
一种基于多模型融合Stacking算法的煤质熔点预测方法.pdf

佳宁****么啦


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10
10/10
亲,该文档总共13页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于多模型融合Stacking算法的煤质熔点预测方法.pdf
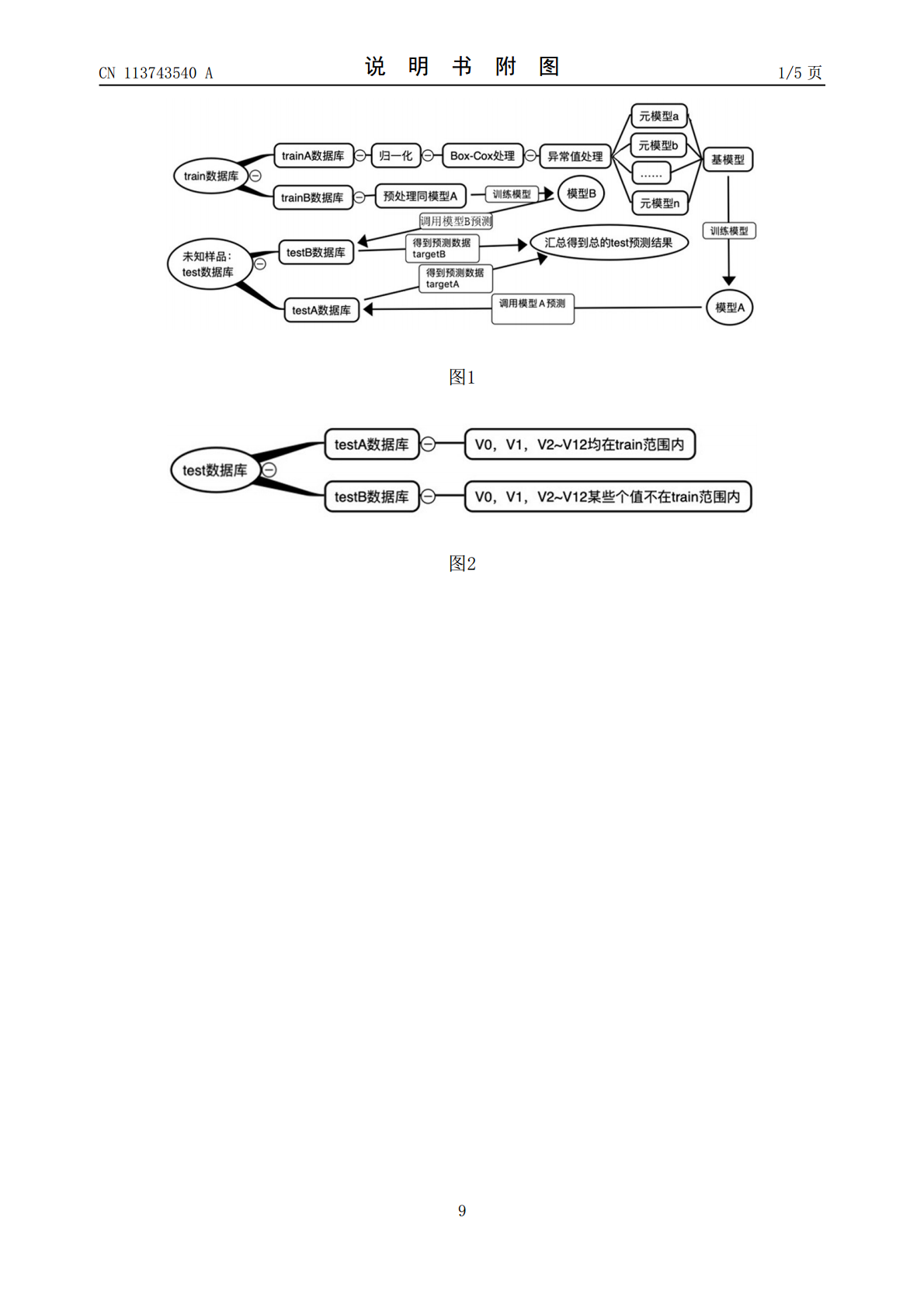
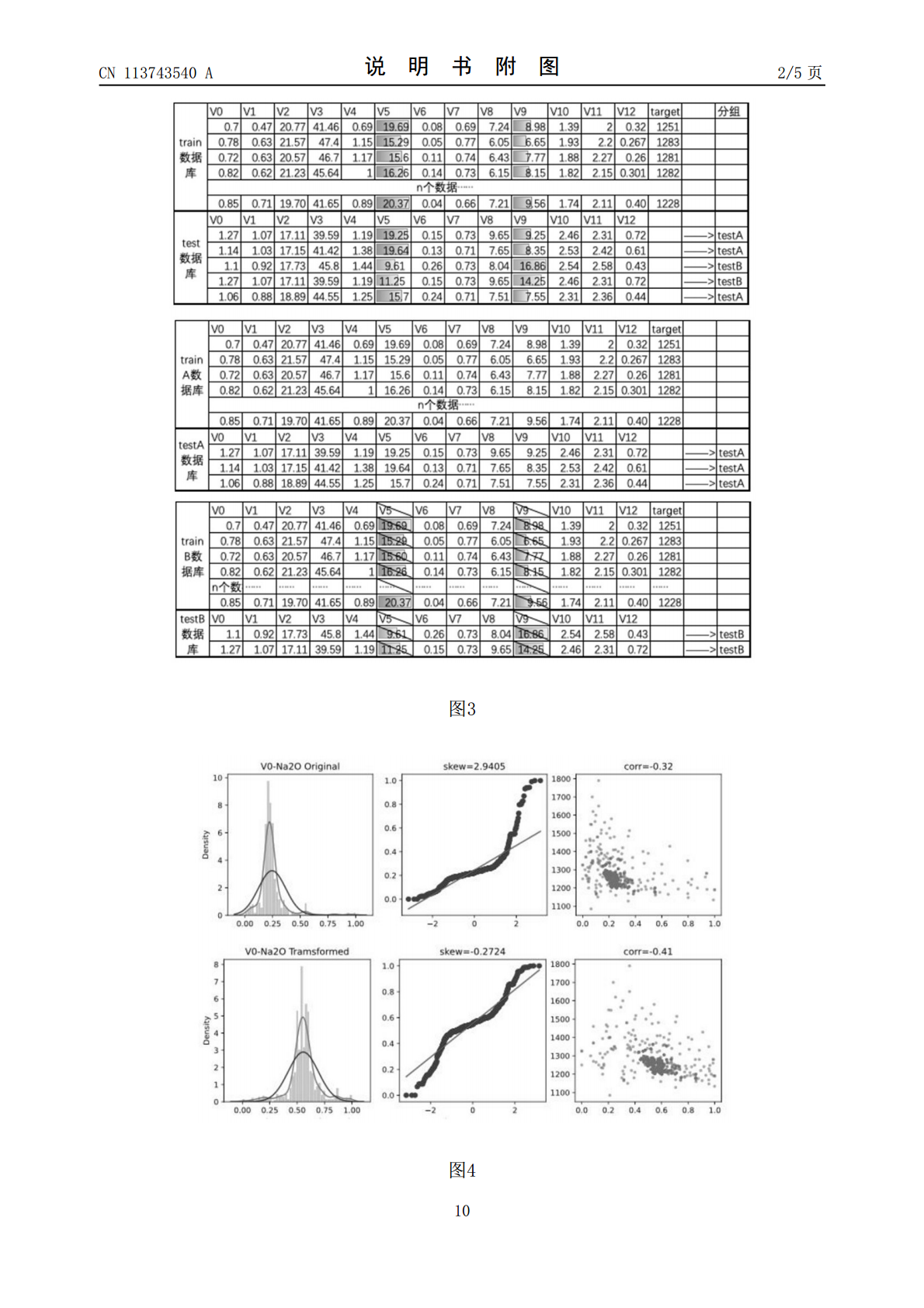
本发明公开了一种基于多模型融合Stacking算法的煤质熔点预测方法,使用机器算法预测数据,首先确定目标变量及特征变量,将test数据库拆分成testA数据库及testB数据库,构建其对应的trainA数据库及trainB数据库;对数据进行最大最小归一化处理、进行Box‑Cox变换、采用“3σ准则”剔除异常值等处理;选择基模型及元模型,基模型分别进行单独训练,元模型进行拟合训练,得到最终模型A,模型A预测testA数据库的灰熔点。本发明的煤质熔点预测方法,解决了耗时、耗能、耗力的弊端,能对大规模样品进行预

