
一种基于BERT采样的文本通用触发器生成系统和方法.pdf

是你****嘉嘉


1/10

2/10

3/10

4/10

5/10

6/10

7/10

8/10
9/10

10/10
亲,该文档总共11页,到这已经超出免费预览范围,如果喜欢就直接下载吧~
相关资料

一种基于BERT采样的文本通用触发器生成系统和方法.pdf
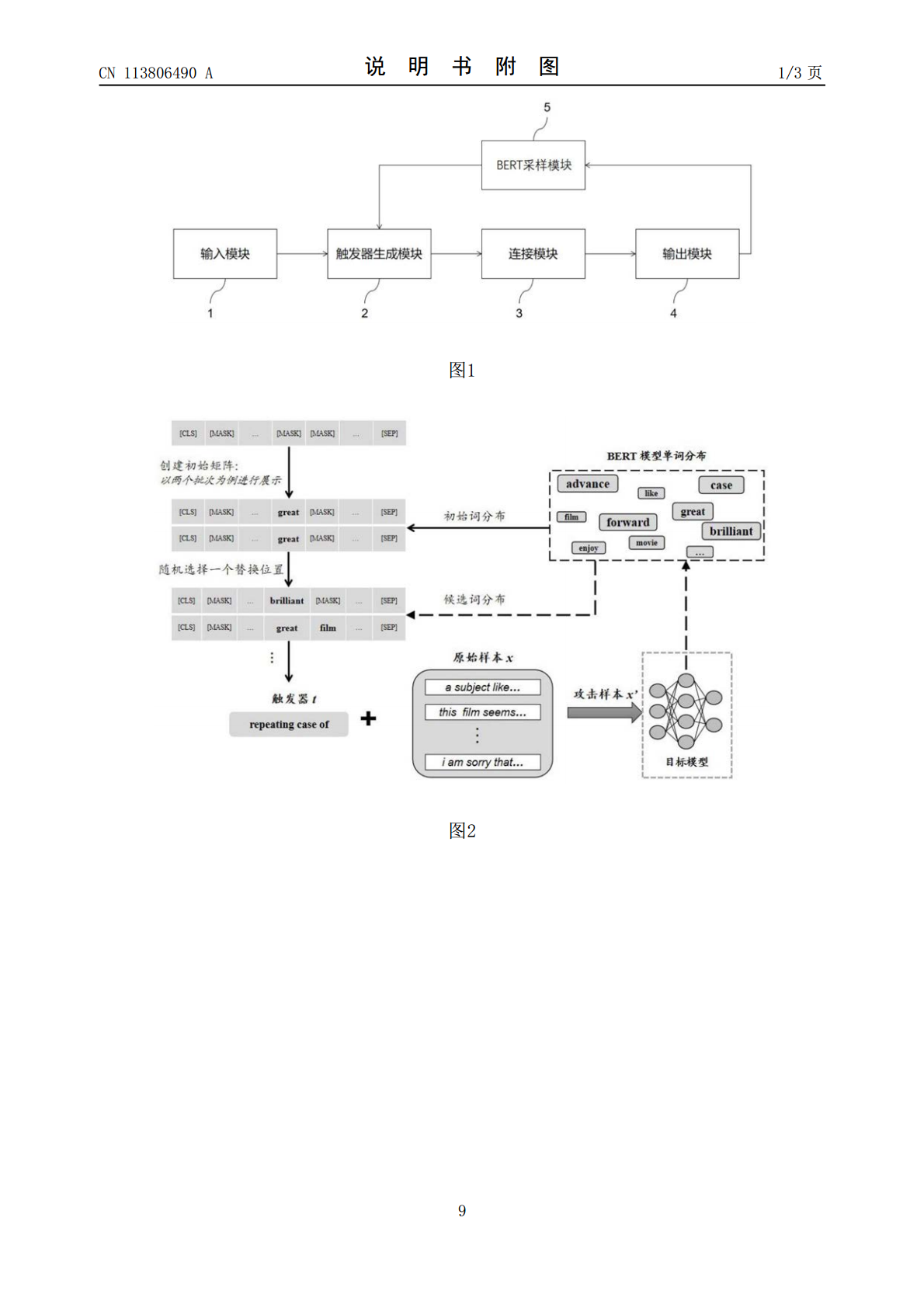
本发明公开了一种基于BERT采样的文本通用触发器生成系统和方法,设置初始单词序列长度m及批次大小n,将初始单词序列复制n份得到n个单词序列,在其上随机选择第i个位置,将初始单词序列输入到BERT语言模型中,获得第i个位置单词的概率分布;采样一个单词y,将第i个位置的原始掩码符号替换为单词y,得到一批初始触发词序列,并连接到数据测试集的所有样本上,输入到目标模型进行测试;将测试结果传输到BERT采样模块,并调整单词分布概率,然后采样获得候选单词;继续将候选单词在除第i个位置外的其他位置上进行替换,直到目标模

