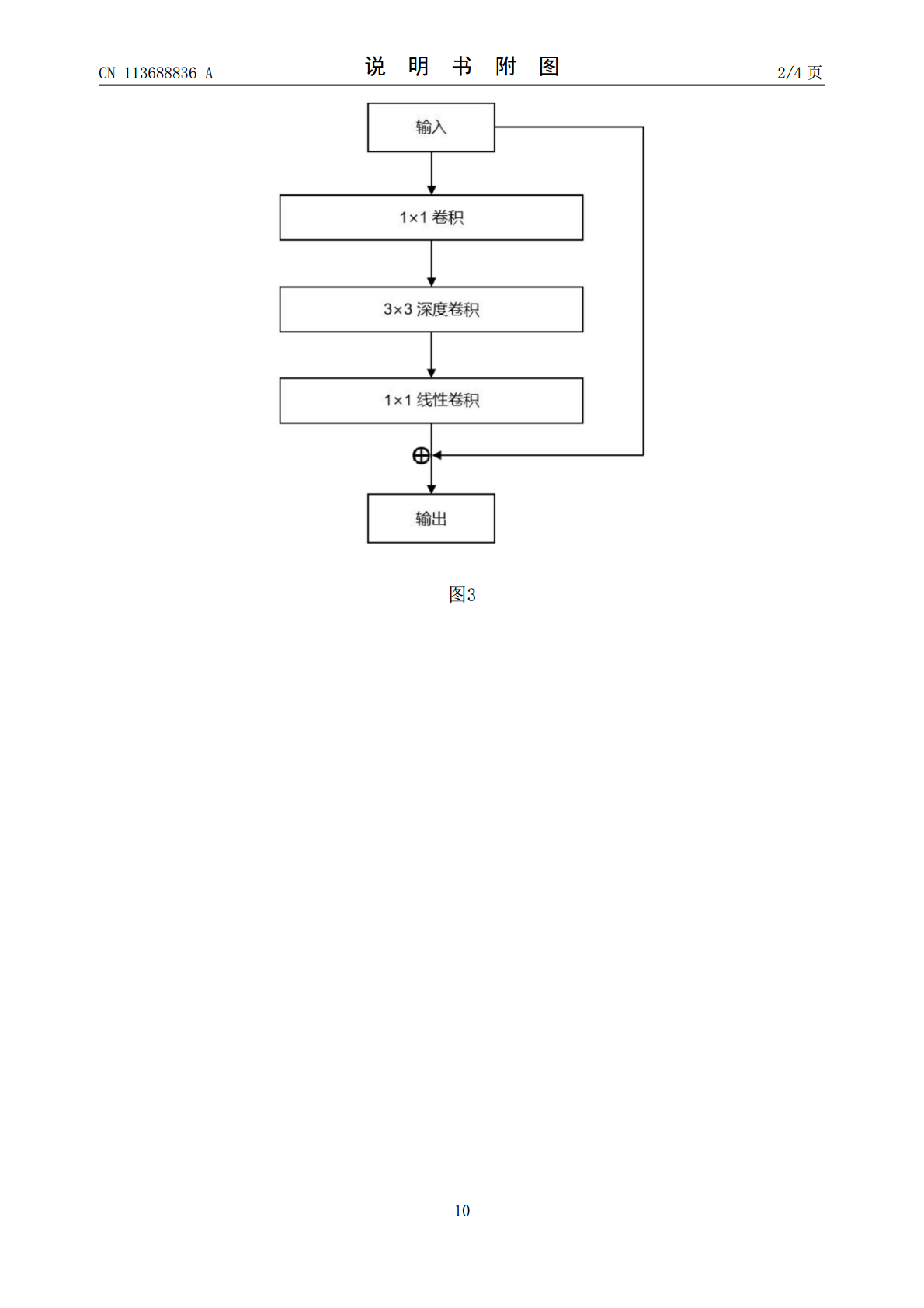
本发明涉及一种基于深度学习的实时性道路图像语义分割方法及系统,所述语义分割方法包括:建立基于编码器和解码器架构的神经网络模型;将测试的原始图像输入到编码器进行逐层特征提取与下采样,获取全局语义信息;解码器接收编码器的处理结果,融合多层多尺度的特征并进行上采样,恢复分割图像的空间细节得到与原图像尺寸相同的语义标记;将语义标记图映射到原始图像上,实现分割结果的可视化。本发明通过轻量级的逆残差瓶颈模块和深度可分离卷积,充分挖掘网络的多尺度特征,在保证了分割准确率的条件下大大减少了网络的计算规模,实时性效果好,充

一种基于深度学习的遥感图像语义分割方法.pdf
本发明公开了一种基于深度学习的遥感图像语义分割方法,包括以下步骤:获取数据集;对数据进行增广;构建segnet、unet网络模型;修改segnet网络,在编码器中的前两个阶段增加两个空洞空间金字塔池化(ASPP)模块,有效提取多尺度特征,保留空间位置信息,完成两个ASPP模块的训练后,在解码器中进行相应的特征融合;载入数据进行模型训练、预测;模型融合,将使用三个模型得到的预测图的每个像素点进行投票;对预测结果做可视化处理。本发明对segnet网络进行改进,增强了特征提取能力并有效的融合了网络的上下文信息,

基于深度学习的图像语义分割方法综述.docx
基于深度学习的图像语义分割方法综述摘要:随着深度学习技术的发展,图像语义分割已经成为目前计算机视觉领域的一个热点方向。本文对图像语义分割的基本概念、发展历程和常用数据集进行了介绍。针对深度学习在图像语义分割中的应用,本文详细阐述了传统的卷积神经网络(CNN)和全卷积网络(FCN)的基本原理以及针对语义分割任务的优化策略。此外,本文还介绍了一些基于深度学习的语义分割模型,如U-Net,SegNet,DeepLab等,并对它们进行了比较。最后,本文总结了目前深度学习在图像语义分割中面临的挑战和未来发展方向。关

基于深度学习的道路图像语义分割算法研究.docx
基于深度学习的道路图像语义分割算法研究基于深度学习的道路图像语义分割算法研究摘要:深度学习在计算机视觉领域取得了重要的突破,其中语义分割是一项重要的任务。本文针对道路图像语义分割问题,提出了基于深度学习的算法研究。首先介绍了语义分割的定义和意义,然后对深度学习在语义分割中的应用进行了综述,包括常用的网络架构和数据集。接着详细介绍了本文提出的算法,包括网络结构和训练方法。通过实验验证,本文的算法在道路图像语义分割任务中取得了较好的效果。1.引言道路图像语义分割是计算机视觉领域的一个重要任务,它可以将一幅道路

一种基于分割网络优化的图像语义分割方法及系统.pdf
本发明实施例提供一种基于分割网络优化的图像语义分割方法及系统,其中方法包括:确定待语义分割的图像;将所述图像输入至分割网络优化模型中,得到所述分割网络优化模型输出的图像语义分割结果;其中,所述分割网络优化模型是基于样本图像以及对应的像素类别标注进行多阶段损失函数训练后得到的,所述像素类别标注是预先确定的。本发明解决了现有传统的语义分割模型的训练方法不能很好地勾勒出分割部分的边界,对超声图像进行分割时经常出现不圆滑的边界和锯齿状边界的现象问题。