基于Stacking多模型融合的极端天气短期风电功率预测方法.docx
基于Stacking多模型融合的极端天气短期风电功率预测方法1.内容概述本文档主要介绍了一种基于Stacking多模型融合的极端天气短期风电功率预测方法。在当前全球气候变化和能源危机的背景下,风能作为一种清洁、可再生的能源,其开发利用具有重要的战略意义。风能的受到多种因素的影响,如气象条件、地理环境等,这些因素之间的相互作用使得风能预测具有很大的不确定性。研究一种有效的风能预测方法具有重要的现实意义。本研究采用了Stacking多模型融合的方法,通过对多个模型进行训练和预测,最终得到一个综合性能较好的预测

基于Stacking模型融合的失压故障识别算法.docx
基于Stacking模型融合的失压故障识别算法基于Stacking模型融合的失压故障识别算法摘要:失压故障是电力系统中常见的故障类型之一,对电力系统的安全运行产生了很大的影响。因此,准确识别和定位失压故障对于电力系统的稳定运行至关重要。本论文提出了一种基于Stacking模型融合的失压故障识别算法,该算法通过将多个基础分类模型进行组合,提高了故障识别的准确性和鲁棒性。实验结果表明,该算法在失压故障识别方面具有优异的性能。关键词:失压故障;识别算法;Stacking模型融合1.引言电力系统是现代社会不可或缺

一种基于Stacking模型融合的楼宇用电量预测方法和系统.pdf
本发明公开了一种基于Stacking模型融合的楼宇用电量预测方法和系统,属于楼宇用电量预测领域。本发明采用Stacking模型融合算法集成多种回归模型,构建用电量Stacking集成模型,集成了多种模型的优势,减少了预测偏差;针对用电量不稳的楼宇,利用了历史用电量、温度、风力、湿度、时间信息等多种影响因素,训练用电量Stacking集成模型,提高了预测的精准度,有利于楼宇的管理者对大楼能耗进行有效的管控,避免出现耗电量与预估电量相差太大的情况,在参与电力市场交易时合理预估和购买,使楼宇管理者有效控制电费支

基于Stacking算法的碳排放预测模型的构建和预测方法及介质.pdf
本发明涉及一种基于Stacking算法的碳排放预测模型的构建和预测方法及介质,步骤如下:获取电力数据以及对应的碳排放数据样本,形成数据集;预处理数据集,将数据集划分为训练集和测试集;使用XGBoost算法分析影响碳排放的特征,得到目标特征;构建碳排放预测模型,碳排放预测模型包括元模型和多个基模型;使用Stacking算法将元模型和多个基模型融合,基于训练集和目标特征对模型进行训练;根据各基模型输出的碳排放预测结果误差占比,调整各基模型输入到元模型的预测结果权重分配,得到优化的碳排放预测模型。本发明通过选用