一种基于BERT的中文ASR输出文本修复方法及系统.pdf
本发明提出了一种基于BERT的中文ASR文本修复方法及系统,该系统包含:中文标点符号预测模型和中文纠错模型。中文标点预测模型基于BERT进行了两方面的改进:使用RoBERTa模型替换基础BERT模型,通过改变预训练任务中的掩码策略来提高模型的效率;通过提取字音和字形两个嵌入给模型提供更多的中文额外信息。通过这两个方面的改动提出了目前较为完整的中文标点符号预测模型。中文纠错模型使用PLOME预训练模型,该模型的特点也是结合了中文额外特征来提高模型对中文的理解能力。通过简单的结合,本发明得到了一个端到端的中文

基于采样的颜色信息生成和传输图像序列的系统和方法.pdf
在一个实施例中,用于从稀疏数据生成完整帧的方法可以分别访问与帧的序列相关联的样本数据集。每个样本数据集可以包括相关联的帧的不完整像素信息。该系统可以使用第一机器学习模型基于样本数据集来生成帧序列,每个帧具有完整像素信息。第一机器学习模型被配置为保留与生成的帧相关联的时空表示。然后,该系统可以访问下一个样本数据集,该下一个样本数据集包括帧序列之后的下一个帧的不完整像素信息。该系统可以使用第一机器学习模型,基于下一个样本数据集生成下一个帧。该下一个帧具有完整像素信息,该完整像素信息包括该下一个样本数据集的不完

基于BERT和双分支网络的胃镜文本分类系统.pdf
本发明属于自然语言处理领域,提供一种基于BERT和双分支网络的胃镜文本分类系统,获取待分类的胃镜文本数据;从待分类的胃镜文本数据中分离镜下所见文本和病理诊断文本;对镜下所见文本和病理诊断文本分别进行切分,获得由若干文本单元组成的集合,即文本单元集合;在所述文本单元集合内的每个文本单元前插入[CLS]标记,每个文本单元后插入[SEP]标记,并将它们重新组合成一段连续的文本;使用预训练好的BERT模型提取每个[CLS]字符对应的文本特征向量,得到文本单元的特征向量集合;基于文本单元的特征向量集合,利用预先训练

一种基于领域BERT模型的服务文本分类方法.pdf
本发明属于网络服务文本技术领域,具体地涉及一种基于领域BERT模型的服务文本分类方法。包括:步骤1:采用TF?IDF算法从服务文本语料中提取领域词汇;步骤2:在步骤1的基础上,建立BERT?BiLSTM模型,将步骤1提取的领域词汇输入进BERT?BiLSTM模型的BERT词表后,将服务文本语料输入BERT?BiLSTM模型进行训练,实现服务文本分类;步骤3:根据步骤2的服务文本语料特性和分类结果,选择最佳的损失函数以均衡数据集。为了证明所提出方法的有效性,在互联网获取的真实数据集上进行了大量对比试验,其实