
一种未标注数据的半监督命名实体识别的方法.pdf

一条****丹淑


1/7

2/7

3/7

4/7

5/7

6/7
7/7
在线预览结束,喜欢就下载吧,查找使用更方便
相关资料

一种未标注数据的半监督命名实体识别的方法.pdf
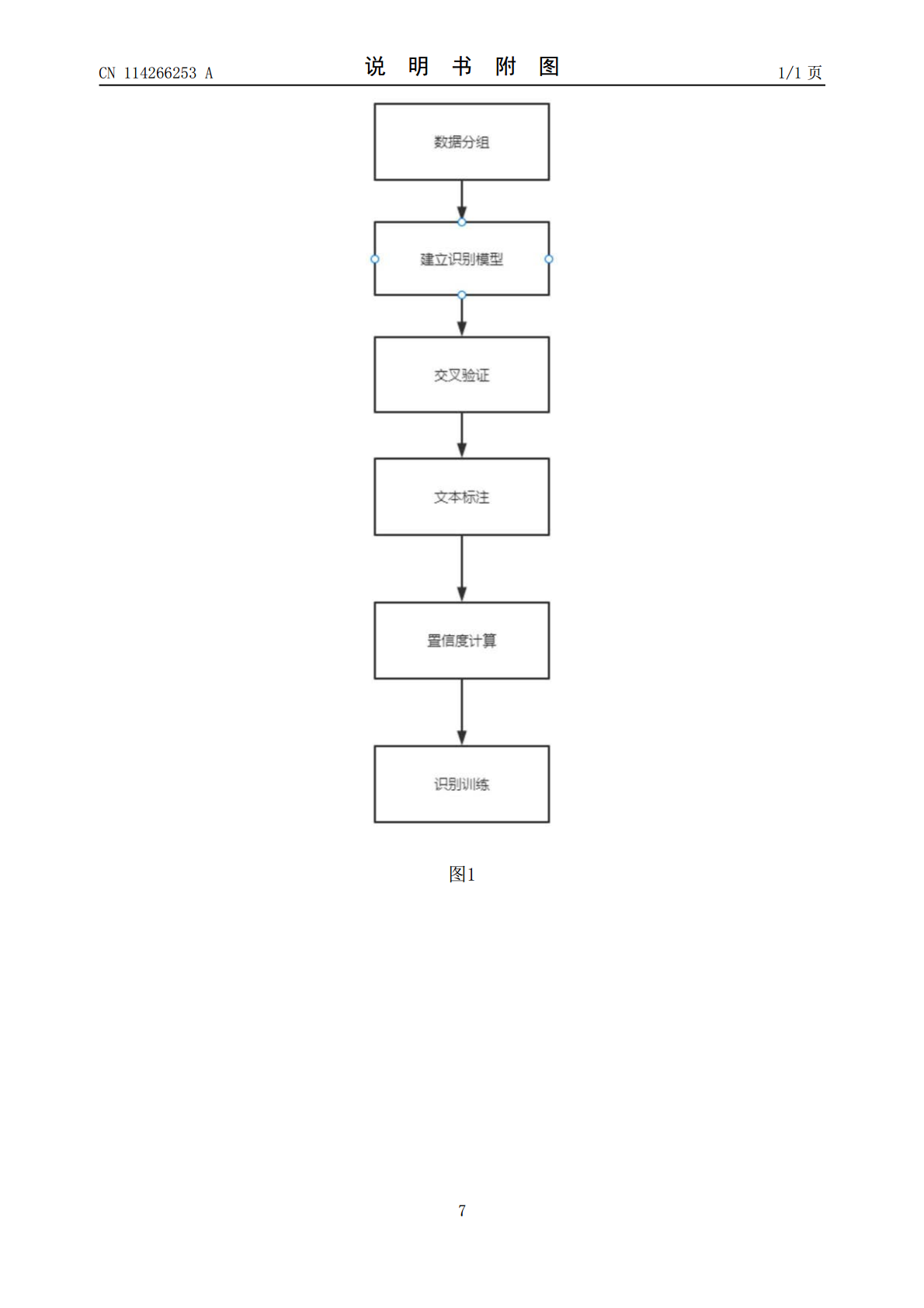
本发明公开了一种未标注数据的半监督命名实体识别的方法,包括:数据分组、建立识别模型、交叉验证、文本标注、置信度计算和识别训练等步骤,综合多种常用模型的优势,最大程度的降低训练集中噪声数据的干扰,同时本方法并不用训练基于二分类的打分器。目前市面上少量标注文本命名识别算法无法充分挖掘出大量未标注的文本中的信息和降低相应由于少量标注文本带来噪声。该方法还可以通过调整置信度α,来调整最后模型的召回率和精度,在不同场景下使用不同的置信度来满足不同场景下对召回率和精度的不同要求。

半监督的命名实体识别.docx
半监督的命名实体识别半监督学习是机器学习中的重要分支之一。它是指在一定的数据集上,利用有标签数据和无标签数据进行训练,从而达到提高模型性能、减少标注量的目的。在命名实体识别问题中,半监督学习也被广泛应用。为了更好地探讨半监督学习在命名实体识别中的应用,本文将分为三个部分来进行讨论。一、命名实体识别的基本思路在自然语言处理领域,命名实体识别指的是从文本中识别出具有特定意义的实体。例如,在一篇新闻报道中,命名实体可以指涉人、地点、组织机构等实体。命名实体识别是解决一些具体应用的关键问题,比如信息抽取、机器翻译

一种基于命名实体识别的中标数据提取方法.pdf
本发明公开了一种基于命名实体识别的中标数据提取方法,从中标公告网页的HTML解析成文本,到文本中提取所需的关键信息,再到提取结果校对,最后校对结果再反哺到提取上,形成一个闭环流程;在提取信息中结合了命名实体识别与规则筛选,提高中标机构的提取率,且针对不同的数据源,所需的改动较少;该方法在把难以处理的表格数据转为易于识别的普通文本数据的同时,尽可能保留了与信息提取相关的各个单元格间的关系,这是后续中标机构、中标标的与中标金额得以高准确率提取的主要因素。该方法可操作性强,随着处理过的数据量的增长,最终会得到较

一种命名实体识别的方法和装置.pdf
本申请提供一种命名实体识别的方法和装置,所述方法包括:接收原始文本,分离所述原始文本获取文本单元;根据所述文本单元确定文本单元表示向量;获取所述文本单元对应的拆分特征,根据所述文本单元的拆分特征确定所述原始文本的特征表示向量;根据所述原始文本的特征表示向量和所述文本单元表示向量确定所述原始文本中的命名实体。以文本单元对应的拆分特征作为最小元素进行处理,这样可以最大程度保留文本单元作为象形字或形声字的内在特征,保留文本单元间内在的特征,提高命名实体识别的准确度。

一种半监督式命名实体识别方法、系统及电子设备.pdf
本发明提供一种半监督式命名实体识别方法、系统及电子设备,对文本数据进行资料格式转化、文本分词、词向量处理以及命名实体信息标注处理;对处理后的文本数据进行训练;基于命名实体识别模型对待识别数据集进行标注,得到带有弱标注的待识别数据集,随后选择弱标注的待识别数据集的子集与初始训练集合作为新的本轮训练集进行重复训练直至命名实体识别模型收敛,命名实体识别模型在多次重复训练过程获取待识别词汇数据集的特征信息,提升对特征信息的识别性能。本发明可以减少大量文本数据标注的工作量,同时联合训练可以提升命名实体识别模型的泛化