
一种跨模态视觉与文本信息匹配方法和装置.pdf

一条****发啊


1/7

2/7

3/7

4/7

5/7

6/7
7/7
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种跨模态视觉与文本信息匹配方法和装置.pdf
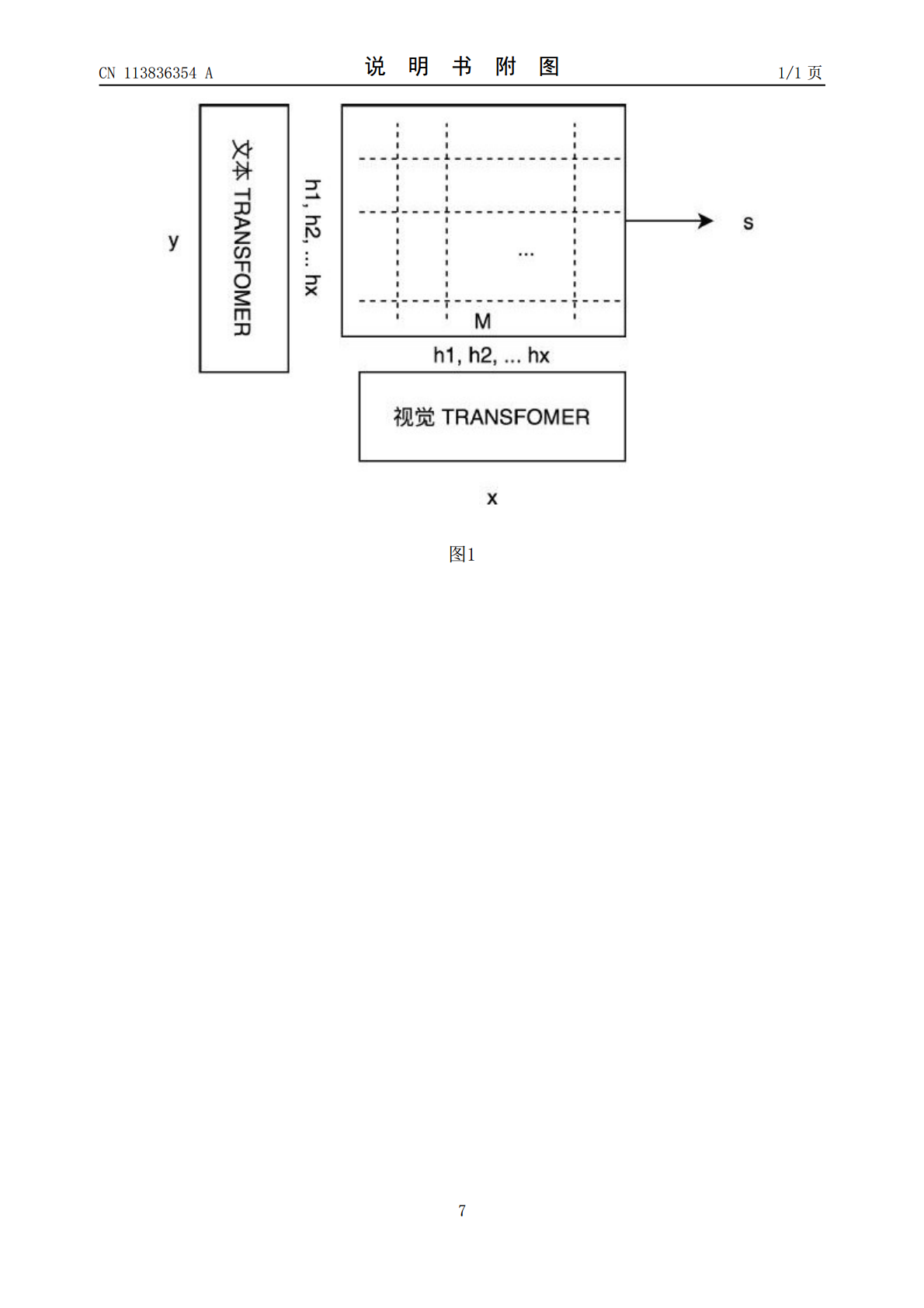
本发明公开了一种跨模态视觉与文本信息匹配方法和装置,其方法包括以下步骤:通过成熟的目标识别系统检测出图片中重要物体场景的区块,区块总数量为X;将这些区块的视觉向量信息输入到视觉编码器中,从而构建这些区块之间的关系和综合信息,获得包含上下文的视觉向量信息h

视觉--语言跨模态匹配研究.docx
视觉--语言跨模态匹配研究Title:Cross-ModalMatchinginVisual-LanguageDomainAbstract:Cross-modalmatchingbetweenvisualandlinguisticmodalitieshasbecomeapopularresearchtopicduetoitspotentialapplicationsinvariousfields,suchasimagecaptioning,visualquestionanswering,andcross-

模型训练方法、跨模态表征方法、无监督图像文本匹配方法及装置.pdf
本发明的目的是提供一种模型训练方法、跨模态表征方法、无监督图像文本匹配方法及装置,所述方法包括:计算训练文档中图片与句子的两两相似度值;基于所述相似度值,确定正样本对集和负样本对集;其中,所述正样本对集中有预设数量的正样本对;所述负样本对集中有预设数量的负样本对;所述正样本对集和所述负样本对集用于进一步训练所述模型,直至预设数量的所述正样本对的平均相似度值大于预设数量的所述负样本对的平均相似度值,且两者差值符合预设条件。上述实施方式可以减小采样的偏差,以更好的训练模型来对图片和句子进行匹配。

基于跨模态置信度感知的图像文本匹配方法.pdf
本发明涉及跨模态检索领域,公开了一种基于跨模态置信度感知的图像文本匹配方法,以待匹配文本为桥梁,参考图像‑文本的全局语义,来衡量图像区域在待匹配文本中被描述的可信程度。并且,本发明在聚合区域‑单词匹配对的局部对齐信息以得到图文整体相关性时,根据匹配置信度来过滤掉与全局图像‑文本语义不一致的局部区域‑单词匹配对,更准确地度量的图文相关性,提升跨模态检索性能。

从视觉到文本的跨模态序列生成方法研究的开题报告.docx
从视觉到文本的跨模态序列生成方法研究的开题报告一、研究背景与意义跨模态序列生成是视觉和文本信息之间的一种重要交互方式。它可以将多模态的信息进行融合,得到更加全面、丰富的数据。例如,图像和文本的结合可以帮助人们更好地理解图像信息,提升图像检索和分类的准确性。而在自然语言生成任务中,文本生成模型往往需要结合图像、视频等多模态信息,才能产生更加准确、自然的文本结果。当前,传统的跨模态序列生成方法主要基于对齐的模型。这些方法会首先对多模态数据进行对齐处理,然后在统一的特征空间中进行序列生成。然而,这些方法存在的问